
Practice Free DVA-C02 Exam Online Questions
A company runs continuous integration/continuous delivery (CI/CD) pipelines for its application on AWS CodePipeline. A developer must write unit tests and run them as part of the pipelines before staging the artifacts for testing.
How should the developer incorporate unit tests as part of CI/CD pipelines?
- A . Create a separate CodePipeline pipeline to run unit tests.
- B . Update the AWS CodeBuild build specification to include a phase for running unit tests.
- C . Install the AWS CodeDeploy agent on an Amazon EC2 instance to run unit tests.
- D . Create a testing branch in a git repository for the pipelines to run unit tests.
A developer maintains a serverless application that uses an Amazon API Gateway REST API to invoke an AWS Lambda function by using a non-proxy integration. The Lambda function returns data, which is stored in Amazon DynamoDB.
Several application users begin to receive intermittent errors from the API. The developer examines Amazon CloudWatch Logs for the Lambda function and discovers several ProvisionedThroughputExceededException errors.
The developer needs to resolve the errors and ensure that the errors do not reoccur.
- A . Use provisioned capacity mode for the DynamoDB table, and assign sufficient capacity units.
Configure the Lambda function to retry requests with exponential backoff. - B . Update the REST API to send requests on an Amazon SQS queue. Configure the Lambda function to process requests from the queue.
- C . Configure a usage plan for the REST API.
- D . Update the REST API to invoke the Lambda function asynchronously.
A
Explanation:
Comprehensive and Detailed Step-by-Step
Option A: Provisioned Capacity with Exponential Backoff:
Using provisioned capacity ensures sufficient throughput for the DynamoDB table.
Configuring the Lambda function to implement exponential backoff retries reduces the chance of exceeding capacity during peak usage.
This combination addresses the root cause (ProvisionedThroughputExceededException) and prevents errors without overprovisioning.
Why Other Options Are Incorrect:
Option B: Using SQS adds unnecessary latency and complexity. The issue lies in DynamoDB throughput, not request management.
Option C: A usage plan for the API does not address throughput issues in DynamoDB.
Option D: Invoking the Lambda function asynchronously does not resolve the DynamoDB capacity issue and might lead to delayed processing.
Reference: DynamoDB Provisioned Throughput Documentation
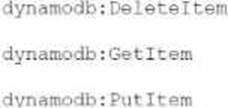
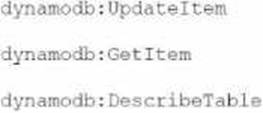
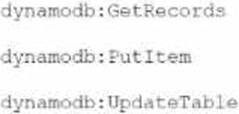
A developer is working on an AWS Lambda function that accesses Amazon DynamoDB. The Lambda function must retrieve an item and update some of its attributes, or create the item if it does not exist. The Lambda function has access to the primary key.
Which IAM permissions should the developer request for the Lambda function to achieve this functionality?
A)
B)
C)
D)
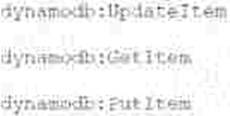
- A . Option A
- B . Option B
- C . Option C
- D . Option D
B
Explanation:
Requirement Summary:
Lambda function:
Retrieves an item from DynamoDB
Updates its attributes or creates it if it does not exist
Has primary key
Needs minimum required IAM permissions
Analysis of Required Permissions:
To get an item and update it or create it if it doesn’t exist, the Lambda function must use the PutItem or UpdateItem API, and read with GetItem.
Valid API options:
GetItem: Read the item from the table.
UpdateItem: Update existing item attributes or insert if it doesn’t exist (with UpdateExpression and ConditionExpression).
When UpdateItem is used without a conditional check for existence, it can create a new item if it does not exist (acts like upsert).
DescribeTable: (Optional) Used if you need table metadata (not strictly required here).
Evaluate the Choices:
Option A:
DeleteItem C Not needed
GetItem C
PutItem C (can create/replace but not partial update)
Close, but PutItem overwrites the full item, not update-in-place. Acceptable, but UpdateItem is better suited.
Option B:
UpdateItem C Required to modify attributes or insert new item GetItem C Required to check existence or read data DescribeTable C Optional, but not harmful BEST FIT C Matches the update-or-create logic.
Option C:
GetRecords C This is used for DynamoDB Streams, not standard GetItem
PutItem C
UpdateTable C Used to change table settings, not data manipulation
Incorrect usage context
Option D:
UpdateItem, GetItem, PutItem C all valid
But UpdateItem alone is sufficient; including PutItem might not be necessary Also, image is faded (possibly invalid), and it’s redundant
UpdateItem API:
https: //docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_UpdateItem.html
PutItem vs UpdateItem:
https: //docs.aws.amazon.com/amazondynamodb/latest/developerguide/WorkingWithItems.html
IAM actions for DynamoDB: https: //docs.aws.amazon.com/service-authorization/latest/reference/list_amazondynamodb.html
A developer has created a large AWS Lambda function. Deployment of the function Is failing because of an InvalidParameterValueException error. The error message indicates that the unzipped size of the function exceeds the maximum supported value.
Which actions can the developer take to resolve this error? (Select TWO.)
- A . Submit a quota increase request to AWS Support to increase the function to the required size.
- B . Use a compression algorithm that is more efficient than ZIP.
- C . Break up the function into multiple smaller functions.
- D . Zip the .zip file twice to compress the file more.
- E . Move common libraries, function dependencies, and custom runtimes into Lambda layers.
A developer has created a large AWS Lambda function. Deployment of the function Is failing because of an InvalidParameterValueException error. The error message indicates that the unzipped size of the function exceeds the maximum supported value.
Which actions can the developer take to resolve this error? (Select TWO.)
- A . Submit a quota increase request to AWS Support to increase the function to the required size.
- B . Use a compression algorithm that is more efficient than ZIP.
- C . Break up the function into multiple smaller functions.
- D . Zip the .zip file twice to compress the file more.
- E . Move common libraries, function dependencies, and custom runtimes into Lambda layers.
A developer is using AWS AppConfig to manage feature flags for an application. The developer needs to enable a new premium feature only for a specific group of users based on the IDs of the users.
Which solution will meet these requirements with the LEAST development effort?
- A . Use a single AWS AppConfig feature flag without any variants. Implement user ID checks in the application to control access to the premium feature.
- B . Create separate AWS AppConfig feature flags for each user group. Assign values to the feature flags.
- C . Create an AWS AppConfig feature flag. Define multiple variants. Set up rules to target the specific
user group based on the IDs of the users. - D . Configure AWS AppConfig to use an external database to store user IDs. Retrieve the user IDs during flag evaluation.
C
Explanation:
The correct answer is C because AWS AppConfig feature flags support variants and targeting rules, which allow developers to enable different feature behavior for different audiences with minimal custom code. In this scenario, the requirement is to enable a premium feature only for a specific group of users identified by their user IDs. AppConfig can handle this directly by defining multiple flag variants and applying rules that target the intended users.
This is the solution with the least development effort because the targeting logic is managed in AppConfig instead of being implemented and maintained in the application code. AWS documentation for AppConfig feature flags emphasizes dynamic control of feature rollout, audience targeting, and safe configuration management. By configuring the targeting rules centrally, the developer can change which users receive the premium feature without redeploying the application.
Option A is less desirable because it pushes the user ID evaluation logic into the application, increasing development and maintenance effort.
Option B is more cumbersome because creating separate feature flags for every user group does not scale well and adds administrative overhead.
Option D is not the intended AppConfig pattern and introduces unnecessary complexity by requiring an external database lookup during flag evaluation.
Using one feature flag with multiple variants and targeting rules is the cleanest and most AWS-native design for selective rollout to a defined user segment. It keeps the configuration centralized, reduces code changes, and supports flexible future updates.
Therefore, the best solution is C.
A developer needs to troubleshoot an AWS Lambda function in a development environment. The Lambda function is configured in VPC mode and needs to connect to an existing Amazon RDS for SOL Server DB instance. The DB instance is deployed in a private subnet and accepts connections by using port 1433.
When the developer tests the function, the function reports an error when it tries to connect to the database.
Which combination of steps should the developer take to diagnose this issue? (Select TWO.)
- A . Check that the function’s security group has outbound access on port 1433 to the DB instance’s security group. Check that the DB instance’s security group has inbound access on port 1433 from the function’s security group.
- B . Check that the function’s security group has Inbound access on port 1433 from the DB Instance’s security group. Check that the DB instance’s security group has outbound access on port 1433 to the function’s security group.
- C . Check that the VPC is set up for a NAT gateway. Check that the DB instance has the public access option turned on.
- D . Check that the function’s execution role permissions include rds: DescribeDBInstances, rds:
ModifyDB Instance, and rds: DescribeDBSecurityGroups for the DB instance. - E . Check that the function’s execution rote permissions include ec2: CreateNetworklnterface. ec2:
DescribeNetworklnterfaces. and ec2: DeleteNetworklnterface.
A developer is creating an AWS Lambda function. The Lambda function needs an external library to connect to a third-party solution The external library is a collection of files with a total size of 100 MB The developer needs to make the external library available to the Lambda execution environment and reduce the Lambda package space
Which solution will meet these requirements with the LEAST operational overhead?
- A . Create a Lambda layer to store the external library Configure the Lambda function to use the layer
- B . Create an Amazon S3 bucket Upload the external library into the S3 bucket. Mount the S3 bucket folder in the Lambda function Import the library by using the proper folder in the mount point.
- C . Load the external library to the Lambda function’s /tmp directory during deployment of the Lambda package. Import the library from the /tmp directory.
- D . Create an Amazon Elastic File System (Amazon EFS) volume. Upload the external library to the EFS volume Mount the EFS volume in the Lambda function. Import the library by using the proper folder in the mount point.
A
Explanation:
Lambda Layers: These are designed to package dependencies that you can share across functions.
How to Use:
Create a layer, upload your 100MB library as a zip.
Attach the layer to your function.
In your function code, import the library from the standard layer path.
Reference: Lambda Layers: https: //docs.aws.amazon.com/lambda/latest/dg/configuration-layers.html
A company is building a web application on AWS. When a customer sends a request, the application will generate reports and then make the reports available to the customer within one hour. Reports should be accessible to the customer for 8 hours. Some reports are larger than 1 MB. Each report is unique to the customer. The application should delete all reports that are older than 2 days.
Which solution will meet these requirements with the LEAST operational overhead?
- A . Generate the reports and then store the reports as Amazon DynamoDB items that have a specified TTL. Generate a URL that retrieves the reports from DynamoDB. Provide the URL to customers through the web application.
- B . Generate the reports and then store the reports in an Amazon S3 bucket that uses server-side encryption. Attach the reports to an Amazon Simple Notification Service (Amazon SNS) message. Subscribe the customer to email notifications from Amazon SNS.
- C . Generate the reports and then store the reports in an Amazon S3 bucket that uses server-side encryption. Generate a presigned URL that contains an expiration date Provide the URL to customers through the web application. Add S3 Lifecycle configuration rules to the S3 bucket to delete old reports.
- D . Generate the reports and then store the reports in an Amazon RDS database with a date stamp. Generate an URL that retrieves the reports from the RDS database. Provide the URL to customers through the web application. Schedule an hourly AWS Lambda function to delete database records that have expired date stamps.
C
Explanation:
This solution will meet the requirements with the least operational overhead because it uses Amazon S3 as a scalable, secure, and durable storage service for the reports. The presigned URL will allow customers to access their reports for a limited time (8 hours) without requiring additional authentication. The S3 Lifecycle configuration rules will automatically delete the reports that are older than 2 days, reducing storage costs and complying with the data retention policy.
Option A is not optimal because it will incur additional costs and complexity to store the reports as DynamoDB items, which have a size limit of 400 KB.
Option B is not optimal because it will not provide customers with access to their reports within one hour, as Amazon SNS email delivery is not guaranteed.
Option D is not optimal because it will require more operational overhead to manage an RDS database and a Lambda function for storing and deleting the reports.
Reference: Amazon S3 Presigned URLs, Amazon S3 Lifecycle
A mobile app stores blog posts in an Amazon DynacnoDB table Millions of posts are added every day and each post represents a single item in the table. The mobile app requires only recent posts. Any
post that is older than 48 hours can be removed.
What is the MOST cost-effective way to delete posts that are older man 48 hours?
- A . For each item add a new attribute of type String that has a timestamp that is set to the blog post creation time. Create a script to find old posts with a table scan and remove posts that are order than 48 hours by using the Balch Write ltem API operation. Schedule a cron job on an Amazon EC2 instance once an hour to start the script.
- B . For each item add a new attribute of type. String that has a timestamp that its set to the blog post creation time. Create a script to find old posts with a table scan and remove posts that are Oder than 48 hours by using the Batch Write item API operating. Place the script in a container image. Schedule an Amazon Elastic Container Service (Amazon ECS) task on AWS Far gate that invokes the container every 5 minutes.
- C . For each item, add a new attribute of type Date that has a timestamp that is set to 48 hours after the blog post creation time. Create a global secondary index (GSI) that uses the new attribute as a sort key. Create an AWS Lambda function that references the GSI and removes expired items by using the Batch Write item API operation Schedule me function with an Amazon CloudWatch event every minute.
- D . For each item add a new attribute of type. Number that has timestamp that is set to 48 hours after the blog post. creation time Configure the DynamoDB table with a TTL that references the new attribute.
D
Explanation:
This solution will meet the requirements by using the Time to Live (TTL) feature of DynamoDB, which enables automatically deleting items from a table after a certain time period. The developer can add a new attribute of type Number that has a timestamp that is set to 48 hours after the blog post creation time, which represents the expiration time of the item. The developer can configure the DynamoDB table with a TTL that references the new attribute, which instructs DynamoDB to delete the item when the current time is greater than or equal to the expiration time. This solution is also cost-effective as it does not incur any additional charges for deleting expired items.
Option A is not optimal because it will create a script to find and remove old posts with a table scan and a batch write item API operation, which may consume more read and write capacity units and incur more costs.
Option B is not optimal because it will use Amazon Elastic Container Service (Amazon ECS) and AWS Fargate to run the script, which may introduce additional costs and complexity for managing and scaling containers.
Option C is not optimal because it will create a global secondary index (GSI) that uses the expiration time as a sort key, which may consume more storage space and incur more costs.
Reference: Time To Live, Managing DynamoDB Time To Live (TTL)