
Practice Free Databricks Certified Professional Data Engineer Exam Online Questions
To reduce storage and compute costs, the data engineering team has been tasked with curating a series of aggregate tables leveraged by business intelligence dashboards, customer-facing applications, production machine learning models, and ad hoc analytical queries.
The data engineering team has been made aware of new requirements from a customer-facing application, which is the only downstream workload they manage entirely. As a result, an aggregate table used by numerous teams across the organization will need to have a number of fields renamed, and additional fields will also be added.
Which of the solutions addresses the situation while minimally interrupting other teams in the organization without increasing the number of tables that need to be managed?
- A . Send all users notice that the schema for the table will be changing; include in the communication the logic necessary to revert the new table schema to match historic queries.
- B . Configure a new table with all the requisite fields and new names and use this as the source for the customer-facing application; create a view that maintains the original data schema and table name by aliasing select fields from the new table.
- C . Create a new table with the required schema and new fields and use Delta Lake’s deep clone functionality to sync up changes committed to one table to the corresponding table.
- D . Replace the current table definition with a logical view defined with the query logic currently
writing the aggregate table; create a new table to power the customer-facing application. - E . Add a table comment warning all users that the table schema and field names will be changing on a given date; overwrite the table in place to the specifications of the customer-facing application.
B
Explanation:
This is the correct answer because it addresses the situation while minimally interrupting other teams in the organization without increasing the number of tables that need to be managed. The situation is that an aggregate table used by numerous teams across the organization will need to have a number of fields renamed, and additional fields will also be added, due to new requirements from a customer-facing application. By configuring a new table with all the requisite fields and new names and using this as the source for the customer-facing application, the data engineering team can meet the new requirements without affecting other teams that rely on the existing table schema and name. By creating a view that maintains the original data schema and table name by aliasing select fields from the new table, the data engineering team can also avoid duplicating data or creating additional tables that need to be managed.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Lakehouse” section; Databricks Documentation, under “CREATE VIEW” section.
The data engineering team has configured a Databricks SQL query and alert to monitor the values in
a Delta Lake table. The recent_sensor_recordings table contains an identifying sensor_id alongside the timestamp and temperature for the most recent 5 minutes of recordings.
The below query is used to create the alert:
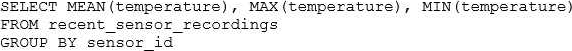
The query is set to refresh each minute and always completes in less than 10 seconds. The alert is set to trigger when mean (temperature) > 120. Notifications are triggered to be sent at most every 1 minute.
If this alert raises notifications for 3 consecutive minutes and then stops, which statement must be true?
- A . The total average temperature across all sensors exceeded 120 on three consecutive executions of the query
- B . The recent_sensor_recordingstable was unresponsive for three consecutive runs of the query
- C . The source query failed to update properly for three consecutive minutes and then restarted
- D . The maximum temperature recording for at least one sensor exceeded 120 on three consecutive executions of the query
- E . The average temperature recordings for at least one sensor exceeded 120 on three consecutive executions of the query
E
Explanation:
This is the correct answer because the query is using a GROUP BY clause on the sensor_id column, which means it will calculate the mean temperature for each sensor separately. The alert will trigger when the mean temperature for any sensor is greater than 120, which means at least one sensor had an average temperature above 120 for three consecutive minutes. The alert will stop when the mean temperature for all sensors drops below 120.
Verified Reference: [Databricks Certified Data Engineer
Professional], under “SQL Analytics” section; Databricks Documentation, under “Alerts” section.
A production cluster has 3 executor nodes and uses the same virtual machine type for the driver and executor.
When evaluating the Ganglia Metrics for this cluster, which indicator would signal a bottleneck caused by code executing on the driver?
- A . The five Minute Load Average remains consistent/flat
- B . Bytes Received never exceeds 80 million bytes per second
- C . Total Disk Space remains constant
- D . Network I/O never spikes
- E . Overall cluster CPU utilization is around 25%
E
Explanation:
This is the correct answer because it indicates a bottleneck caused by code executing on the driver. A bottleneck is a situation where the performance or capacity of a system is limited by a single component or resource. A bottleneck can cause slow execution, high latency, or low throughput. A production cluster has 3 executor nodes and uses the same virtual machine type for the driver and executor. When evaluating the Ganglia Metrics for this cluster, one can look for indicators that show how the cluster resources are being utilized, such as CPU, memory, disk, or network. If the overall cluster CPU utilization is around 25%, it means that only one out of the four nodes (driver + 3 executors) is using its full CPU capacity, while the other three nodes are idle or underutilized. This suggests that the code executing on the driver is taking too long or consuming too much CPU resources, preventing the executors from receiving tasks or data to process. This can happen when the code has driver-side operations that are not parallelized or distributed, such as collecting large amounts of data to the driver, performing complex calculations on the driver, or using non-Spark libraries on the driver.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Spark Core” section; Databricks Documentation, under “View cluster status and event logs – Ganglia metrics” section; Databricks Documentation, under “Avoid collecting large RDDs” section.
In a Spark cluster, the driver node is responsible for managing the execution of the Spark application, including scheduling tasks, managing the execution plan, and interacting with the cluster manager. If the overall cluster CPU utilization is low (e.g., around 25%), it may indicate that the driver node is not utilizing the available resources effectively and might be a bottleneck.
The data engineering team is migrating an enterprise system with thousands of tables and views into the Lakehouse. They plan to implement the target architecture using a series of bronze, silver, and gold tables. Bronze tables will almost exclusively be used by production data engineering workloads, while silver tables will be used to support both data engineering and machine learning workloads. Gold tables will largely serve business intelligence and reporting purposes. While personal identifying information (PII) exists in all tiers of data, pseudonymization and anonymization rules are in place for all data at the silver and gold levels.
The organization is interested in reducing security concerns while maximizing the ability to collaborate across diverse teams.
Which statement exemplifies best practices for implementing this system?
- A . Isolating tables in separate databases based on data quality tiers allows for easy permissions management through database ACLs and allows physical separation of default storage locations for managed tables.
- B . Because databases on Databricks are merely a logical construct, choices around database organization do not impact security or discoverability in the Lakehouse.
- C . Storinq all production tables in a single database provides a unified view of all data assets available throughout the Lakehouse, simplifying discoverability by granting all users view privileges on this database.
- D . Working in the default Databricks database provides the greatest security when working with managed tables, as these will be created in the DBFS root.
- E . Because all tables must live in the same storage containers used for the database they’re created in, organizations should be prepared to create between dozens and thousands of databases depending on their data isolation requirements.
A
Explanation:
This is the correct answer because it exemplifies best practices for implementing this system. By isolating tables in separate databases based on data quality tiers, such as bronze, silver, and gold, the data engineering team can achieve several benefits. First, they can easily manage permissions for different users and groups through database ACLs, which allow granting or revoking access to databases, tables, or views. Second, they can physically separate the default storage locations for managed tables in each database, which can improve performance and reduce costs. Third, they can provide a clear and consistent naming convention for the tables in each database, which can improve discoverability and usability.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Lakehouse” section; Databricks Documentation, under “Database object privileges” section.
A data engineer is building a Lakeflow Declarative Pipelines pipeline to process healthcare claims data.
A metadata JSON file defines data quality rules for multiple tables, including:
{
"claims": [
{"name": "valid_patient_id", "constraint": "patient_id IS NOT NULL"},
{"name": "non_negative_amount", "constraint": "claim_amount >= 0"}
]
}
The pipeline must dynamically apply these rules to the claims table without hardcoding the rules.
How should the data engineer achieve this?
- A . Load the JSON metadata, loop through its entries, and apply expectations using dlt.expect_all.
- B . Invoke an external API to validate records against the metadata rules.
- C . Reference each expectation with @dlt.expect decorators in the table declaration.
- D . Use a SQL CONSTRAINT block referencing the JSON file path.
A
Explanation:
Lakeflow Declarative Pipelines provide the expect_all method for programmatically applying multiple data quality expectations at once. The documentation explains that @dlt.expect_all accepts a dictionary of expectation names mapped to SQL constraints, allowing rules to be dynamically loaded from metadata such as JSON files. This ensures that pipelines remain maintainable and scalable without needing to hardcode individual @dlt.expect decorators. The event logs will track each expectation’s pass and fail counts individually, making it auditable. Other options are incorrect: invoking an external API introduces unnecessary complexity, individual decorators require hardcoding, and SQL constraints cannot dynamically reference external JSON.
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.
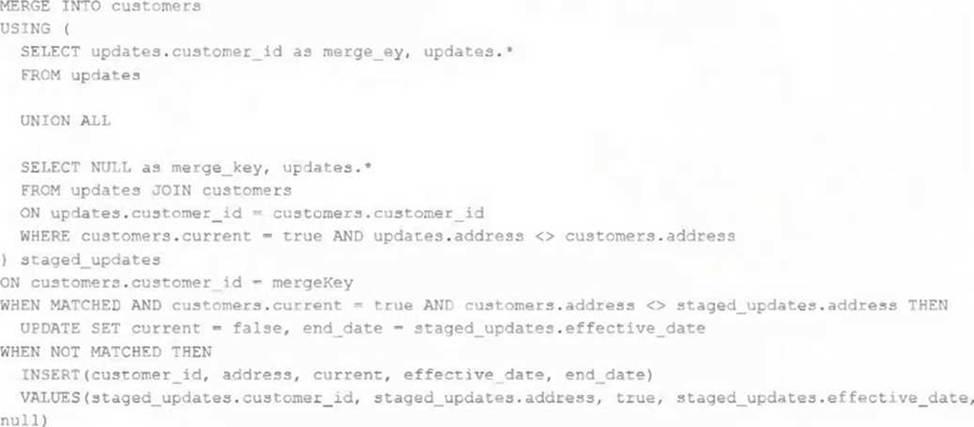
Which statement describes this implementation?
- A . The customers table is implemented as a Type 3 table; old values are maintained as a new column alongside the current value.
- B . The customers table is implemented as a Type 2 table; old values are maintained but marked as no longer current and new values are inserted.
- C . The customers table is implemented as a Type 0 table; all writes are append only with no changes to existing values.
- D . The customers table is implemented as a Type 1 table; old values are overwritten by new values and no history is maintained.
- E . The customers table is implemented as a Type 2 table; old values are overwritten and new customers are appended.
B
Explanation:
The logic uses the MERGE INTO command to merge new records from the view updates into the table customers. The MERGE INTO command takes two arguments: a target table and a source table or view. The command also specifies a condition to match records between the target and the source, and a set of actions to perform when there is a match or not. In this case, the condition is to match records by customer_id, which is the primary key of the customers table. The actions are to update the existing record in the target with the new values from the source, and set the current_flag to false to indicate that the record is no longer current; and to insert a new record in the target with the new values from the source, and set the current_flag to true to indicate that the record is current. This means that old values are maintained but marked as no longer current and new values are inserted, which is the definition of a Type 2 table.
Verified Reference: [Databricks Certified Data Engineer Professional], under “Delta Lake” section; Databricks Documentation, under “Merge Into (Delta Lake on Databricks)” section.
What statement is true regarding the retention of job run history?
- A . It is retained until you export or delete job run logs
- B . It is retained for 30 days, during which time you can deliver job run logs to DBFS or S3
- C . t is retained for 60 days, during which you can export notebook run results to HTML
- D . It is retained for 60 days, after which logs are archived
- E . It is retained for 90 days or until the run-id is re-used through custom run configuration
A data engineer needs to install the PyYAML Python package within an air-gapped Databricks environment. The workspace has no direct internet access to PyPI. The engineer has downloaded the .whl file locally and wants it available automatically on all new clusters.
Which approach should the data engineer use?
- A . Upload the PyYAML .whl file to the user home directory and create a cluster-scoped init script to install it.
- B . Upload the PyYAML .whl file to a Unity Catalog Volume, ensure it’s allow-listed, and create a cluster-scoped init script that installs it from that path.
- C . Set up a private PyPI repository and install via pip index URL.
- D . Add the .whl file to Databricks Git Repos and assume automatic installation.
B
Explanation:
For secure, air-gapped Databricks deployments, the recommended practice is to host dependency files such as .whl packages in Unity Catalog Volumes ― a managed storage layer governed by Unity Catalog.
Once stored in a volume, these files can be safely referenced from cluster-scoped init scripts, which automatically execute installation commands (e.g., pip install /Volumes/catalog/schema/path/PyYAML.whl) during cluster startup.
This ensures consistent environment setup across clusters and compliance with data governance rules.
User directories (A) lack enterprise security controls; private repositories (C) are not viable in air-gapped setups; and Git repos (D) do not trigger package installation. Therefore, B is the correct and officially approved method.
A company has a task management system that tracks the most recent status of tasks. The system takes task events as input and processes events in near real-time using Lakeflow Declarative Pipelines. A new task event is ingested into the system when a task is created or the task status is changed. Lakeflow Declarative Pipelines provides a streaming table (tasks_status) for BI users to query.
The table represents the latest status of all tasks and includes 5 columns:
task_id (unique for each task)
task_name
task_owner
task_status
task_event_time
The table enables three properties: deletion vectors, row tracking, and change data feed (CDF).
A data engineer is asked to create a new Lakeflow Declarative Pipeline to enrich the tasks_status table in near real-time by adding one additional column representing task_owner’s department, which can be looked up from a static dimension table (employee).
How should this enrichment be implemented?
- A . Create a new Lakeflow Declarative Pipeline: use the readStream() function to read tasks_status table; enrich with the employee table; store the result in a new streaming table.
- B . Create a new Lakeflow Declarative Pipeline: use readStream() function with option readChangeFeed to read tasks_status table CDF; enrich with the employee table; create a new streaming table as the result table and use apply_changes() function to process the changes from the enriched CDF.
- C . Create a new Lakeflow Declarative Pipeline: use the read() function to read tasks_status table; enrich with employee table; store the result in a materialized view.
- D . Create a new Lakeflow Declarative Pipeline: use the readStream() function with the option skipChangeCommits to read the tasks_status table; enrich with the employee table; store the result in a new streaming table.
B
Explanation:
Change Data Feed (CDF) allows downstream consumers to read incremental changes (inserts, updates, deletes) from a Delta table. The documentation explains that when streaming from a Delta table with CDF enabled, developers can use readStream().option("readChangeFeed","true") to capture incremental events. For maintaining a derived table with enrichment logic, the recommended practice is to use apply_changes(), which applies CDC semantics (insert/update/delete) correctly to the target streaming table. By joining with the static employee dimension, enriched rows are generated before being merged into the new streaming target. This ensures correctness, scalability, and minimal latency. Batch reads or skipping commits do not maintain correctness for CDC pipelines.
A Databricks SQL dashboard has been configured to monitor the total number of records present in a collection of Delta Lake tables using the following query pattern:
SELECT COUNT (*) FROM table –
Which of the following describes how results are generated each time the dashboard is updated?
- A . The total count of rows is calculated by scanning all data files
- B . The total count of rows will be returned from cached results unless REFRESH is run
- C . The total count of records is calculated from the Delta transaction logs
- D . The total count of records is calculated from the parquet file metadata
- E . The total count of records is calculated from the Hive metastore
C
Explanation:
https://delta.io/blog/2023-04-19-faster-aggregations-metadata/#:~:text=You%20can%20get%20the%20number,a%20given%20Delta%20table%20version.