
Practice Free DP-300 Exam Online Questions
You have SQL Server on an Azure virtual machine that contains a database named DB1.
You have an application that queries DB1 to generate a sales report.
You need to see the parameter values from the last time the query was executed.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Enable Last_Query_Plan_Stats in the master database
- B . Enable Lightweight_Query_Profiling in DB1
- C . Enable Last_Query_Plan_Stats in DB1
- D . Enable Lightweight_Query_Profiling in the master database
- E . Enable PARAMETER_SNIFFING in DB1
HOTSPOT
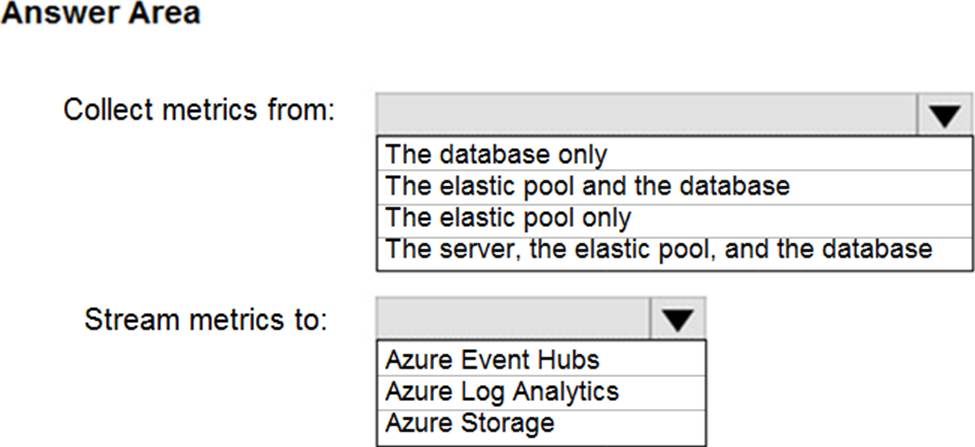
You need to implement the monitoring of SalesSQLDb1. The solution must meet the technical requirements.
How should you collect and stream metrics? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

You have an Azure virtual machine named VM1 that runs Windows Server 2022 and hosts a Microsoft SQL Server 2019 instance named SQL1. You need to configure SQL! to use mixed mode authentication.
Which procedure should you run?
- A . sp_addremoteIogin
- B . xp_instance_regwrite
- C . sp_cnarge_users_login
- D . xp_grant_login
HOTSPOT
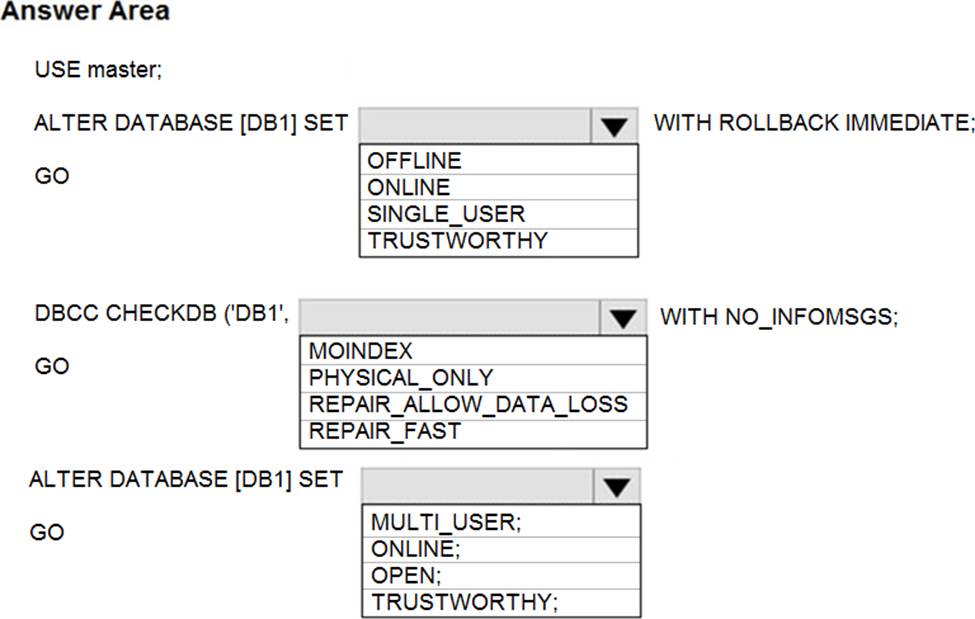
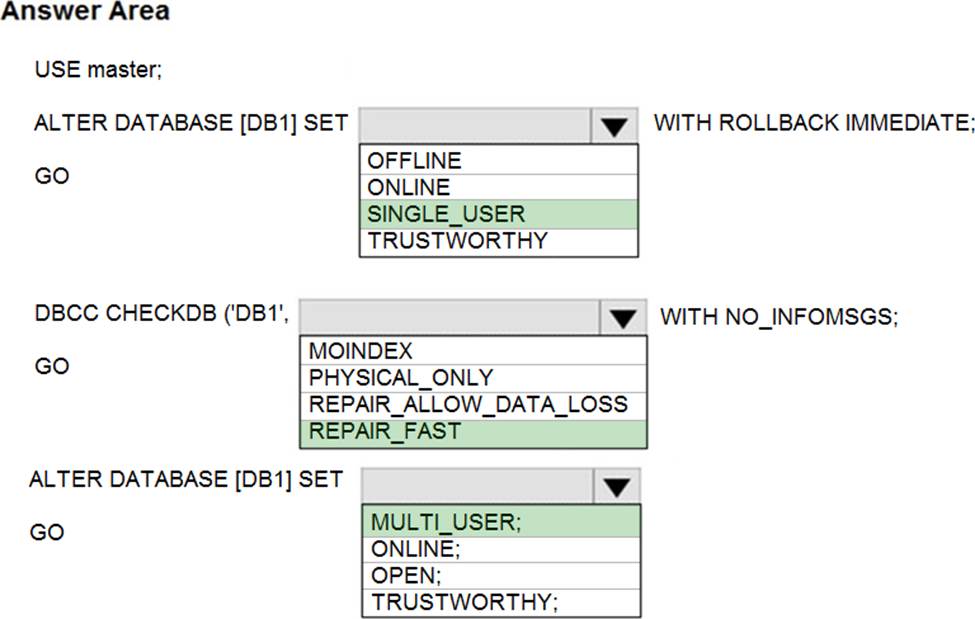
You have SQL Server on an Azure virtual machine that contains a database named DB1.
The database reports a CHECKSUM error.
You need to recover the database.
How should you complete the statements? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You have an Azure subscription that contains an Azure SQL database named DB1.
You need to host elastic jobs by using DB1. DB1 will also be configured as a job target. The solution must support the use of location-based Conditional Access policies.
What should the elastic jobs use to access DB1?
- A . a system-assigned managed identity
- B . Azure SQL sign-in credentials
- C . database-scoped credentials
- D . a user-assigned managed identity
HOTSPOT
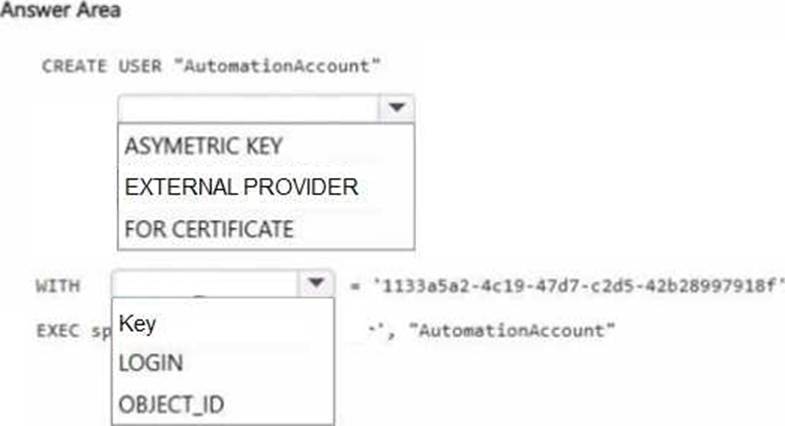
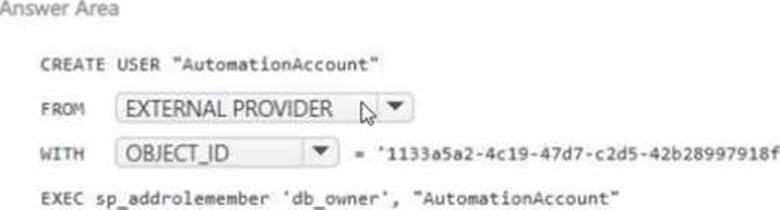
You have an Azure subscription that contains an Azure SQL database named DB1 and a managed identity. You need to create a user in DB1 that will be used by the managed identity to perform automated tasks.
How should you complete the query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You are designing a date dimension table in an Azure Synapse Analytics dedicated SQL pool. The date dimension table will be used by all the fact tables.
Which distribution type should you recommend to minimize data movement?
- A . HASH
- B . REPLICATE
- C . ROUND_ROBIN
HOTSPOT
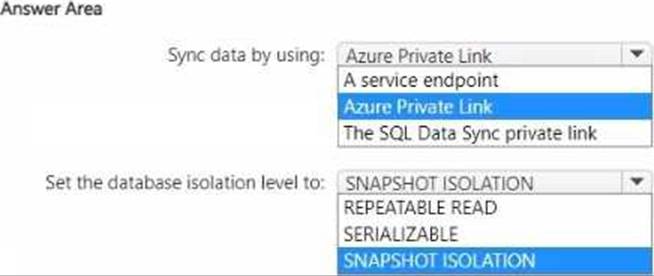
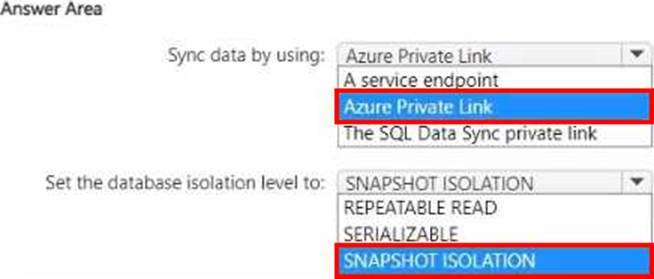
You have an Azure virtual machine named Server1 that has Microsoft SQL Server installed. Server1 contains a database named DB1.
You have a logical SQL server named ASVR1 that contains an Azure SQL database named ADB1.
You plan to use SQL Data Sync to migrate DB1 from Server! to ASVR1.
You need to prepare the environment for the migration. The solution must ensure that the connection from Server1 to ADB1 does NOT use a public endpoint.
What should you do? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
SIMULATION
Task 4
You need to enable change data capture (CDC) for db1.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Data Lake Storage account that contains a staging zone.
You need to design a daily process to ingest incremental data from the staging zone, transform the data by executing an R script, and then insert the transformed data into a data warehouse in Azure Synapse Analytics.
Solution: You use an Azure Data Factory schedule trigger to execute a pipeline that executes mapping data flow, and then inserts the data into the data warehouse.
Does this meet the goal?
- A . Yes
- B . No