
Practice Free NCP-AII Exam Online Questions
You’ve deployed a GPU-accelerated application in Kubernetes using the NVIDIA device plugin. However, your pods are failing to start with an error indicating that they cannot find the NVIDIA libraries.
Which of the following could be potential causes of this issue? (Multiple Answers)
- A . The NVIDIA drivers are not installed on the host node.
- B . The ‘nvidia-container-runtime’ is not configured as the default runtime for Docker/containerd.
- C . The NVIDIA device plugin is not properly configured in the Kubernetes cluster.
- D . The application container image does not include the necessary NVIDIA libraries.
- E . The GPU’s compute capability is not sufficient for the workload.
A,B,C,D
Explanation:
If pods cannot find NVIDIA libraries, it could be because the drivers are missing on the host, the container runtime is not configured to use the NVIDIA runtime, the NVIDIA device plugin is misconfigured preventing GPU discovery and allocation, or the application container image does not include the NVIDIA libraries. E is likely incorrect, if the GPU’s compute capability is insufficient then the app would likely start, but throw an error when trying to use the GPU.
You are replacing a faulty NVIDIA Tesla V 100 GPU in a server. After physically installing the new GPU, the system fails to recognize it. You’ve verified the power connections and seating of the card.
Which of the following steps should you take next to troubleshoot the issue?
- A . Immediately RMA the new GPU as it is likely defective.
- B . Update the system BIOS and BMC firmware to the latest versions.
- C . Reinstall the operating system to ensure proper driver installation.
- D . Check if the new GPU requires a different driver version than the currently installed one and update if needed.
- E . Disable and re-enable the GPU slot in the system BIOS.
B,D
Explanation:
After verifying the physical installation, the next steps are to ensure the system’s firmware is up-to-date and that the correct drivers are installed. Older BIOS/BMC firmware may not properly recognize newer GPUs, and incorrect drivers will prevent the GPU from functioning correctly. RMAing the new GPU or reinstalling the OS prematurely are inefficient troubleshooting steps. The system BIOS may have an option to disable and enable the GPU slot, but that would be rare.
You are tasked with validating a newly installed NVIDIAAIOO Tensor Core GPU within a server. You need to confirm the GPU is correctly recognized and functioning at its expected performance level. Describe the process, including commands and tools, to verify the following aspects: 1) GPU presence and basic information, 2) PCle bandwidth and link speed, and 3) Sustained computational performance under load.
- A . 1) Use ‘Ispci I grep NVIDIA’ for presence, ‘nvidia-smi’ for basic info.
2) Use ‘nvidia-smi -q -d pcie’ for bandwidth/speed.
3) Run a TensorFlow ResNet50 benchmark. - B . 1) Use ‘nvidia-smi’ for presence and basic info.
2) PCle speed is irrelevant.
3) Run the ‘nvprof profiler during a CUDA application. - C . 1) Check BIOS settings for GPU detection.
2) Use ‘Ispci -vv’ to check PCle speed.
3) Run a PyTorch ImageNet training script. - D . 1) Use ‘nvidia-smi’ for presence and basic info.
2) Use ‘nvidia-smi -q -d pcie’ for bandwidth/speed.
3) Run a CUDA-based matrix multiplication benchmark (e.g., using cuBLAS) with increasing matrix sizes and monitor performance. - E . 1) Use ‘nvidia-smi’ for presence and basic info.
2) Use ‘nvlink-monitor’ for bandwidth/speed.
3) Run a CPU-bound benchmark to avoid GPU bottlenecks.
D
Explanation:
‘nvidia-smi’ is the primary tool for NVIDIA GPU information. ‘nvidia-smi -q -d pcie’ provides PCle details. A CUDA-based benchmark isolates GPU performance. Other options have elements of truth but aren’t complete or optimally targeted (e.g., ResNet50 relies on other frameworks). Using a CPU-bound benchmark wouldn’t test the GPU’s capabilities.
After replacing a faulty NVIDIA GPU, the system boots, and ‘nvidia-smi’ detects the new card. However, when you run a CUDA program, it fails with the error "‘no CUDA-capable device is detected’". You’ve confirmed the correct drivers are installed and the GPU is properly seated.
What’s the most probable cause of this issue?
- A . The new GPU is incompatible with the existing system BIOS.
- B . The CUDA toolkit is not properly configured to use the new GPU.
- C . The ‘LD LIBRARY PATH* environment variable is not set correctly.
- D . The user running the CUDA program does not have the necessary permissions to access the GPU.
- E . The GPIJ is not properly initialized by the system due to a missing or incorrect ACPI configuration.
E
Explanation:
The error "no CUDA-capable device is detected", even when ‘nvidia-smi’ sees the GPIJ, points to a lower-level system issue that prevents CUDA from accessing the card. In such scenarios, ACPI (Advanced Configuration and Power Interface) misconfiguration is frequently the culprit. ACPI handles device initialization and power management. If ACPI doesn’t properly configure the new GPU, CUDA programs won’t be able to access it. Checking and correcting ACPI configuration would be the first line of action, which includes ensuring proper settings in the system BIOS/IJEFI related to PCI devices, especially those related to GPU/accelerators. LD LIBRARY PATH would affect runtime linking of CUDA libraries, but not the base device detection. User permissions are less likely to be the cause since ‘nvidia-smr works.
You are tasked with implementing a monitoring solution for power consumption and thermal performance in an NVIDIA-powered Ai cluster. You want to collect data from the Baseboard Management Controllers (BMCs) of the servers using Redfish.
Which of the following Python code snippets demonstrates the correct approach for authenticating with the BMC and retrieving power and temperature readings?
A )

B )
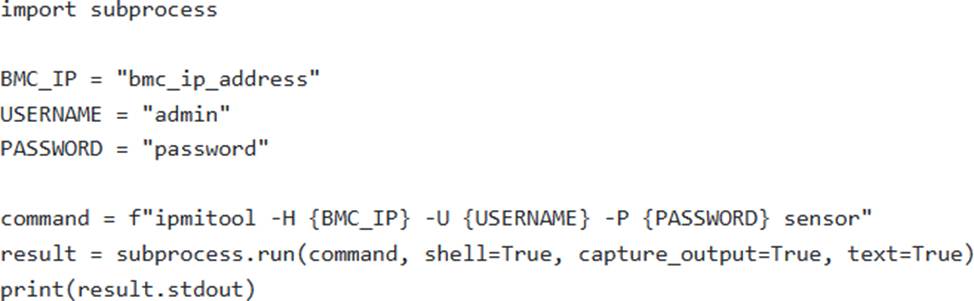
C )
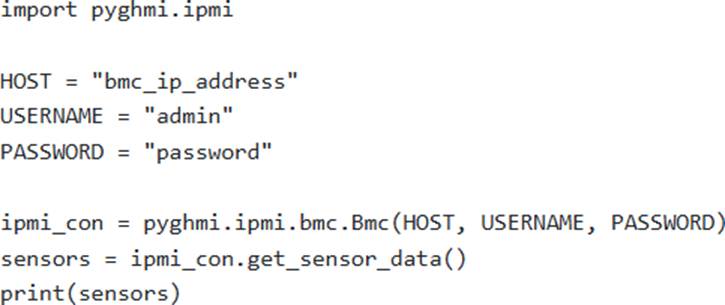
D ) None of the above. Redfish requires specialized hardware and cannot be accessed directly via Python.
E )

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A
Explanation:
Option A provides a valid example using the ‘redfish’ library to connect to a BMC, authenticate, and retrieve power and temperature readings. It uses the correct Redfish API structure to access the relevant data.
Option B uses ‘ipmitoor’, which is another valid approach but less modern than Redfish.
Option C uses ‘pyghmi.ipmi’, which is an older IPMI library.
Option D is incorrect; Redfish can be accessed via Python.
Option E is nonsense; Redfish is not an email protocol.
You are tasked with implementing a monitoring solution for power consumption and thermal performance in an NVIDIA-powered Ai cluster. You want to collect data from the Baseboard Management Controllers (BMCs) of the servers using Redfish.
Which of the following Python code snippets demonstrates the correct approach for authenticating with the BMC and retrieving power and temperature readings?
A )
B )
C )
D ) None of the above. Redfish requires specialized hardware and cannot be accessed directly via Python.
E )
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A
Explanation:
Option A provides a valid example using the ‘redfish’ library to connect to a BMC, authenticate, and retrieve power and temperature readings. It uses the correct Redfish API structure to access the relevant data.
Option B uses ‘ipmitoor’, which is another valid approach but less modern than Redfish.
Option C uses ‘pyghmi.ipmi’, which is an older IPMI library.
Option D is incorrect; Redfish can be accessed via Python.
Option E is nonsense; Redfish is not an email protocol.
You’re experiencing unexpected memory errors during the execution of a large-scale deep learning training job.
Suspecting faulty memory modules, which diagnostic tool is best suited to perform a comprehensive memory test on the server’s RAM?
- A . nvidia-smi
- B . nvprof
- C . memtest86+
- D . DCGM
- E . Ishw
C
Explanation:
‘memtest86+’ is specifically designed for performing thorough memory tests on system RAM, identifying potential errors and hardware faults. ‘nvidia-smi’ is for GPU monitoring, ‘nvprof is a profiler, DCGM can test GPU memory, but not system RAM specifically. ‘Ishw’ lists hardware information, but doesn’t perform diagnostic tests.
You are tasked with automating the BlueField OS deployment process across a large number of SmartNICs.
Which of the following methods is MOST suitable for this task?
- A . Manually flashing each SmartNIC using the ‘bfboot utility on a workstation.
- B . Using a network boot (PXE) server to deploy the BlueField OS image over the network. This allows centralized management and scalability.
- C . Creating a custom ISO image with the BlueField OS and booting each SmartNIC from a USB drive.
- D . Utilizing the ‘dd’ command to directly copy the image to each SmartNIC’s flash memory.
- E . Utilizing a custom-built python script to flash each individual card, controlled from a central server. This method supports parallel flashing.
B
Explanation:
PXE boot allows for automated and scalable OS deployment over the network, making it the most suitable option for managing a large number of SmartNlCs. Manually flashing or using USB drives is not practical at scale, and using ‘dd’ directly can be risky and error-prone without proper checks.
A BlueField-3 DPUis configured to run both control plane and data plane functions. After a recent software update, you notice that the data plane performance has significantly degraded, but the control plane remains responsive.
What is the MOST likely cause, assuming the update didn’t introduce any code bugs, and what is the BEST approach to diagnose this issue?
- A . Resource contention; Use ‘perf or ‘bpftrace’ to profile the data plane processes and identify resource bottlenecks (CPU, memory, cache).
- B . Driver incompatibility; Downgrade the Mellanox OFED drivers to the previous version.
- C . Firmware corruption; Re-flash the BlueField DPIJ with the latest firmware image.
- D . Network misconfiguration; Verify the MTU and QOS settings on the network interfaces.
- E . Power throttling; Check the DPU’s power consumption and thermal status via the BMC.
A
Explanation:
Resource contention is the MOST likely cause, assuming no code bugs. The update may have increased the resource demands of either the control or data plane, leading to contention. Profiling the data plane processes with ‘perf or ‘bpftrace’ helps pinpoint the bottlenecks. Downgrading drivers or reflashing firmware are more drastic steps to take after confirming resource contention isn’t the issue.
A data center is designed for A1 training with a high degree of east-west traffic. Considering cost and performance, which network topology is generally the most suitable?
- A . Spine-Leaf
- B . Three-Tier
- C . Ring
- D . Bus
- E . Mesh
A
Explanation:
Spine-Leaf architecture is designed to handle high-bandwidth, low-latency traffic patterns characteristic of AI training. It provides a non-blocking fabric with equal cost paths between any two servers, making it ideal for east-west communication. Three-Tier is more suited for traditional applications with north-south traffic. Ring and Bus are less scalable and perform poorly under heavy load. Mesh is complex and expensive for large-scale deployments.