
Practice Free DP-700 Exam Online Questions
You have a Fabric workspace that contains a lakehouse named Lakehouse1. Lakehouse1 contains a Delta table named Table1.
You analyze Table1 and discover that Table1 contains 2,000 Parquet files of 1 MB each.
You need to minimize how long it takes to query Table1.
What should you do?
- A . Disable V-Order and run the OPTIMIZE command.
- B . Disable V-Order and run the VACUUM command.
- C . Run the OPTIMIZE and VACUUM commands.
C
Explanation:
Problem Overview:
Table1 has 2,000 small Parquet files (1 MB each).
Query performance suffers when the table contains numerous small files because the query engine must process each file individually, leading to significant overhead.
Solution:
To improve performance, file compaction is necessary to reduce the number of small files and create larger, optimized files.
Commands and Their Roles:
OPTIMIZE Command:
– Compacts small Parquet files into larger files to improve query performance.
– It supports optional features like V-Order, which organizes data for efficient scanning. VACUUM Command:
– Removes old, unreferenced data files and metadata from the Delta table.
– Running VACUUM after OPTIMIZE ensures unnecessary files are cleaned up, reducing storage overhead and improving performance.
Exhibit.
You have a Fabric workspace that contains a write-intensive warehouse named DW1. DW1 stores staging tables that are used to load a dimensional model. The tables are often read once, dropped, and then recreated to process new data.
You need to minimize the load time of DW1.
What should you do?
- A . Disable V-Order.
- B . Drop statistics.
- C . Enable V-O-der.
- D . Create statistics.
You have a Fabric capacity that contains a workspace named Workspace1. Workspace1 contains a lakehouse named Lakehouse1, a data pipeline, a notebook, and several Microsoft Power BI reports.
A user named User1 wants to use SQL to analyze the data in Lakehouse1.
You need to configure access for User1. The solution must meet the following requirements:
Provide User1 with read access to the table data in Lakehouse1.
Prevent User1 from using Apache Spark to query the underlying files in Lakehouse1.
Prevent User1 from accessing other items in Workspace1.
What should you do?
- A . Share Lakehouse1 with User1 directly and select Read all SQL endpoint data.
- B . Assign User1 the Viewer role for Workspace1. Share Lakehouse1 with User1 and select Read all SQL endpoint data.
- C . Share Lakehouse1 with User1 directly and select Build reports on the default semantic model.
- D . Assign User1 the Member role for Workspace1. Share Lakehouse1 with User1 and select Read all SQL endpoint data.
A
Explanation:
To meet the specified requirements for User1, the solution must ensure:
Read access to the table data in Lakehouse1: User1 needs permission to access the data within Lakehouse1. By sharing Lakehouse1 with User1 and selecting the Read all SQL endpoint data option, User1 will be able to query the data via SQL endpoints.
Prevent Apache Spark usage: By sharing the lakehouse directly and selecting the SQL endpoint data option, you specifically enable SQL-based access to the data, preventing User1 from using Apache Spark to query the data.
Prevent access to other items in Workspace1: Assigning User1 the Viewer role for Workspace1 ensures that User1 can only view the shared items (in this case, Lakehouse1), without accessing other resources such as notebooks, pipelines, or Power BI reports within Workspace1.
This approach provides the appropriate level of access while restricting User1 to only the required resources and preventing access to other workspace assets.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Fabric eventstream that loads data into a table named Bike_Location in a KQL database.
The table contains the following columns:
– BikepointID
– Street
– Neighbourhood
– No_Bikes
– No_Empty_Docks
– Timestamp
You need to apply transformation and filter logic to prepare the data for consumption. The solution must return data for a neighbourhood named Sands End when No_Bikes is at least 15. The results must be ordered by No_Bikes in ascending order.
Solution: You use the following code segment:

Does this meet the goal?
- A . Yes
- B . no
B
Explanation:
This code does not meet the goal because it uses order by, which is not valid in KQL.
The correct term in KQL is sort by.
Correct code should look like:

HOTSPOT
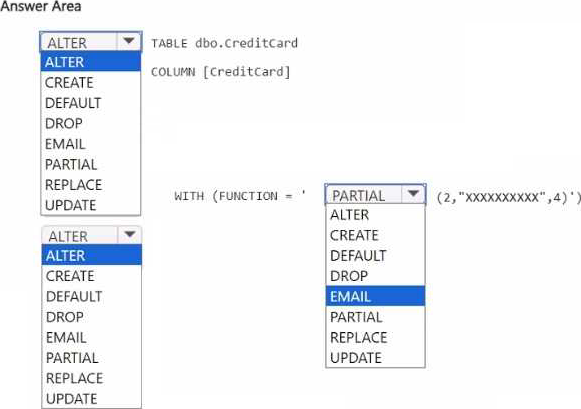
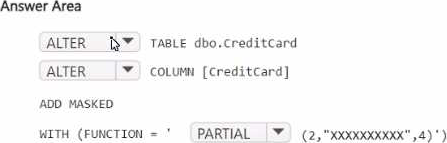
You have a Fabric workspace named Workspace1 that contains a warehouse named Warehouse2. A team of data analysts has Viewer role access to Workspace1.
You create a table by running the following statement.

You need to ensure that the team can view only the first two characters and the last four characters of the Creditcard attribute.
How should you complete the statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have a Fabric workspace that contains an event house and a KQL database named Database1.
Database1 has the following:
– A table named Table1
– A table named Table2
– An update policy named Policy1
Policy1 sends data from Table1 to Table2.
The following is a sample of the data in Table2.

Recently, the following actions were performed on Table1:
– An additional element named temperature was added to the StreamData column.
– The data type of the Timestamp column was changed to date.
– The data type of the DeviceId column was changed to string.
You plan to load additional records to Table2.
Which two records will load from Table1 to Table2? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A)
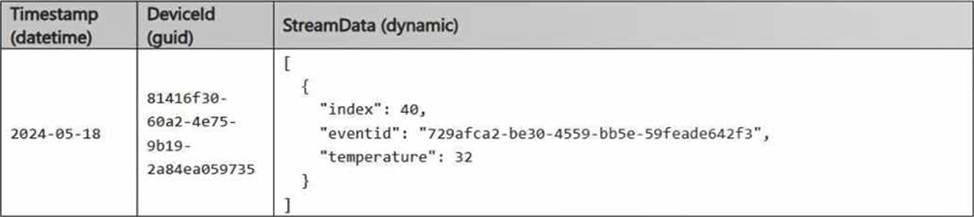
B)

C)

D)

- A . Option A
- B . Option B
- C . Option c
- D . Option D
A D
Explanation:
Changes to Table1 Structure:
– StreamData column: An additional temperature element was added.
– Timestamp column: Data type changed from datetime to date.
– DeviceId column: Data type changed from guid to string.
Impact of Changes:
– Only records that comply with Table2’s structure will load.
– Records that deviate from Table2’s column data types or structure will be rejected.
Record B:
– Timestamp: Matches Table2 (datetime format).
– eviceId: Matches Table2 (guid format).
– StreamData: Contains only the index and eventid, which matches Table2.
Accepted because it fully matches Table2’s structure and data types.
Record D:
– Timestamp: Matches Table2 (datetime format).
– DeviceId: Matches Table2 (guid format).
– StreamData: Matches Table2’s structure.
Accepted because it fully matches Table2’s structure and data types.
You have an Azure subscription that contains a blob storage account named sa1. Sa1 contains two files named Filelxsv and File2.csv.
You have a Fabric tenant that contains the items shown in the following table.
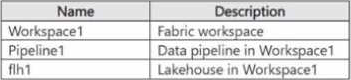
You need to configure Pipeline1 to perform the following actions:
• At 2 PM each day, process Filel.csv and load the file into flhl.
• At 5 PM each day. process File2.csv and load the file into flhl.
The solution must minimize development effort.
What should you use?
- A . a job definition
- B . a data pipeline schedule
- C . a data pipeline trigger
- D . an activator
HOTSPOT
You have a table in a Fabric lakehouse that contains the following data.
You have a notebook that contains the following code segment.
![]()
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.


You need to resolve the sales data issue. The solution must minimize the amount of data transferred.
What should you do?
- A . Spilt the dataflow into two dataflows.
- B . Configure scheduled refresh for the dataflow.
- C . Configure incremental refresh for the dataflow. Set Store rows from the past to 1 Month.
- D . Configure incremental refresh for the dataflow. Set Refresh rows from the past to 1 Year.
- E . Configure incremental refresh for the dataflow. Set Refresh rows from the past to 1 Month.
C
Explanation:
The sales data issue can be resolved by configuring incremental refresh for the dataflow. Incremental refresh allows for only the new or changed data to be processed, minimizing the amount of data transferred and improving performance.
The solution specifies that data older than one month never changes, so setting the refresh period to 1 Month is appropriate. This ensures that only the most recent month of data will be refreshed, reducing unnecessary data transfers.
You have a Fabric deployment pipeline that uses three workspaces named Dev, Test, and Prod.
You need to deploy an eventhouse as part of the deployment process.
What should you use to add the eventhouse to the deployment process?
- A . GitHub Actions
- B . a deployment pipeline
- C . an Azure DevOps pipeline