
Practice Free DP-600 Exam Online Questions
HOTSPOT
You have a Fabric workspace that contains a warehouse named DW1.
DW1 contains the following tables and columns.

You need to summarize order quantities by year and product. The solution must include the yearly sum of order quantities for all the products in each row.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


Explanation:

YEAR(SO.ModifiedDate)
Extracts the year from the ModifiedDate column to aggregate order quantities by year.
ROLLUP(YEAR(SO.ModifiedDate), P.Name)
The ROLLUP function generates subtotal rows:
– Summarized total order quantity per product per year.
– Overall total order quantity per year (product subtotal).
Note: This section contains one or more sets of questions with the same scenario and problem. Each question presents a unique solution to the problem. You must determine whether the solution meets the stated goals. More than one solution in the set might solve the problem. It is also possible that none of the solutions in the set solve the problem.
After you answer a question in this section, you will NOT be able to return. As a result, these questions do not appear on the Review Screen.
Your network contains an on-premises Active Directory Domain Services (AD DS) domain named contoso.com that syncs with a Microsoft Entra tenant by using Microsoft Entra Connect.
You have a Fabric tenant that contains a semantic model.
You enable dynamic row-level security (RLS) for the model and deploy the model to the Fabric service.
You query a measure that includes the USERNAME() function, and the query returns a blank result.
You need to ensure that the measure returns the user principal name (UPN) of a user.
Solution: You update the measure to use the USEROBJECTID() function.
Does this meet the goal?
- A . Yes
- B . No
B
Explanation:
This function returns the unique identifier (Object ID) of the user in Azure Active Directory. While this can be useful for certain scenarios, it does not return the UPN, which is what you need.
You have a Fabric tenant that contains a workspace named Workspace1 and a user named User1. User1 is assigned the Contributor role for Workspace1.
You plan to configure Workspace1 to use an Azure DevOps repository for version control.
You need to ensure that User1 can commit items to the repository.
Which two settings should you enable for User1? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Users can sync workspace items with GitHub repositories
- B . Users can create and use Data workflows
- C . Users can create Fabric items
- D . Users can synchronize workspace items with their Git repositories
CD
Explanation:
To integrate Git with your Microsoft Fabric workspace, you need to set up the following prerequisites for both Fabric and Git.
Fabric prerequisites
To access the Git integration feature, you need a Fabric capacity. A Fabric capacity is required to use all supported Fabric items
In addition, the following tenant switches must be enabled from the Admin portal:
* (C) Users can create Fabric items
* (D) Users can synchronize workspace items with their Git repositories
* For GitHub users only: Users can synchronize workspace items with GitHub repositories
These switches can be enabled by the tenant admin, capacity admin, or workspace admin, depending on your organization’s settings.
Reference: https://learn.microsoft.com/en-us/fabric/cicd/git-integration/git-get-started
You have a Fabric tenant that contains a workspace named Workspace1 and a user named User1. User1 is assigned the Contributor role for Workspace1.
You plan to configure Workspace1 to use an Azure DevOps repository for version control.
You need to ensure that User1 can commit items to the repository.
Which two settings should you enable for User1? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Users can sync workspace items with GitHub repositories
- B . Users can create and use Data workflows
- C . Users can create Fabric items
- D . Users can synchronize workspace items with their Git repositories
CD
Explanation:
To integrate Git with your Microsoft Fabric workspace, you need to set up the following prerequisites for both Fabric and Git.
Fabric prerequisites
To access the Git integration feature, you need a Fabric capacity. A Fabric capacity is required to use all supported Fabric items
In addition, the following tenant switches must be enabled from the Admin portal:
* (C) Users can create Fabric items
* (D) Users can synchronize workspace items with their Git repositories
* For GitHub users only: Users can synchronize workspace items with GitHub repositories
These switches can be enabled by the tenant admin, capacity admin, or workspace admin, depending on your organization’s settings.
Reference: https://learn.microsoft.com/en-us/fabric/cicd/git-integration/git-get-started
You have a Fabric workspace named Workspace1 and an Azure SQL database.
You plan to create a dataflow that will read data from the database, and then transform the data by performing an inner join.
You need to ignore spaces in the values when performing the inner join. The solution must minimize development effort.
What should you do?
- A . Append the queries by using fuzzy matching.
- B . Merge the queries by using fuzzy matching.
- C . Append the queries by using a lookup table.
- D . Merge the queries by using a lookup table.
B
Explanation:
Joins are merge operations.
Join transformation in mapping data flow
Use the join transformation to combine data from two sources or streams in a mapping data flow. The output stream will include all columns from both sources matched based on a join condition.
Inner join only outputs rows that have matching values in both tables.
Fuzzy join
You can choose to join based on fuzzy join logic instead of exact column value matching by turning on the "Use fuzzy matching" checkbox option.
*-> Combine text parts: Use this option to find matches by remove space between words. For example, Data Factory is matched with DataFactory if this option is enabled.
Similarity score column: You can optionally choose to store the matching score for each row in a column by entering a new column name here to store that value.
Similarity threshold: Choose a value between 60 and 100 as a percentage match between values in the columns you’ve selected.

Reference: https://learn.microsoft.com/en-us/azure/data-factory/data-flow-join
You have a Fabric tenant that contains a workspace named Workspace1.
You plan to deploy a semantic model named Model1 by using the XMLA endpoint.
You need to optimize the deployment of Model1. The solution must minimize how long it takes to deploy Model1.
What should you do in Workspace1?
- A . Select Small semantic model storage format.
- B . Select Users can edit data models in the Power BI service.
- C . Set Enable Cache for Shortcuts to On.
- D . Select Large semantic model storage format.
D
Explanation:
The Large semantic model storage format is designed for handling large and complex datasets, improving the efficiency of operations like loading, processing, and deploying models. It is optimized for scalability and performance, which helps minimize the deployment time for large models.
HOTSPOT
You are creating a report and a semantic model in Microsoft Power BI Desktop.
The Value measure has the expression shown in the following exhibit.

Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point.


Explanation:
A dynamic format string was added to the Value measure.
The Value measure can return values formatted as percentages or whole numbers.
Dynamic Format String:
The DAX formula uses SWITCH(SELECTEDVALUE(Metric[Metric]), …)to dynamically change the format of the Value measure. This is a dynamic format string, which allows the measure to return either whole numbers (#) or percentages (0.00%), depending on the selected metric.
Formatted as Percentages or Whole Numbers:
The formula specifies that if the metric is "# of Customers", the output is formatted as a whole number (#,###). If the metric is "Gross Margin %", the output is formatted as a percentage (0.00%). Since the measure can return both whole numbers and percentages, the correct answer is "percentages or whole numbers."
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a lakehouse named Lakehouse1. Lakehouse1 contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on Customer.
Solution: You run the following Spark SQL statement:
EXPLAIN TABLE customer
Does this meet the goal?
- A . Yes
- B . No
B
Explanation:
Correct Solution: You run the following Spark SQL statement:
DESCRIBE HISTORY customer
DESCRIBE HISTORY
Applies to: Databricks SQL, Databricks Runtime
Returns provenance information, including the operation, user, and so on, for each write to a table. Table history is retained for 30 days.
Syntax
DESCRIBE HISTORY table_name
Note: Work with Delta Lake table history
Each operation that modifies a Delta Lake table creates a new table version. You can use history information to audit operations, rollback a table, or query a table at a specific point in time using time travel.
Retrieve Delta table history
You can retrieve information including the operations, user, and timestamp for each write to a Delta table by running the history command. The operations are returned in reverse chronological order.
DESCRIBE HISTORY ‘/data/events/’ — get the full history of the table
DESCRIBE HISTORY delta.`/data/events/`
DESCRIBE HISTORY ‘/data/events/’ LIMIT 1 — get the last operation only
DESCRIBE HISTORY eventsTable
Incorrect:
* DESCRIBE DETAIL customer
DESCRIBE TABLE statement returns the basic metadata information of a table. The metadata information includes column name, column type and column comment. Optionally a partition spec or column name may be specified to return the metadata pertaining to a partition or column respectively.
* EXPLAIN TABLE customer
* REFRESH TABLE
REFRESH TABLE statement invalidates the cached entries, which include data and metadata of the given table or view. The invalidated cache is populated in lazy manner when the cached table or the query associated with it is executed again.
Syntax
REFRESH [TABLE] tableIdentifier
Reference: https://learn.microsoft.com/en-us/azure/databricks/sql/language-manual/delta-describe-history
https://docs.gcp.databricks.com/en/delta/history.html
https://spark.apache.org/docs/3.0.0-preview/sql-ref-syntax-aux-refresh-table.html
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a lakehouse named Lakehouse1. Lakehouse1 contains a Delta table named Customer.
When you query Customer, you discover that the query is slow to execute. You suspect that maintenance was NOT performed on the table.
You need to identify whether maintenance tasks were performed on Customer.
Solution: You run the following Spark SQL statement:
EXPLAIN TABLE customer
Does this meet the goal?
- A . Yes
- B . No
B
Explanation:
Correct Solution: You run the following Spark SQL statement:
DESCRIBE HISTORY customer
DESCRIBE HISTORY
Applies to: Databricks SQL, Databricks Runtime
Returns provenance information, including the operation, user, and so on, for each write to a table. Table history is retained for 30 days.
Syntax
DESCRIBE HISTORY table_name
Note: Work with Delta Lake table history
Each operation that modifies a Delta Lake table creates a new table version. You can use history information to audit operations, rollback a table, or query a table at a specific point in time using time travel.
Retrieve Delta table history
You can retrieve information including the operations, user, and timestamp for each write to a Delta table by running the history command. The operations are returned in reverse chronological order.
DESCRIBE HISTORY ‘/data/events/’ — get the full history of the table
DESCRIBE HISTORY delta.`/data/events/`
DESCRIBE HISTORY ‘/data/events/’ LIMIT 1 — get the last operation only
DESCRIBE HISTORY eventsTable
Incorrect:
* DESCRIBE DETAIL customer
DESCRIBE TABLE statement returns the basic metadata information of a table. The metadata information includes column name, column type and column comment. Optionally a partition spec or column name may be specified to return the metadata pertaining to a partition or column respectively.
* EXPLAIN TABLE customer
* REFRESH TABLE
REFRESH TABLE statement invalidates the cached entries, which include data and metadata of the given table or view. The invalidated cache is populated in lazy manner when the cached table or the query associated with it is executed again.
Syntax
REFRESH [TABLE] tableIdentifier
Reference: https://learn.microsoft.com/en-us/azure/databricks/sql/language-manual/delta-describe-history
https://docs.gcp.databricks.com/en/delta/history.html
https://spark.apache.org/docs/3.0.0-preview/sql-ref-syntax-aux-refresh-table.html
You have a Fabric warehouse that contains a table named Staging.Sales. Staging.Sales contains the following columns.
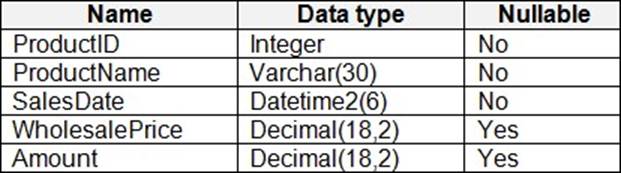
You need to write a T-SQL query that will return data for the year 2023 that displays ProductID and ProductName and has a summarized Amount that is higher than 10,000.
Which query should you use?
A)

B)

C)

D)

- A . Option A
- B . Option B
- C . Option C
- D . Option D
A
Explanation:
SELECT – GROUP BY- Transact-SQL
SELECT statement clause that divides the query result into groups of rows, usually by performing one or more aggregations on each group. The SELECT statement returns one row per group.
Note: General Remarks
How GROUP BY interacts with the SELECT statement
SELECT list:
Vector aggregates. If aggregate functions are included in the SELECT list, GROUP BY calculates a summary value for each group. These are known as vector aggregates.
Distinct aggregates. The aggregates AVG (DISTINCT column_name), COUNT (DISTINCT column_name), and SUM (DISTINCT column_name) are supported with ROLLUP, CUBE, and GROUPING SETS.
WHERE clause:
SQL removes Rows that do not meet the conditions in the WHERE clause before any grouping operation is performed.
*-> HAVING clause:
SQL uses the having clause to filter groups in the result set.
Incorrect:
Not B: Put the 2023 filtering in the WHERE clause, not in the HAVING clause.
Not C: Need a GROUP BY clause-
Not D: Can’t use the alias TOTALAMOUNT in the HAVING clause.
Reference: https://learn.microsoft.com/en-us/sql/t-sql/queries/select-group-by-transact-sql