
Practice Free NCP-MCI-6.10 Exam Online Questions
An administrator is configuring Protection Policies to replicate VMs to a Nutanix Cloud Cluster (NC2) over the internet.
To comply with security policies, how should data be protected during transmission?
- A . Configure Data on a self-encrypting drive.
- B . Configure VMs to use UEFI Secure Boot.
- C . Enable Data-at-Rest Encryption.
- D . Enable Data-in-Transit Encryption.
D
Explanation:
Data-in-Transit Encryption ensures that replication traffic is encrypted while being sent over the internet.
Option D (Enable Data-in-Transit Encryption) is correct:
This encrypts replicated data between clusters, ensuring security against man-in-the-middle attacks.
Option A (Self-encrypting drive) is incorrect:
This protects data at rest, not during transmission.
Option B (UEFI Secure Boot) is incorrect:
Secure Boot prevents unauthorized OS modifications, but does not encrypt network traffic.
Option C (Data-at-Rest Encryption) is incorrect:
This encrypts stored data but does not secure replication traffic.
Reference: Nutanix Security Guide → Configuring Data-in-Transit Encryption
Nutanix KB → Protecting Replication Traffic Over Public Networks
What happens if an agent VM is powered off and then manually started on another host?
- A . Agent VM become unresponsive.
- B . Agent VM cannot be migrated back to the original host.
- C . Agent VM migrates back to the original host once it’s powered on.
- D . Agent VM migrates to another host automatically
An administrator needs to compare the performance of two VMs that are running on separate Nutanix clusters.
When creating an Analysis chart in Prism Central Intelligent Operations, the administrator discovers that it is not possible to add VM metrics for IOPS and CPU utilization to the same chart.
How should the administrator resolve this issue?
- A . Create an Entity chart instead of a Metric chart.
- B . Ensure that both VMs have the same number of vCPUs provisioned.
- C . Migrate one of the VMs so that both VMs are running on the same cluster.
- D . Create separate charts for metrics with different units of measurement
In a scale-out Prism Central deployment, what additional functionality does configuring an FQDN instead of a Virtual IP provide?
- A . Load balancing
- B . Resiliency
- C . Segmentation
- D . SSL Certificate
A
Explanation:
In a scale-out Prism Central deployment, using an FQDN (Fully Qualified Domain Name) enables load
balancing across multiple Prism Central instances.
Option A (Load balancing) is correct:
When an FQDN is used, Nutanix automatically distributes traffic between multiple Prism Central nodes, improving performance.
Option B (Resiliency) is incorrect:
Resiliency is achieved through cluster redundancy, not by using an FQDN.
Option C (Segmentation) is incorrect:
Segmentation relates to network isolation rather than FQDN-based load balancing.
Option D (SSL Certificate) is incorrect:
SSL certificates can be applied to both FQDN and Virtual IP configurations.
Reference: Nutanix Prism Central Guide → Configuring Scale-Out Deployment Nutanix KB → How FQDN Enhances Load Balancing in Scale-Out Prism Central
Refer to Exhibit:
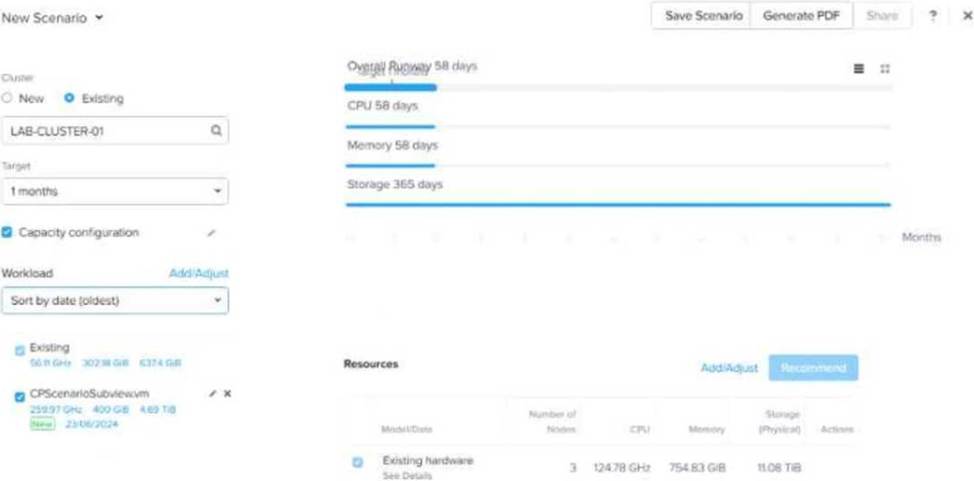
After adding new workloads, why is Overall Runway below 365 days and the scenario still shows the cluster is in good shape?
- A . Because Storage Runway is still good.
- B . Because new workloads are sustainable.
- C . Because there are recommended resources.
- D . Because the Target is 1 month.
B
Explanation:
In Nutanix Capacity Planning, Overall Runway represents how long the cluster can support current and new workloads before resources are exhausted.
Even if the runway is below 365 days, the system considers the cluster to be in good shape if new workloads are sustainable (Option B).
Option A is incorrect: Storage runway alone is not the only factor; CPU and memory are equally important.
Option C is incorrect: The presence of recommended resources does not mean the cluster is in good shape.
Option D is incorrect: The target of 1 month affects projections but does not explain why the cluster is in good shape.
Reference: Nutanix Prism Central → Capacity Runway and Planning
Nutanix Bible → Workload Placement and Cluster Sizing
Nutanix Support KB → Capacity Planning Best Practices
What happens when a VM is associated with multiple VM-Host affinity policies?
- A . The newest policy takes precedence.
- B . The VM is automatically removed from all policies.
- C . All policies are applied simultaneously.
- D . The oldest policy is applied
An administrator is working with a local network engineer to design the network architecture for a Disaster Recovery (DR) failover. Because DNS is well designed and implemented, DR will utilize a different subnet from production. To make the planning and execution easy to implement, the network engineer would like to utilize the same last octet in DR. What is the best way to achieve this?
- A . Use a custom script to update the IP address after instantiation in DR.
- B . Set up IPAM so the address is dynamically assigned during DR.
- C . Manually log into VMs after the DR event and update the last octet.
- D . Utilize Recovery Plan Offset-based IP mapping.
D
Explanation:
Offset-based IP mapping in Nutanix Recovery Plans allows automatic subnet changes during DR failover.
Option D (Utilize Recovery Plan Offset-based IP mapping) is correct:
This method automatically adjusts the IP range while keeping the same last octet.
It eliminates the need for manual intervention after failover.
Option A (Custom script) is incorrect:
Scripting is an option, but Recovery Plan IP mapping is simpler and native to Nutanix.
Option B (Use IPAM) is incorrect:
IP Address Management (IPAM) is useful, but offset-based mapping provides more control.
Option C (Manually update IPs) is incorrect:
This would be time-consuming and error-prone.
Reference: Nutanix Disaster Recovery Guide → Using Offset-Based IP Mapping Nutanix KB → Best Practices for Managing IP Addresses in DR
An administrator migrated a physical MySQL database from a legacy 3-tier environment to a Nutanix cluster.
After migration, the administrator finds that at peak load, the number of IOPS is lower than expected, and latency is higher.
Which two steps should the administrator take to improve performance? (Choose two.)
- A . Ensure that the SQL data vDisks are thick provisioned.
- B . Create additional vDisks for SQL data.
- C . Use LVM to stripe the SQL data across multiple vDisks.
- D . Ensure that the SQL data vDisks are thin provisioned.
B, C
Explanation:
For high-performance databases like MySQL, optimizing storage access is critical.
Option B (Create additional vDisks for SQL data) is correct:
Multiple vDisks allow better parallelism in Nutanix DSF (Distributed Storage Fabric), improving IOPS.
Option C (Use LVM to stripe SQL data across multiple vDisks) is correct:
Striping across multiple disks distributes the load, reducing latency.
Option A (Thick provisioned vDisks) is incorrect:
Nutanix always provisions vDisks thinly, and thick provisioning does not improve IOPS.
Option D (Thin provisioned vDisks) is incorrect:
All Nutanix vDisks are thin-provisioned by default.
Reference: Nutanix Bible → Optimizing SQL Performance on Nutanix Nutanix KB → Best Practices for Running MySQL on Nutanix
Which two URLs must be accessible from a Connected Site’s Controller VMs to allow Life Cycle Manager (LCM) to download software updates?
- A . download.nutanix.com
- B . mynutanix.com
- C . release-api.nutanix.com
- D . portal.nutanix.com
A, C
Explanation:
LCM (Life Cycle Manager) fetches software updates from Nutanix’s repositories, requiring access to specific URLs.
Option A (download.nutanix.com) is correct:
This domain hosts all software update files for AOS, AHV, and other Nutanix components.
Option C (release-api.nutanix.com) is correct:
This domain is used for LCM to fetch update metadata and check for new versions.
Option B (mynutanix.com) is incorrect:
This domain is used for account management, not LCM updates.
Option D (portal.nutanix.com) is incorrect:
The Nutanix support portal is not used for automated LCM updates.
Reference: Nutanix LCM Guide → Firewall Rules for LCM Connectivity Nutanix KB → Troubleshooting LCM Update Failures
The customer expects to maintain a cluster runway of 9 months. The customer doesn’t have a budget for 6 months but they want to add new workloads to the existing cluster.
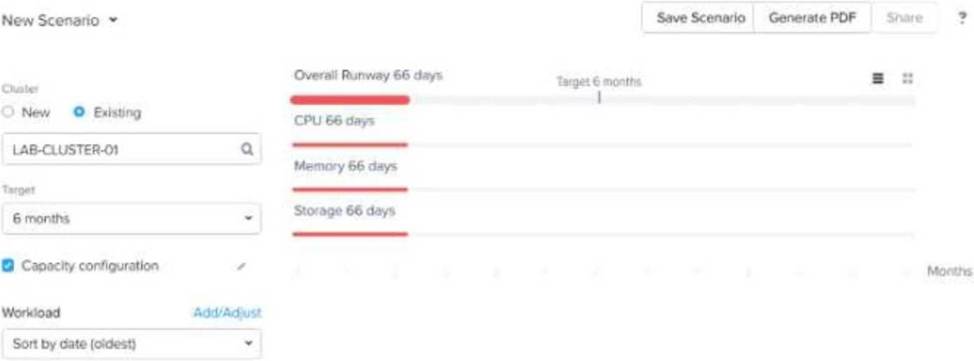
Based on the exhibit, what is required to meet the customer’s budgetary timeframe?
- A . Add resources to the cluster.
- B . Postpone the start of new workloads.
- C . Delete workloads running on the cluster.
- D . Change the target to 9 months.
B
Explanation:
The exhibit shows that the overall runway is only 66 days, meaning that the current cluster does not have enough capacity to sustain workloads for 6 months, let alone 9 months.
The best solution is to add resources to the cluster (Option A), such as CPU, memory, or storage, to extend the runway.
Postponing new workloads (Option B) may help in the short term but does not align with the business need to continue adding workloads.
Deleting workloads (Option C) is not a viable option because the customer wants to add more, not remove them.
Changing the target to 9 months (Option D) does not change the actual resource constraints; it only
alters the target timeframe.
Reference: Nutanix Prism Central → Capacity Planning and Runway Analysis Nutanix Bible → Cluster Resource Management and Scaling
Nutanix Support KB → How to Extend Cluster Runway with Resource Scaling