
Practice Free Databricks Certified Professional Data Engineer Exam Online Questions
A data engineer is testing a collection of mathematical functions, one of which calculates the area under a curve as described by another function.
Which kind of the test does the above line exemplify?
- A . Integration
- B . Unit
- C . Manual
- D . functional
B
Explanation:
A unit test is designed to verify the correctness of a small, isolated piece of code, typically a single function. Testing a mathematical function that calculates the area under a curve is an example of a unit test because it is testing a specific, individual function to ensure it operates as expected.
Software Testing Fundamentals: Unit Testing
A Data Engineer is building a simple data pipeline using Lakeflow Declarative Pipelines (LDP) in Databricks to ingest customer data. The raw customer data is stored in a cloud storage location in JSON format. The task is to create Lakeflow Declarative Pipelines that read the raw JSON data and write it into a Delta table for further processing.
Which code snippet will correctly ingest the raw JSON data and create a Delta table using LDP?
- A . import [email protected] raw_customers():return spark.read.format("csv").load("s3://my-bucket/raw-customers/")
- B . import [email protected] raw_customers():return spark.read.json("s3://my-bucket/raw-customers/")
- C . import [email protected] raw_customers():return spark.read.format("parquet").load("s3://my-bucket/raw-customers/")
- D . import [email protected] raw_customers():return spark.format.json("s3://my-bucket/raw-customers/")
B
Explanation:
The correct method to define a table using Lakeflow Declarative Pipelines (LDP) is with the @dlt.table decorator, which persists the output as a managed Delta table. When ingesting raw JSON data, spark.read.json() or spark.read.format("json").load() is the standard approach. This reads JSON-formatted files from the source and stores them in Delta format automatically managed by Databricks.
Reference Source: Databricks Lakeflow Declarative Pipelines Developer Guide C “Create tables from raw JSON and Delta sources.”
A platform team lead is responsible for automating SQL Warehouse usage attribution across business units. They need to identify warehouse usage at the individual user level and share a daily usage report with an executive team that includes business leaders from multiple departments.
How should the platform lead generate an automated report that can be shared daily?
- A . Use system tables to capture audit and billing usage data and share the queries with the executive team for manual execution.
- B . Use system tables to capture audit and billing usage data and create a dashboard with a daily refresh schedule shared with the executive team.
- C . Restrict users from running SQL queries unless they provide query details for attribution tracking.
- D . Let users run queries normally and have individual teams manually report usage to the executive team.
B
Explanation:
Databricks provides system tables under the system.billing and system.access schemas for auditing and cost attribution across SQL Warehouses. The best practice is to build a dashboard in Databricks SQL using these system tables and configure it with a daily refresh schedule. This ensures automated, up-to-date reporting of compute consumption, user activity, and cost distribution. Sharing this dashboard with executives provides transparency without requiring them to run queries manually. This approach aligns with Databricks’ operational guidance on workspace observability and cost governance, making B the correct answer.
A nightly job ingests data into a Delta Lake table using the following code:
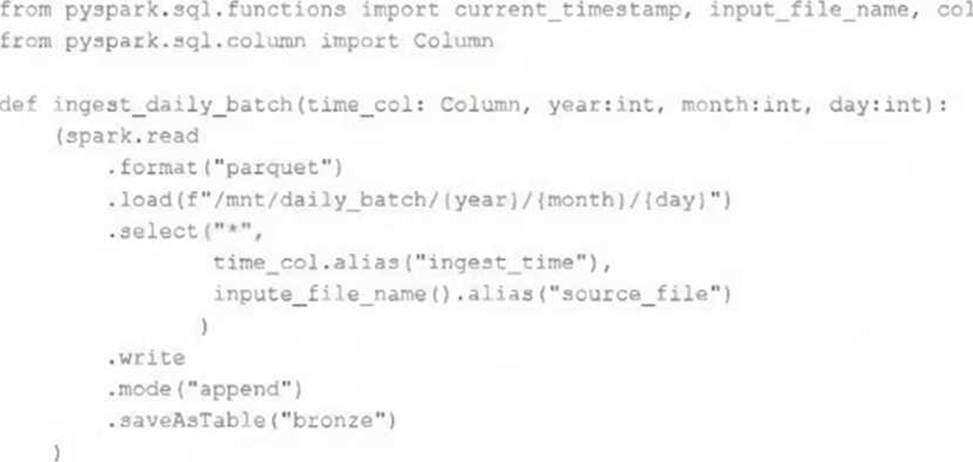
The next step in the pipeline requires a function that returns an object that can be used to manipulate new records that have not yet been processed to the next table in the pipeline.
Which code snippet completes this function definition?
def new_records():
A) return spark.readStream.table("bronze")
B) return spark.readStream.load("bronze")
C)

D) return spark.read.option("readChangeFeed", "true").table ("bronze")
E)

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
E
Explanation:
https://docs.databricks.com/en/delta/delta-change-data-feed.html
A data engineer manages a production Lakeflow Declarative Pipeline that processes customer transaction data. The pipeline includes several data quality expectations such as transaction_amount > 0 and customer_id IS NOT NULL. These expectations are defined using the EXPECT clause in SQL.
The engineer aims to monitor the pipeline’s data quality by analyzing the number of records that passed or failed each expectation during the latest pipeline update. The Lakeflow Declarative Pipelines event logs are stored in a Delta table named event_log_table.
For the most recent pipeline update, determine a programmatically appropriate approach to extract information like the name of each expectation, associated dataset, count of records that passed the expectation, and count of records that failed the expectation.
Which method retrieves the desired data quality metrics from the Lakeflow Declarative Pipelines event log?
- A . Access the event_log_table, filter for events where event_type = ‘flow_progress’, and parse details.flow_progress.data_quality.expectations field to extract the required metrics.
- B . Use the Lakeflow Declarative Pipelines UI to navigate to the specific pipeline, select the dataset, and view the Data Quality tab to manually retrieve the expectation metrics.
- C . Query the event_log_table for events with event_type = ‘data_quality’ and directly select the passed_records and failed_records fields.
- D . Access the event_log_table, filter for events where event_type = ‘expectation_result’, and extract the expectation metrics from the details field.
D
Explanation:
The Databricks documentation specifies that for Lakeflow Declarative Pipelines, detailed data quality metrics are logged as events of type expectation_result within the event log. Each record of this type contains fields including expectation_name, dataset_name, passed_records, and failed_records.
Filtering on event_type = ‘expectation_result’ and expanding the details field allows retrieving metrics for each expectation from the most recent pipeline update. While flow_progress provides summary statistics and data_quality events aggregate results, only expectation_result events provide granular, per-expectation metrics required for audit and monitoring automation.
The Databricks workspace administrator has configured interactive clusters for each of the data engineering groups. To control costs, clusters are set to terminate after 30 minutes of inactivity. Each user should be able to execute workloads against their assigned clusters at any time of the day.
Assuming users have been added to a workspace but not granted any permissions, which of the following describes the minimal permissions a user would need to start and attach to an already configured cluster.
- A . "Can Manage" privileges on the required cluster
- B . Workspace Admin privileges, cluster creation allowed. "Can Attach To" privileges on the required cluster
- C . Cluster creation allowed. "Can Attach To" privileges on the required cluster
- D . "Can Restart" privileges on the required cluster
- E . Cluster creation allowed. "Can Restart" privileges on the required cluster
D
Explanation:
https://learn.microsoft.com/en-us/azure/databricks/security/auth-authz/access-control/cluster-acl
https://docs.databricks.com/en/security/auth-authz/access-control/cluster-acl.html
An upstream source writes Parquet data as hourly batches to directories named with the current date.
A nightly batch job runs the following code to ingest all data from the previous day as indicated by the date variable:

Assume that the fields customer_id and order_id serve as a composite key to uniquely identify each order.
If the upstream system is known to occasionally produce duplicate entries for a single order hours apart, which statement is correct?
- A . Each write to the orders table will only contain unique records, and only those records without duplicates in the target table will be written.
- B . Each write to the orders table will only contain unique records, but newly written records may have duplicates already present in the target table.
- C . Each write to the orders table will only contain unique records; if existing records with the same key are present in the target table, these records will be overwritten.
- D . Each write to the orders table will only contain unique records; if existing records with the same key are present in the target table, the operation will tail.
- E . Each write to the orders table will run deduplication over the union of new and existing records, ensuring no duplicate records are present.
B
Explanation:
This is the correct answer because the code uses the dropDuplicates method to remove any duplicate records within each batch of data before writing to the orders table. However, this method does not check for duplicates across different batches or in the target table, so it is possible that newly written records may have duplicates already present in the target table. To avoid this, a better approach would be to use Delta Lake and perform an upsert operation using mergeInto.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Delta Lake” section; Databricks Documentation, under “DROP DUPLICATES” section.
A senior data engineer is planning large-scale data workflows. The task is to identify the considerations that form a foundation for creating scalable data models for managing large datasets. The team has listed Delta Lake capabilities and wants to determine which feature should not be considered as a core factor.
Which key feature can be ignored while evaluating Delta Lake?
- A . Delta Lake’s ability to process data in both batch and streaming modes seamlessly, providing flexibility in ingestion and processing.
- B . Delta Lake works with various data formats (Parquet, JSON, CSV) and integrates well with Spark and Databricks tools.
- C . Delta Lake optimizes metadata handling, efficiently managing billions of files and facilitating scalability to petabyte-scale datasets.
- D . Delta Lake provides limited support for monitoring and troubleshooting data pipelines, so relevant partner tools have to be identified and set up for enhanced operational efficiency.
D
Explanation:
The Databricks documentation emphasizes that Delta Lake provides robust capabilities for batch and streaming unification, scalable metadata management, and seamless integration with Databricks and Apache Spark. These are core design principles for building modern, scalable data platforms.
However, the statement claiming that Delta provides “limited support for monitoring and troubleshooting” is not valid. Delta Lake itself includes comprehensive logging, event history tracking, and data lineage via the transaction log, and integrates with Databricks’ built-in monitoring tools. Hence, such a limitation is not a design consideration when evaluating Delta Lake’s scalability. Therefore, this statement (D) can be ignored, as it does not reflect Delta Lake’s documented capabilities.
The data engineering team maintains the following code:
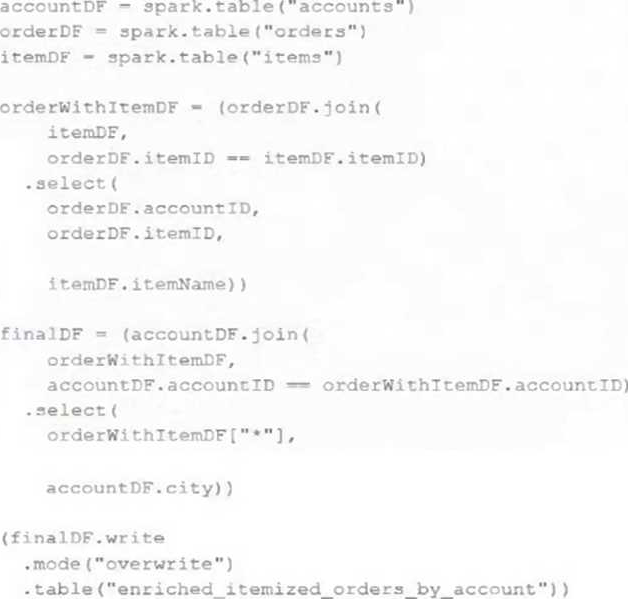
Assuming that this code produces logically correct results and the data in the source tables has been de-duplicated and validated, which statement describes what will occur when this code is executed?
- A . A batch job will update the enriched_itemized_orders_by_account table, replacing only those rows that have different values than the current version of the table, using accountID as the primary key.
- B . The enriched_itemized_orders_by_account table will be overwritten using the current valid version of data in each of the three tables referenced in the join logic.
- C . An incremental job will leverage information in the state store to identify unjoined rows in the source tables and write these rows to the enriched_iteinized_orders_by_account table.
- D . An incremental job will detect if new rows have been written to any of the source tables; if new rows are detected, all results will be recalculated and used to overwrite the enriched_itemized_orders_by_account table.
- E . No computation will occur until enriched_itemized_orders_by_account is queried; upon query materialization, results will be calculated using the current valid version of data in each of the three tables referenced in the join logic.
B
Explanation:
The provided PySpark code performs the following operations:
Reads Data from silver_customer_sales Table:
The code starts by accessing the silver_customer_sales table using the spark.table method.
Groups Data by customer_id:
The .groupBy("customer_id") function groups the data based on the customer_id column.
Aggregates Data:
The .agg() function computes several aggregate metrics for each customer_id:
F.min("sale_date").alias("first_transaction_date"): Determines the earliest sale date for the customer.
F.max("sale_date").alias("last_transaction_date"): Determines the latest sale date for the customer.
F.mean("sale_total").alias("average_sales"): Calculates the average sale amount for the customer.
F.countDistinct("order_id").alias("total_orders"): Counts the number of unique orders placed by the customer.
F.sum("sale_total").alias("lifetime_value"): Calculates the total sales amount (lifetime value) for the customer.
Writes Data to gold_customer_lifetime_sales_summary Table:
The .write.mode("overwrite").table("gold_customer_lifetime_sales_summary") command writes the aggregated data to the gold_customer_lifetime_sales_summary table.
The mode("overwrite") specifies that the existing data in the
gold_customer_lifetime_sales_summary table will be completely replaced by the new aggregated data.
Conclusion:
When this code is executed, it reads all records from the silver_customer_sales table, performs the
specified aggregations grouped by customer_id, and then overwrites the entire
gold_customer_lifetime_sales_summary table with the aggregated results. Therefore, option D
accurately describes this process: "The gold_customer_lifetime_sales_summary table will be
overwritten by aggregated values calculated from all records in the silver_customer_sales table as a
batch job."
Reference: PySpark DataFrame groupBy
PySpark Basics
Two of the most common data locations on Databricks are the DBFS root storage and external object storage mounted with dbutils.fs.mount().
Which of the following statements is correct?
- A . DBFS is a file system protocol that allows users to interact with files stored in object storage using syntax and guarantees similar to Unix file systems.
- B . By default, both the DBFS root and mounted data sources are only accessible to workspace administrators.
- C . The DBFS root is the most secure location to store data, because mounted storage volumes must have full public read and write permissions.
- D . Neither the DBFS root nor mounted storage can be accessed when using %sh in a Databricks notebook.
- E . The DBFS root stores files in ephemeral block volumes attached to the driver, while mounted directories will always persist saved data to external storage between sessions.
A
Explanation:
DBFS is a file system protocol that allows users to interact with files stored in object storage using syntax and guarantees similar to Unix file systems1. DBFS is not a physical file system, but a layer over the object storage that provides a unified view of data across different data sources1. By default, the DBFS root is accessible to all users in the workspace, and the access to mounted data sources depends on the permissions of the storage account or container2. Mounted storage volumes do not need to have full public read and write permissions, but they do require a valid connection string or access key to be provided when mounting3. Both the DBFS root and mounted storage can be accessed when using %sh in a Databricks notebook, as long as the cluster has FUSE enabled4. The DBFS root does not store files in ephemeral block volumes attached to the driver, but in the object storage associated with the workspace1. Mounted directories will persist saved data to external storage between sessions, unless they are unmounted or deleted3.
Reference: DBFS, Work with files on Azure Databricks, Mounting cloud object storage on Azure Databricks, Access DBFS with FUSE