
Practice Free DP-600 Exam Online Questions
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric tenant that contains a semantic model named Model1.
You discover that the following query performs slowly against Model1.

You need to reduce the execution time of the query.
Solution: You replace line 4 by using the following code:
CALCULATE (COUNTROWS (‘Order Item’)) >= 0
Does this meet the goal?
- A . Yes
- B . No
B
Explanation:
Correct: NOT ISEMPTY (CALCULATETABLE (‘Order Item ‘))
Just check if it is empty or not.
Note: ISEMPTY
Checks if a table is empty.
Syntax
ISEMPTY(<table_expression>)
Parameters
table_expression – A table reference or a DAX expression that returns a table.
Return value – True if the table is empty (has no rows), if else, False.
Incorrect:
* CALCULATE (COUNTROWS (‘Order Item’)) >= 0
* ISEMPTY (RELATEDTABLE (‘Order Item’))
Reference: https://learn.microsoft.com/en-us/dax/isempty-function-dax
HOTSPOT
You have a Fabric lakehouse named Lakehouse1 that contains the following data.

You need build a T-SQL statement that will return the total sales amount by OrderDate only for the days that are holidays in Australia. The total sales amount must sum the quantity multiplied by the price on each row in the dbo.sales table.
How should you complete the statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


Explanation:
Box 1: Sum(s.Quantity * s.UnitPrice)
Calculate the sum of Quantity * Unitprice.
Incorrect:
* s.Quantity * S.UnitPrice Need to use the SUM function.
* Sum (s.Quantity) * S.UnitPrice) Incorrect parenthesis.
* Sum (s.Quantity) * S.UnitPrice Not the sum of the Quantity.
* Sum (s.Quantity) * SUM(S.UnitPrice)
Not separate sums of the Quantity and the UnitPrice.
Box 2: Inner
Standard inner join
You have a Fabric tenant that contains a semantic model. The model uses Direct Lake mode.
You suspect that some DAX queries load unnecessary columns into memory.
You need to identify the frequently used columns that are loaded into memory.
What are two ways to achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct answer is worth one point.
- A . Use the Analyze in Excel feature.
- B . Use the Vertipaq Analyzer tool.
- C . Query the $System.DISCOVER_STORAGE_TABLE_COLUMN_SEGMENTS dynamic management view (DMV).
- D . Query the DISCOVER_MEMORYGRANT dynamic management view (DMV).
HOTSPOT
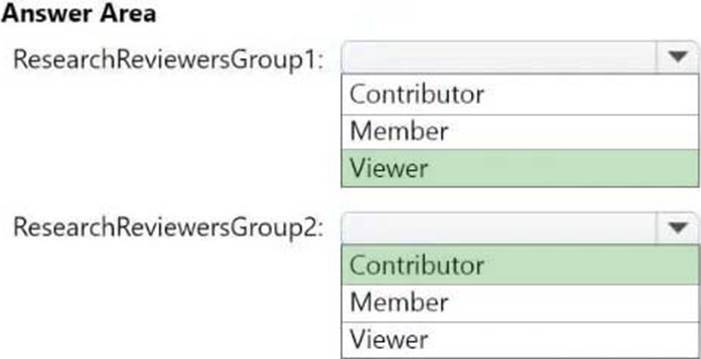
Which workspace role assignments should you recommend for ResearchReviewersGroup1 and ResearchReviewersGroup2? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

Explanation:
Box 1: Viewer
ResearchReviewersGroup1
For the Research division workspaces, the members of ResearchReviewersGroup1 must be able to read lakehouse and warehouse data and shortcuts by using SQL endpoints.
Workspace roles in Lakehouse
Workspace roles define what user can do with Microsoft Fabric items. Roles can be assigned to individuals or security groups from workspace view. See, Give users access to workspaces.
The user can be assigned to the following roles:
Admin
Member
Contributor
Viewer
In a lakehouse the users with Admin, Member, and Contributor roles can perform all CRUD (CREATE, READ, UPDATE and DELETE) operations on all data. A user with Viewer role can only read data stored in Tables using the SQL analytics endpoint.
Box 2: Contributor
ResearchReviewersGroup2
For the Research division workspaces, the members of ResearchReviewersGroup2 must be able to read lakehouse data by using Lakehouse explorer.
Microsoft Fabric workspace roles

Etc.
Incorrect:
* Member
More permissions compared to Contributor
Scenario:
Identity Environment
Contoso has a Microsoft Entra tenant named contoso.com. The tenant contains two groups named ResearchReviewersGroup1 and ResearchReviewersGroup2.
Reference: https://learn.microsoft.com/en-us/fabric/data-engineering/workspace-roles-lakehouse
https://learn.microsoft.com/en-us/fabric/get-started/roles-workspaces
HOTSPOT
Which workspace role assignments should you recommend for ResearchReviewersGroup1 and ResearchReviewersGroup2? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Explanation:
Box 1: Viewer
ResearchReviewersGroup1
For the Research division workspaces, the members of ResearchReviewersGroup1 must be able to read lakehouse and warehouse data and shortcuts by using SQL endpoints.
Workspace roles in Lakehouse
Workspace roles define what user can do with Microsoft Fabric items. Roles can be assigned to individuals or security groups from workspace view. See, Give users access to workspaces.
The user can be assigned to the following roles:
Admin
Member
Contributor
Viewer
In a lakehouse the users with Admin, Member, and Contributor roles can perform all CRUD (CREATE, READ, UPDATE and DELETE) operations on all data. A user with Viewer role can only read data stored in Tables using the SQL analytics endpoint.
Box 2: Contributor
ResearchReviewersGroup2
For the Research division workspaces, the members of ResearchReviewersGroup2 must be able to read lakehouse data by using Lakehouse explorer.
Microsoft Fabric workspace roles
Etc.
Incorrect:
* Member
More permissions compared to Contributor
Scenario:
Identity Environment
Contoso has a Microsoft Entra tenant named contoso.com. The tenant contains two groups named ResearchReviewersGroup1 and ResearchReviewersGroup2.
Reference: https://learn.microsoft.com/en-us/fabric/data-engineering/workspace-roles-lakehouse
https://learn.microsoft.com/en-us/fabric/get-started/roles-workspaces
DRAG DROP
You have a Fabric workspace that contains a Dataflow Gen2 query. The query returns the following data.

You need to filter the results to ensure that only the latest version of each customer’s record is retained.
The solution must ensure that no new columns are loaded to the semantic model.
Which four actions should you perform in sequence in Power Query Editor? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.


Explanation:
HOTSPOT
You have a Fabric warehouse that contains a table named Sales.Orders. Sales.Orders contains the following columns.

You need to write a T-SQL query that will return the following columns.

How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct answer is worth one point.


Explanation:
Box 1: DATETRUNC
QUESTION NO: NO: PeriodDate: Returns a date representing the first day of the month for OrderDate
DATETRUNC (Transact-SQL)
The DATETRUNC function returns an input date truncated to a specified datepart.
Syntax
DATETRUNC (datepart, date)
Arguments
datepart
Specifies the precision for truncation. This table lists all the valid datepart values for DATETRUNC, given that it’s also a valid part of the input date type.
Box 2: weekday
Question: DayName returns the name of the day for OrderDate, such as Wednesday
Note: DATENAME (Transact-SQL)
This function returns a character string representing the specified datepart of the specified date.
Syntax
DATENAME (datepart, date)
datepart
The specific part of the date argument that DATENAME will return. This table lists all valid datepart arguments.
weekday
Etc.
Incorrect:
* DATE_BUCKET (Transact-SQL)
This function returns the date-time value corresponding to the start of each date-time bucket from the timestamp defined by the origin parameter, or the default origin value of 1900-01-01 00:00:00.000 if the origin parameter isn’t specified.
See Date and Time Data Types and Functions (Transact-SQL) for an overview of all Transact-SQL date and time data types and functions.
Syntax
DATE_BUCKET (datepart, number, date [, origin ] )
* DATEFROMPARTS
This function returns a date value that maps to the specified year, month, and day values.
Syntax
DATEFROMPARTS (year, month, day )
* DATEPART (Transact-SQL)
This function returns an integer representing the specified datepart of the specified date.
Reference: https://learn.microsoft.com/en-us/sql/t-sql/functions/datetrunc-transact-sql
Which syntax should you use in a notebook to access the Research division data for Productline1?
- A . spark.read.format(“delta”).load(“Tables/productline1/ResearchProduct”)
- B . spark.sql(“SELECT * FROM Lakehouse1.ResearchProduct ”)
- C . external_table(‘Tables/ResearchProduct)
- D . external_table(ResearchProduct)
B
Explanation:
Correct:
* spark.read.format(“delta”).load(“Tables/ResearchProduct”)
* spark.sql(“SELECT * FROM Lakehouse1.ResearchProduct ”)
Incorrect:
* external_table(‘Tables/ResearchProduct)
* external_table(ResearchProduct)
* spark.read.format(“delta”).load(“Files/ResearchProduct”)
* spark.read.format(“delta”).load(“Tables/productline1/ResearchProduct”)
* spark.sql(“SELECT * FROM Lakehouse1.Tables.ResearchProduct ”)
Note: Apache Spark
Apache Spark notebooks and Apache Spark jobs can use shortcuts that you create in OneLake. Relative file paths can be used to directly read data from shortcuts. Additionally, if you create a shortcut in the Tables section of the lakehouse and it is in the Delta format, you can read it as a managed table using Apache Spark SQL syntax.
Can use either:
df = spark.read.format("delta").load("Tables/MyShortcut")
display(df)
OR
df = spark.sql("SELECT * FROM MyLakehouse.MyShortcut LIMIT 1000")
display(df)
Reference: https://learn.microsoft.com/en-us/fabric/onelake/onelake-shortcuts
DRAG DROP
You have a Fabric tenant that contains a lakehouse named Lakehouse1.
Readings from 100 IoT devices are appended to a Delta table in Lakehouse1. Each set of readings is approximately 25 KB. Approximately 10 GB of data is received daily.
All the table and SparkSession settings are set to the default.
You discover that queries are slow to execute. In addition, the lakehouse storage contains data and log files that are no longer used.
You need to remove the files that are no longer used and combine small files into larger files with a target size of 1 GB per file.
What should you do? To answer, drag the appropriate actions to the correct requirements. Each action may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


Explanation:
Box 1: Run the VACUUM command on a schedule.
Remove the files.
Remove old files with the Delta Lake Vacuum Command
You can remove files marked for deletion (aka “tombstoned files”) from storage with the Delta Lake vacuum command. Delta Lake doesn’t physically remove files from storage for operations that logically delete the files. You need to use the vacuum command to physically remove files from storage that have been marked for deletion and are older than the retention period.
The main benefit of vacuuming is to save on storage costs. Vacuuming does not make your queries run any faster and can limit your ability to time travel to earlier Delta table versions. You need to weigh the costs/benefits for each of your tables to develop an optimal vacuum strategy. Some tables should be vacuumed frequently. Other tables should never be vacuumed.
Box 2: Run the OPTIMIZE command on a schedule.
Combine the files.
Best practices: Delta Lake
Compact files
If you continuously write data to a Delta table, it will over time accumulate a large number of files, especially if you add data in small batches. This can have an adverse effect on the efficiency of table reads, and it can also affect the performance of your file system. Ideally, a large number of small files should be rewritten into a smaller number of larger files on a regular basis. This is known as compaction.
You can compact a table using the OPTIMIZE command.
Reference:
https://delta.io/blog/remove-files-delta-lake-vacuum-command/
https://docs.databricks.com/en/delta/best-practices.html
DRAG DROP
You have a Fabric tenant that contains a lakehouse named Lakehouse1.
Readings from 100 IoT devices are appended to a Delta table in Lakehouse1. Each set of readings is approximately 25 KB. Approximately 10 GB of data is received daily.
All the table and SparkSession settings are set to the default.
You discover that queries are slow to execute. In addition, the lakehouse storage contains data and log files that are no longer used.
You need to remove the files that are no longer used and combine small files into larger files with a target size of 1 GB per file.
What should you do? To answer, drag the appropriate actions to the correct requirements. Each action may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Explanation:
Box 1: Run the VACUUM command on a schedule.
Remove the files.
Remove old files with the Delta Lake Vacuum Command
You can remove files marked for deletion (aka “tombstoned files”) from storage with the Delta Lake vacuum command. Delta Lake doesn’t physically remove files from storage for operations that logically delete the files. You need to use the vacuum command to physically remove files from storage that have been marked for deletion and are older than the retention period.
The main benefit of vacuuming is to save on storage costs. Vacuuming does not make your queries run any faster and can limit your ability to time travel to earlier Delta table versions. You need to weigh the costs/benefits for each of your tables to develop an optimal vacuum strategy. Some tables should be vacuumed frequently. Other tables should never be vacuumed.
Box 2: Run the OPTIMIZE command on a schedule.
Combine the files.
Best practices: Delta Lake
Compact files
If you continuously write data to a Delta table, it will over time accumulate a large number of files, especially if you add data in small batches. This can have an adverse effect on the efficiency of table reads, and it can also affect the performance of your file system. Ideally, a large number of small files should be rewritten into a smaller number of larger files on a regular basis. This is known as compaction.
You can compact a table using the OPTIMIZE command.
Reference:
https://delta.io/blog/remove-files-delta-lake-vacuum-command/
https://docs.databricks.com/en/delta/best-practices.html