
Practice Free Professional Cloud Developer Exam Online Questions
You are evaluating developer tools to help drive Google Kubernetes Engine adoption and integration with your development environment, which includes VS Code and IntelliJ.
What should you do?
- A . Use Cloud Code to develop applications.
- B . Use the Cloud Shell integrated Code Editor to edit code and configuration files.
- C . Use a Cloud Notebook instance to ingest and process data and deploy models.
- D . Use Cloud Shell to manage your infrastructure and applications from the command line.
A
Explanation:
Reference: https://cloud.google.com/code
You are evaluating developer tools to help drive Google Kubernetes Engine adoption and integration with your development environment, which includes VS Code and IntelliJ.
What should you do?
- A . Use Cloud Code to develop applications.
- B . Use the Cloud Shell integrated Code Editor to edit code and configuration files.
- C . Use a Cloud Notebook instance to ingest and process data and deploy models.
- D . Use Cloud Shell to manage your infrastructure and applications from the command line.
A
Explanation:
Reference: https://cloud.google.com/code
Your teammate has asked you to review the code below, which is adding a credit to an account balance in Cloud Datastore.
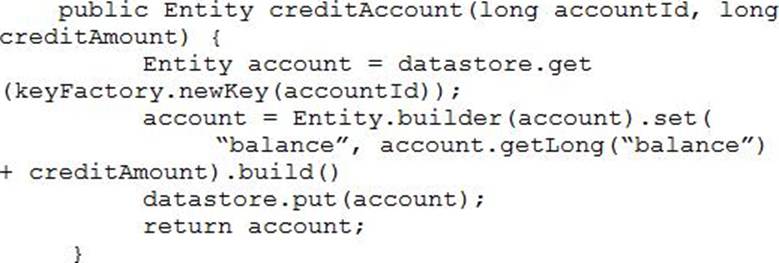
Which improvement should you suggest your teammate make?
- A . Get the entity with an ancestor query.
- B . Get and put the entity in a transaction.
- C . Use a strongly consistent transactional database.
- D . Don’t return the account entity from the function.
You are a SaaS provider deploying dedicated blogging software to customers in your Google Kubernetes Engine (GKE) cluster. You want to configure a secure multi-tenant platform to ensure that each customer has access to only their own blog and can’t affect the workloads of other customers.
What should you do?
- A . Enable Application-layer Secrets on the GKE cluster to protect the cluster.
- B . Deploy a namespace per tenant and use Network Policies in each blog deployment.
- C . Use GKE Audit Logging to identify malicious containers and delete them on discovery.
- D . Build a custom image of the blogging software and use Binary Authorization to prevent untrusted image deployments.
B
Explanation:
Reference: https://cloud.google.com/kubernetes-engine/docs/concepts/multitenancy-overview
Your company has deployed a new API to App Engine Standard environment. During testing, the API is not behaving as expected. You want to monitor the application over time to diagnose the problem within the application code without redeploying the application.
Which tool should you use?
- A . Stackdriver Trace
- B . Stackdriver Monitoring
- C . Stackdriver Debug Snapshots
- D . Stackdriver Debug Logpoints
B
Explanation:
Reference: https://rominirani.com/gcp-stackdriver-tutorial-debug-snapshots-traces-logging-and-logpoints-1ba49e4780e6
HipLocal wants to improve the resilience of their MySQL deployment, while also meeting their business and technical requirements.
Which configuration should they choose?
- A . Use the current single instance MySQL on Compute Engine and several read-only MySQL servers on Compute Engine.
- B . Use the current single instance MySQL on Compute Engine, and replicate the data to Cloud SQL in an external master configuration.
- C . Replace the current single instance MySQL instance with Cloud SQL, and configure high availability.
- D . Replace the current single instance MySQL instance with Cloud SQL, and Google provides redundancy without further configuration.
You have an application in production. It is deployed on Compute Engine virtual machine instances controlled by a managed instance group. Traffic is routed to the instances via a HTTP(s) load balancer. Your users are unable to access your application. You want to implement a monitoring technique to alert you when the application is unavailable.
Which technique should you choose?
- A . Smoke tests
- B . Stackdriver uptime checks
- C . Cloud Load Balancing – heath checks
- D . Managed instance group – heath checks
B
Explanation:
Reference: https://medium.com/google-cloud/stackdriver-monitoring-automation-part-3-uptime-checks-476b8507f59c
You are designing a schema for a Cloud Spanner customer database. You want to store a phone number array field in a customer table. You also want to allow users to search customers by phone number.
How should you design this schema?
- A . Create a table named Customers. Add an Array field in a table that will hold phone numbers for the customer.
- B . Create a table named Customers. Create a table named Phones. Add a CustomerId field in the Phones table to find the CustomerId from a phone number.
- C . Create a table named Customers. Add an Array field in a table that will hold phone numbers for the customer. Create a secondary index on the Array field.
- D . Create a table named Customers as a parent table. Create a table named Phones, and interleave this table into the Customer table. Create an index on the phone number field in the Phones table.
Your company wants to expand their users outside the United States for their popular application. The company wants to ensure 99.999% availability of the database for their application and also wants to minimize the read latency for their users across the globe.
Which two actions should they take? (Choose two.)
- A . Create a multi-regional Cloud Spanner instance with "nam-asia-eur1" configuration.
- B . Create a multi-regional Cloud Spanner instance with "nam3" configuration.
- C . Create a cluster with at least 3 Spanner nodes.
- D . Create a cluster with at least 1 Spanner node.
- E . Create a minimum of two Cloud Spanner instances in separate regions with at least one node.
- F . Create a Cloud Dataflow pipeline to replicate data across different databases.
Your team is developing an ecommerce platform for your company. Users will log in to the website and add items to their shopping cart. Users will be automatically logged out after 30 minutes of inactivity. When users log back in, their shopping cart should be saved.
How should you store users’ session and shopping cart information while following Google-recommended best practices?
- A . Store the session information in Pub/Sub, and store the shopping cart information in Cloud SQL.
- B . Store the shopping cart information in a file on Cloud Storage where the filename is the SESSION ID.
- C . Store the session and shopping cart information in a MySQL database running on multiple Compute Engine instances.
- D . Store the session information in Memorystore for Redis or Memorystore for Memcached, and store the shopping cart information in Firestore.