
Practice Free DP-700 Exam Online Questions
DRAG DROP
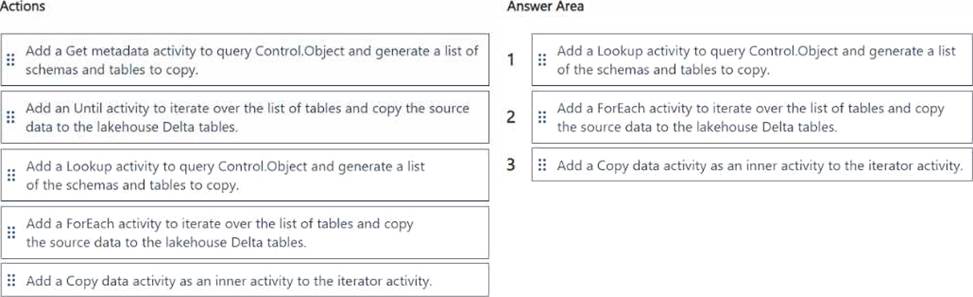
You are building a data loading pattern by using a Fabric data pipeline. The source is an Azure SQL database that contains 25 tables. The destination is a lakehouse.
In a warehouse, you create a control table named Control.Object as shown in the exhibit. (Click the Exhibit tab.)
You need to build a data pipeline that will support the dynamic ingestion of the tables listed in the control table by using a single execution.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

HOTSPOT
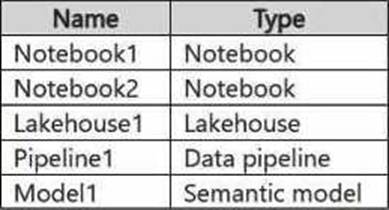
You have a Fabric workspace named Workspace1 that contains the items shown in the following table.
For Model1, the Keep your Direct Lake data up to date option is disabled.
You need to configure the execution of the items to meet the following requirements:
– Notebook1 must execute every weekday at 8:00 AM.
– Notebook2 must execute when a file is saved to an Azure Blob Storage container.
– Model1 must refresh when Notebook1 has executed successfully.
How should you orchestrate each item? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database.
The table contains the following columns:
– BikepointID
– Street
– Neighbourhood
– No_Bikes
– No_Empty_Docks
– Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be ordered by No_Bikes in ascending order.
Solution: You use the following code segment:

Does this meet the goal?
- A . Yes
- B . no
B
Explanation:
This code does not meet the goal because it uses order by, which is not valid in KQL.
The correct term in KQL is sort by.
Correct code should look like:

Your company has a sales department that uses two Fabric workspaces named Workspace1 and Workspace2.
The company decides to implement a domain strategy to organize the workspaces.
You need to ensure that a user can perform the following tasks:
Create a new domain for the sales department.
Create two subdomains: one for the east region and one for the west region.
Assign Workspace1 to the east region subdomain.
Assign Workspace2 to the west region subdomain.
The solution must follow the principle of least privilege.
Which role should you assign to the user?
- A . workspace Admin
- B . domain admin
- C . domain contributor
- D . Fabric admin
B
Explanation:
To implement a domain strategy and manage subdomains within Fabric, the domain admin role is the appropriate role for the user.
A domain admin has the permissions necessary to:
Create a new domain (for the sales department).
Create subdomains (for the east and west regions).
Assign workspaces (such as Workspace1 and Workspace2) to the appropriate subdomains.
The domain admin role allows for managing the structure and organization of workspaces in the context of domains and subdomains while maintaining the principle of least privilege by limiting the user’s access to managing the domain structure specifically.
You have a Fabric workspace that contains a warehouse named Warehouse1.
While monitoring Warehouse1, you discover that query performance has degraded during the last 60 minutes.
You need to isolate all the queries that were run during the last 60 minutes. The results must include the username of the users that submitted the queries and the query statements.
What should you use?
- A . the Microsoft Fabric Capacity Metrics app
- B . views from the queryinsights schema
- C . Query activity
- D . the sys.dm_exec_requests dynamic management view
DRAG DROP
You have a KQL database that contains a table named Readings.
You need to build a KQL query to compare the Meter-Reading value of each row to the previous row base on the ilmestamp value
A sample of the expected output is shown in the following table.



HOTSPOT
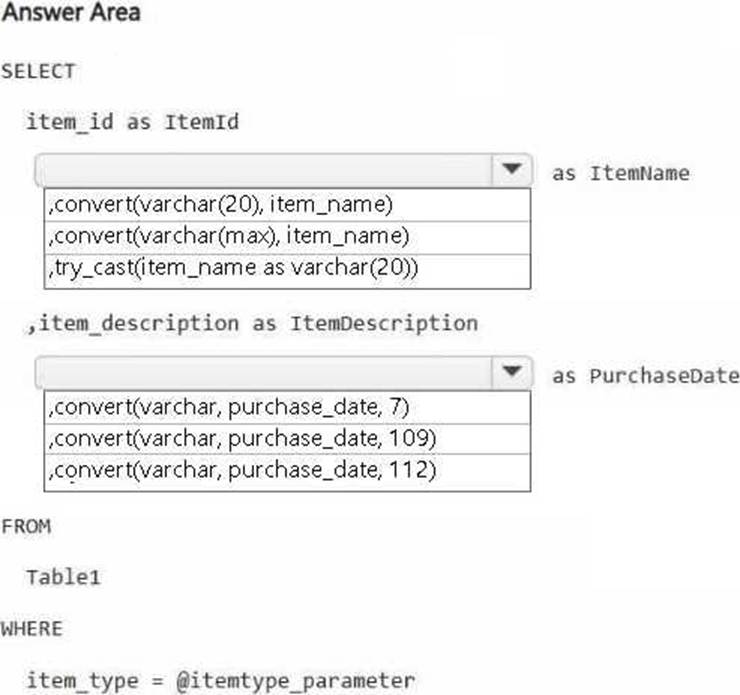
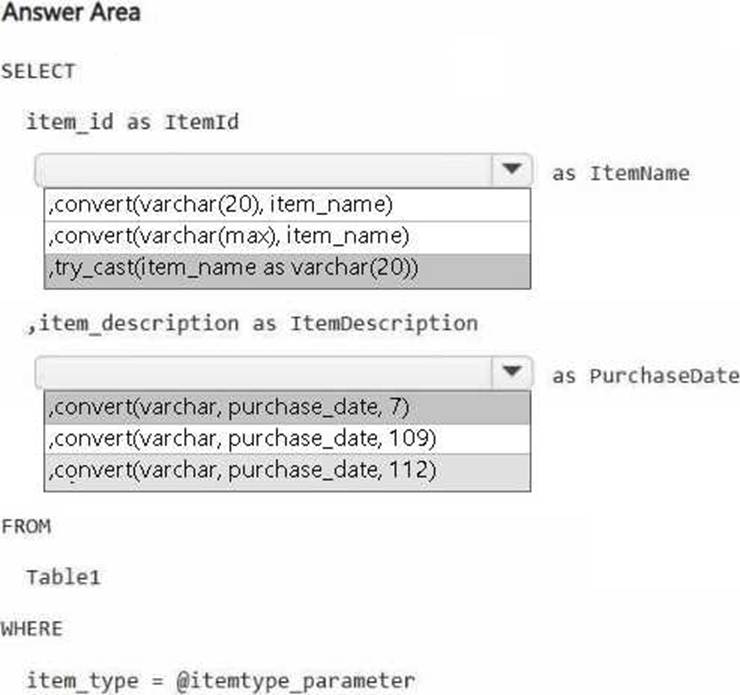
You have a Fabric workspace.
You are debugging a statement and discover the following issues:
– Sometimes, the statement fails to return all the expected rows.
– The PurchaseDate output column is NOT in the expected format of mmm dd, yy.
You need to resolve the issues. The solution must ensure that the data types of the results are retained. The results can contain blank cells.
How should you complete the statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have an Azure key vault named KeyVaultl that contains secrets.
You have a Fabric workspace named Workspace-!. Workspace! contains a notebook named Notebookl that performs the following tasks:
• Loads stage data to the target tables in a lakehouse
• Triggers the refresh of a semantic model
You plan to add functionality to Notebookl that will use the Fabric API to monitor the semantic model refreshes. You need to retrieve the registered application ID and secret from KeyVaultl to generate the authentication token.
Solution: You use the following code segment:
Use notebookutils.credentials.getSecret and specify the key vault URL and key vault secret.
Does this meet the goal?
- A . Yes
- B . No
You have a Fabric workspace that contains a warehouse named Warehouse1.
You have an on-premises Microsoft SQL Server database named Database1 that is accessed by using an on-premises data gateway.
You need to copy data from Database1 to Warehouse1.
Which item should you use?
- A . a Dataflow Gen1 dataflow
- B . a data pipeline
- C . a KQL queryset
- D . a notebook
B
Explanation:
To copy data from an on-premises Microsoft SQL Server database (Database1) to a warehouse (Warehouse1) in Microsoft Fabric, the best option is to use a data pipeline. A data pipeline in Fabric allows for the orchestration of data movement, from source to destination, using connectors, transformations, and scheduled workflows. Since the data is being transferred from an on-premises database and requires the use of a data gateway, a data pipeline provides the appropriate framework to facilitate this data movement efficiently and reliably.
You need to ensure that WorkspaceA can be configured for source control.
Which two actions should you perform?
Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Assign WorkspaceA to Capl.
- B . From Tenant setting, set Users can synchronize workspace items with their Git repositories to Enabled
- C . Configure WorkspaceA to use a Premium Per User (PPU) license
- D . From Tenant setting, set Users can sync workspace items with GitHub repositories to Enabled