
Practice Free DP-600 Exam Online Questions
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a semantic model named Model1.
You discover that the following query performs slowly against Model1.

You need to reduce the execution time of the query.
Solution: You replace line 4 by using the following code:
NOT (CALCULATE (COUNTROWS (‘Order Item’)) < 0)
Does this meet the goal?
- A . Yes
- B . No
B
Explanation:
Correct: You replace line 4 by using the following code:
NOT ISEMPTY (CALCULATETABLE (‘Order Item ‘))
Just check if it is empty or not.
Note: ISEMPTY
Checks if a table is empty.
Syntax
ISEMPTY(<table_expression>)
Parameters
table_expression – A table reference or a DAX expression that returns a table.
Return value – True if the table is empty (has no rows), if else, False.
Incorrect:
* CALCULATE (COUNTROWS (‘Order Item’)) >= 0
* ISEMPTY (RELATEDTABLE (‘Order Item’))
* NOT (CALCULATE (COUNTROWS (‘Order Item’)) < 0)
Reference: https://learn.microsoft.com/en-us/dax/isempty-function-dax
HOTSPOT
You have a Fabric tenant that contains three users named User1, User2, and User3. The tenant contains a security group named Group1. User1 and User3 are members of Group1.
The tenant contains the workspaces shown in the following table.

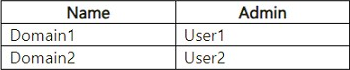
The tenant contains the domains shown in the following table.
User1 creates a new workspace named Workspace3.
You assign Domain1 as the default domain of Group1.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


Explanation:
User2 is assigned the Contributor role for Workspace3 – No
User2 is not a member of Group1, and Workspace3 is created by User1. Since Workspace3 is assigned to Domain1 (default domain of Group1), only members of Group1 will have permissions based on their role in the domain. User2 is not part of Group1, so they have no role in Workspace3.
User3 is assigned the Viewer role for Workspace3 – No
User3 is a member of Group1, and the default domain (Domain1) is assigned to Group1. However, there is no indication that User3 has been explicitly granted the Viewer role in Workspace3. If permissions were inherited, User3 would have the default role for Domain1, but the problem does not specify this explicitly, so we assume no Viewer role is assigned.
User3 is assigned the Contributor role for Workspace1 – No
Workspace1 is explicitly assigned to User1 as the admin. There is no indication that User3 has any permissions for Workspace1. Being a member of Group1 does not grant automatic Contributor access to a workspace unless explicitly configured.
You have a Fabric tenant that contains a warehouse.
A user discovers that a report that usually takes two minutes to render has been running for 45 minutes and has still not rendered.
You need to identify what is preventing the report query from completing.
Which dynamic management view (DMV) should you use?
- A . sys.dm_exec_requests
- B . sys.dm_exec_sessions
- C . sys.dm_exec_connections
- D . sys.dm_pdw_exec_requests
DRAG DROP
You are implementing two dimension tables named Customers and Products in a Fabric warehouse.
You need to use slowly changing dimension (SCD) to manage the versioning of data.
The solution must meet the requirements shown in the following table.

Which type of SCD should you use for each table? To answer, drag the appropriate SCD types to the correct tables. Each SCD type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.

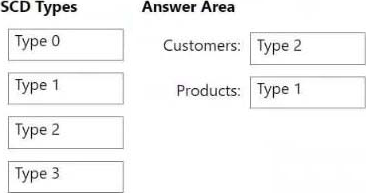
Explanation:
Box 1: Type 2
There are 6 types of Slowly Changing Dimension that are commonly used, they are as follows:
Type 0 C Fixed Dimension
No changes allowed, dimension never changes
Type 1 C No History
Update record directly, there is no record of historical values, only current state
Type 2 C Row Versioning
Track changes as version records with current flag & active dates and other metadata
Type 3 C Previous Value column
Track change to a specific attribute, add a column to show the previous value, which is updated as further changes occur
Etc.
Box 2: Type 1
Reference: https://adatis.co.uk/introduction-to-slowly-changing-dimensions-scd-types/
HOTSPOT
You have a Microsoft Power BI project that contains a file named definition.pbir. definition.pbir contains the following JSON.

For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
Explanation:
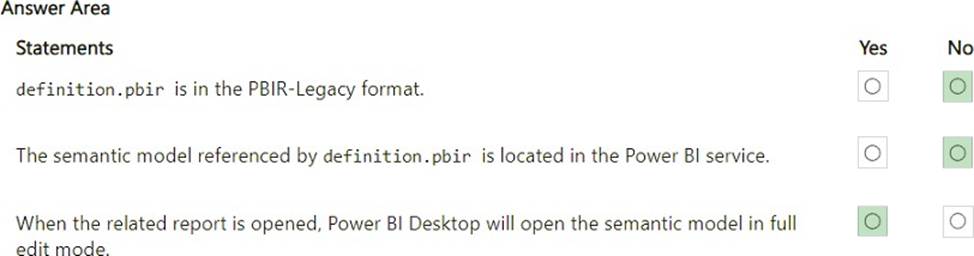
definition.pbir is in the PBIR-Legacy format – No
The JSON structure indicates a dataset reference (datasetReference), which aligns with the newer PBIR format. The PBIR-Legacy format uses a different structure that does not include these specific fields.
The semantic model referenced by definition.pbir is located in the Power BI service – No
The byPath property in the JSON refers to a local file path (../Sales.Dataset). This indicates that the semantic model is not stored in the Power BI service but is instead referenced locally.
When the related report is opened, Power BI Desktop will open the semantic model in full edit mode – Yes
Since the semantic model is referenced by a local file path (byPath), Power BI Desktop can load the model in full edit mode, allowing modifications.
The PBIR format is used to store definitions for Power BI reports. The format can refer to datasets locally (byPath) or in the Power BI service (byConnection). In this case, the byPath property indicates a local reference, which impacts how the report and dataset are opened and used in Power BI Desktop.
You have a Fabric notebook that has the Python code and output shown in the following exhibit.
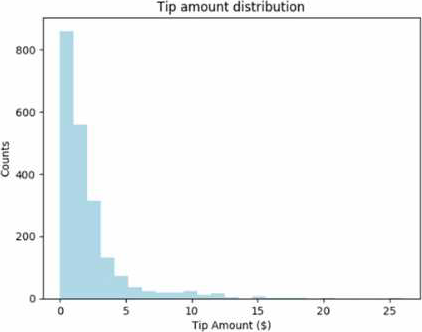
Which type of analytics are you performing?
- A . descriptive
- B . diagnostic
- C . prescriptive
- D . predictive
A
Explanation:
This is a histogram. Histogram are used in relation to descriptive statistics calculations.
Reference: https://www.advantive.com/solutions/spc-software/quality-advisor/data-analysis-tools/histogram-calculate-descriptive-statistics/
You have a Fabric notebook that has the Python code and output shown in the following exhibit.
Which type of analytics are you performing?
- A . descriptive
- B . diagnostic
- C . prescriptive
- D . predictive
A
Explanation:
This is a histogram. Histogram are used in relation to descriptive statistics calculations.
Reference: https://www.advantive.com/solutions/spc-software/quality-advisor/data-analysis-tools/histogram-calculate-descriptive-statistics/
You have a Fabric notebook that has the Python code and output shown in the following exhibit.
Which type of analytics are you performing?
- A . descriptive
- B . diagnostic
- C . prescriptive
- D . predictive
A
Explanation:
This is a histogram. Histogram are used in relation to descriptive statistics calculations.
Reference: https://www.advantive.com/solutions/spc-software/quality-advisor/data-analysis-tools/histogram-calculate-descriptive-statistics/
HOTSPOT
You have a Fabric warehouse that contains the following data.

The data has the following characteristics:
– Each customer is assigned a unique CustomerID value.
– Each customer is associated to a single SalesRegion value.
– Each customer is associated to a single CustomerAddress value.
– The Customer table contains 5 million rows.
– All foreign key values are non-null.
You need to create a view to denormalize the data into a customer dimension that contains one row per distinct CustomerID value. The solution must minimize query processing time and resources.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
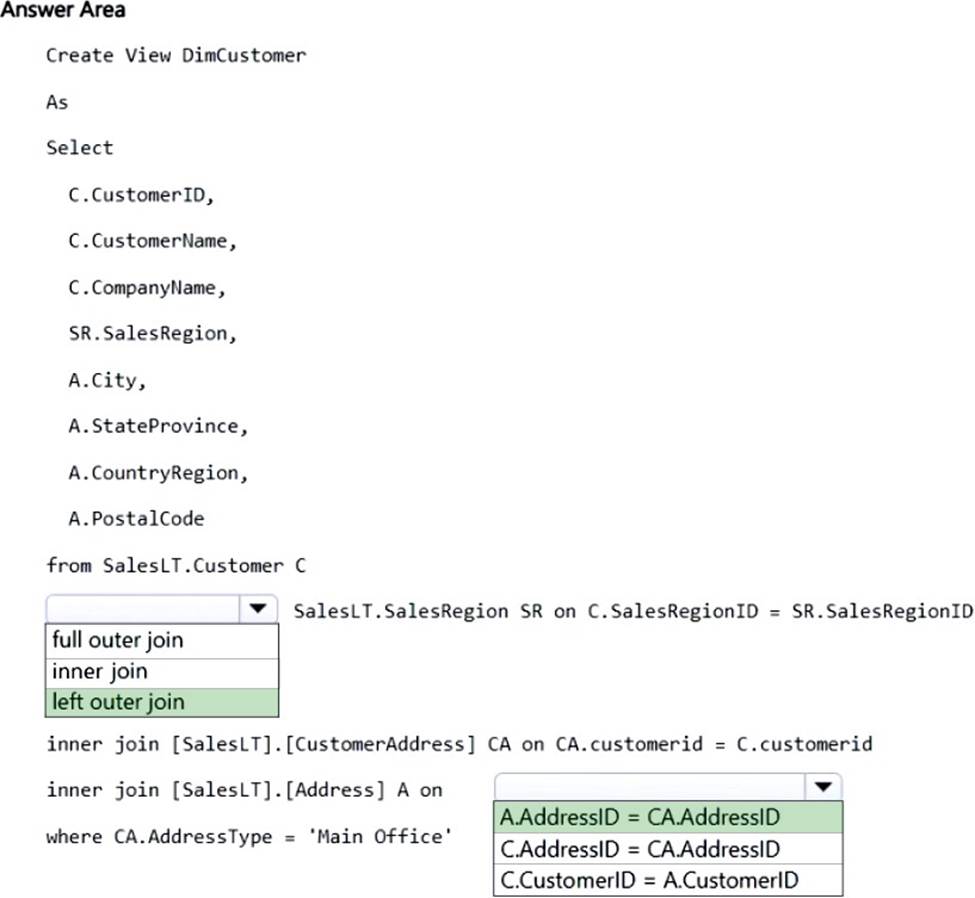
Explanation:
Box 1: left outer join
A join between the Customer table and the SalesRegion table.
We denormalize with a left out join.
Incorrect:
* Inner join
Box 2: A.AdressID = CA.AddressID
The Address Table, abbreviated A, and the CustomerAddress table, abbreviated CA, both have AddressID columns.
HOTSPOT
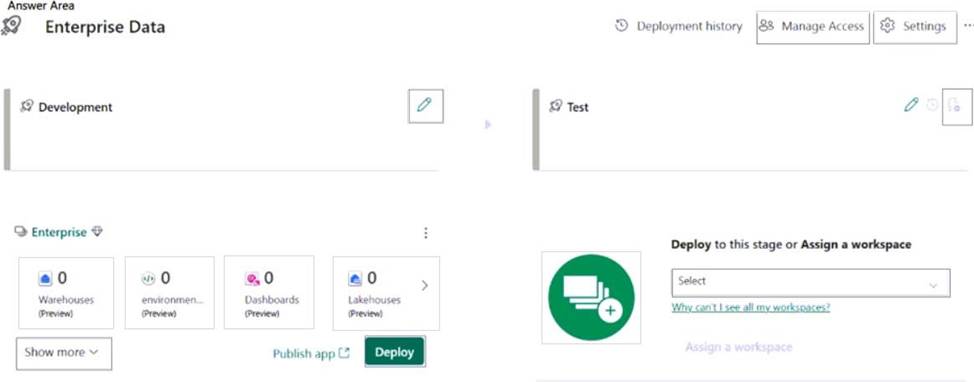
You have a Fabric tenant that contains a workspace named Enterprise. Enterprise contains a semantic model named Model1. Model1 contains a date parameter named Date1 that was created in Power Query.
You build a deployment pipeline named Enterprise Data that includes two stages named Development and Test. You assign the Enterprise workspace to the Development stage.
You need to perform the following actions:
– Create a workspace named Enterprise [Test] and assign the workspace to the Test stage.
– Configure a rule that will modify the value of Date1 when changes are deployed to the Test stage.
Which two settings should you use? To answer, select the appropriate settings in the answer area. NOTE: Each correct answer is worth one point.
Explanation:
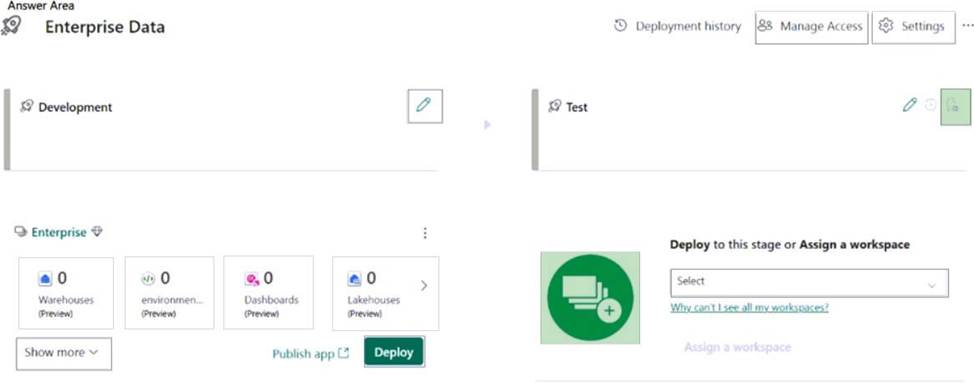
Box 1: Add workspace button (with a +sign)
Create a workspace named Enterprise [Test] and assign the workspace to the Test stage.
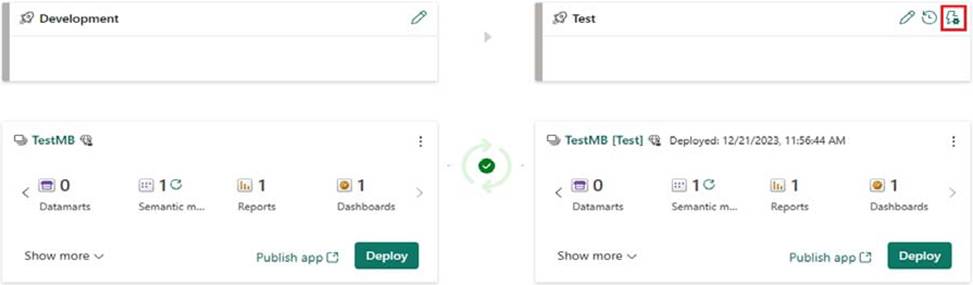
Box 2: Deployment rule [Upper right corner]
Configure a rule that will modify the value of Date1 when changes are deployed to the Test stage.
In the pipeline stage you want to create a deployment rule for, select Deployment rules
Reference: https://learn.microsoft.com/en-us/fabric/cicd/deployment-pipelines/create-rules