
Practice Free MuleSoft Platform Architect I Exam Online Questions
An established communications company is beginning its API-led connectivity journey, The company has been using a successful Enterprise Data Model for many years. The company has identified a self-service account management app as the first effort for API-led, and it has identified the following APIs.
Experience layer: Mobile Account Management EAPI, Browser Account Management EAPI
Process layer: Customer Lookup PAPI, Service Lookup PAPI, Account Lookup PAPI
System layer: Customer SAPI, Account SAPI, Product SAPI, Service SAPI
According to MuleSoft’s API-led connectivity approach, which API would not be served by the Enterprise Data Model?
- A . Customer SAPI
- B . Customer Lookup PAPI
- C . Mobile Account Management EAPI
- D . Service SAPI
C
Explanation:
In the API-led connectivity approach, APIs are categorized into Experience, Process, and System layers:
Enterprise Data Model Scope:
The Enterprise Data Model (EDM) generally supports System APIs and some Process APIs by defining standard data structures used across the organization. Experience APIs, however, are tailored to specific applications or interfaces and are less likely to be served directly by the EDM, as they may require customized data representations to meet the unique needs of each user interface.
Why Option C is Correct:
The Mobile Account Management EAPI serves mobile-specific needs and often requires data formatted differently from the standardized data models. Thus, it would be outside the direct scope of the EDM and might employ custom mappings to fit mobile application requirements. of Incorrect Options:
Option A (Customer SAPI), Option B (Customer Lookup PAPI), and Option D (Service SAPI) would typically align with the EDM as they are closer to the core data and services the EDM supports. Reference
For additional guidance, review MuleSoft’s best practices on API-led connectivity and data modeling.
Which statement is true about identity management and client management on Anypoint Platform?
- A . If an external identity provider is configured, the SAML 2.0 bearer tokens issued by the identity provider cannot be used for invocations of the Anypoint Platform web APIs
- B . If an external client provider is configured, it must be configured at the Anypoint Platform organization level and cannot be assigned to individual business groups and environments
- C . Anypoint Platform supports configuring one external identity provider
- D . Both client management and identity management require an identity provider
C
Explanation:
Anypoint Platform allows organizations to integrate one external identity provider (IdP) for identity and access management (IAM), supporting SSO and centralized user authentication.
Identity Provider Limit:
Anypoint Platform supports configuring a single IdP for the organization, which can be used to authenticate all users across business groups and environments within that Anypoint organization. of Correct Answer (C):
Configuring one IdP ensures centralized and secure identity management, aligned with MuleSoft’s architecture.
of Incorrect Options:
Option A is incorrect because SAML 2.0 bearer tokens from external IdPs can indeed be used for invoking Anypoint Platform APIs.
Option B is incorrect as client providers can be assigned to specific business groups and environments.
Option D is incorrect since only identity management strictly requires an IdP; client management
does not.
Reference
For further details on identity management options, consult MuleSoft documentation on Anypoint Platform’s IAM capabilities.
A retail company is using an Order API to accept new orders. The Order API uses a JMS queue to submit orders to a backend order management service. The normal load for orders is being handled using two (2) CloudHub workers, each configured with 0.2 vCore. The CPU load of each CloudHub worker normally runs well below 70%. However, several times during the year the Order API gets four times (4x) the average number of orders. This causes the CloudHub worker CPU load to exceed 90% and the order submission time to exceed 30 seconds. The cause, however, is NOT the backend order management service, which still responds fast enough to meet the response SLA for the Order API.
What is the MOST resource-efficient way to configure the Mule application’s CloudHub deployment to help the company cope with this performance challenge?
- A . Permanently increase the size of each of the two (2) CloudHub workers by at least four times (4x) to one (1) vCore
- B . Use a vertical CloudHub autoscaling policy that triggers on CPU utilization greater than 70%
- C . Permanently increase the number of CloudHub workers by four times (4x) to eight (8) CloudHub workers
- D . Use a horizontal CloudHub autoscaling policy that triggers on CPU utilization greater than 70%
D
Explanation:
Correct Answer Use a horizontal CloudHub autoscaling policy that triggers on CPU utilization
greater than 70%
The scenario in the question is very clearly stating that the usual traffic in the year is pretty well handled by the existing worker configuration with CPU running well below 70%. The problem occurs only "sometimes" occasionally when there is spike in the number of orders coming in.
So, based on above, We neither need to permanently increase the size of each worker nor need to permanently increase the number of workers. This is unnecessary as other than those "occasional" times the resources are idle and wasted.
We have two options left now. Either to use horizontal Cloudhub autoscaling policy to automatically increase the number of workers or to use vertical Cloudhub autoscaling policy to automatically increase the vCore size of each worker.
Here, we need to take two things into consideration:
When must an API implementation be deployed to an Anypoint VPC?
- A . When the API Implementation must invoke publicly exposed services that are deployed outside of CloudHub in a customer- managed AWS instance
- B . When the API implementation must be accessible within a subnet of a restricted customer-hosted network that does not allow public access
- C . When the API implementation must be deployed to a production AWS VPC using the Mule Maven plugin
- D . When the API Implementation must write to a persistent Object Store
An organization is deploying their new implementation of the OrderStatus System API to multiple workers in CloudHub. This API fronts the organization’s on-premises Order Management System, which is accessed by the API implementation over an IPsec tunnel.
What type of error typically does NOT result in a service outage of the OrderStatus System API?
- A . A CloudHub worker fails with an out-of-memory exception
- B . API Manager has an extended outage during the initial deployment of the API implementation
- C . The AWS region goes offline with a major network failure to the relevant AWS data centers
- D . The Order Management System is Inaccessible due to a network outage in the organization’s on-premises data center
A
Explanation:
Correct Answer A CloudHub worker fails with an out-of-memory exception.
>> An AWS Region itself going down will definitely result in an outage as it does not matter how many workers are assigned to the Mule App as all of those in that region will go down. This is a complete downtime and outage.
>> Extended outage of API manager during initial deployment of API implementation will of course cause issues in proper application startup itself as the API Autodiscovery might fail or API policy templates and polices may not be downloaded to embed at the time of applicaiton startup etc…
there are many reasons that could cause issues.
>> A network outage onpremises would of course cause the Order Management System not accessible and it does not matter how many workers are assigned to the app they all will fail and cause outage for sure.
The only option that does NOT result in a service outage is if a cloudhub worker fails with an out-of-memory exception. Even if a worker fails and goes down, there are still other workers to handle the requests and keep the API UP and Running. So, this is the right answer.
An organization is deploying their new implementation of the OrderStatus System API to multiple workers in CloudHub. This API fronts the organization’s on-premises Order Management System, which is accessed by the API implementation over an IPsec tunnel.
What type of error typically does NOT result in a service outage of the OrderStatus System API?
- A . A CloudHub worker fails with an out-of-memory exception
- B . API Manager has an extended outage during the initial deployment of the API implementation
- C . The AWS region goes offline with a major network failure to the relevant AWS data centers
- D . The Order Management System is Inaccessible due to a network outage in the organization’s on-premises data center
A
Explanation:
Correct Answer A CloudHub worker fails with an out-of-memory exception.
>> An AWS Region itself going down will definitely result in an outage as it does not matter how many workers are assigned to the Mule App as all of those in that region will go down. This is a complete downtime and outage.
>> Extended outage of API manager during initial deployment of API implementation will of course cause issues in proper application startup itself as the API Autodiscovery might fail or API policy templates and polices may not be downloaded to embed at the time of applicaiton startup etc…
there are many reasons that could cause issues.
>> A network outage onpremises would of course cause the Order Management System not accessible and it does not matter how many workers are assigned to the app they all will fail and cause outage for sure.
The only option that does NOT result in a service outage is if a cloudhub worker fails with an out-of-memory exception. Even if a worker fails and goes down, there are still other workers to handle the requests and keep the API UP and Running. So, this is the right answer.
A customer has an ELA contract with MuleSoft. An API deployed to CloudHub is consistently experiencing performance issues. Based on the root cause analysis, it is determined that autoscaling needs to be applied.
How can this be achieved?
- A . Configure a policy so that when the number of HTTP requests reaches a certain threshold the number of workers/replicas increases (horizontal scaling)
- B . Configure two separate policies: When CPU and memory reach certain threshold, increase the worker/replica type (vertical sealing) and the number of workers/replicas (horizontal sealing)
- C . Configure a policy based on CPU usage so that CloudHub auto-adjusts the number of workers/replicas (horizontal scaling)
- D . Configure a policy so that when the response time reaches a certain threshold the worker/replica type increases (vertical scaling)
C
Explanation:
In MuleSoft CloudHub, autoscaling is essential to managing application load efficiently. CloudHub supports horizontal scaling based on CPU usage, which is well-suited to applications experiencing variable demand and needing responsive resource allocation.
Autoscaling on CloudHub:
Horizontal scaling increases the number of workers in response to CPU usage thresholds, allowing
the application to handle higher loads dynamically. This approach improves performance without
downtime or manual intervention.
Why Option C is Correct:
Setting up autoscaling based on CPU usage aligns with MuleSoft’s best practices for scalable and
responsive applications on CloudHub, particularly in an environment with fluctuating load patterns.
Option C correctly leverages CloudHub’s autoscaling features based on resource metrics, which are
part of CloudHub’s managed scaling solutions.
of Incorrect Options:
Option A (based on HTTP request thresholds) and Option B (separate policies for CPU and memory) do not represent CloudHub’s recommended scaling practices.
Option D suggests vertical scaling based on response time, which is not how CloudHub handles
autoscaling.
Reference
For more on CloudHub’s autoscaling configuration, refer to MuleSoft documentation on CloudHub autoscaling policies.
In an organization, the InfoSec team is investigating Anypoint Platform related data traffic.
From where does most of the data available to Anypoint Platform for monitoring and alerting originate?
- A . From the Mule runtime or the API implementation, depending on the deployment model
- B . From various components of Anypoint Platform, such as the Shared Load Balancer, VPC, and Mule runtimes
- C . From the Mule runtime or the API Manager, depending on the type of data
- D . From the Mule runtime irrespective of the deployment model
D
Explanation:
Correct Answer From the Mule runtime irrespective of the deployment model >> Monitoring and Alerting metrics are always originated from Mule Runtimes irrespective of the deployment model.
>> It may seems that some metrics (Runtime Manager) are originated from Mule Runtime and some are (API Invocations/ API Analytics) from API Manager. However, this is realistically NOT TRUE. The reason is, API manager is just a management tool for API instances but all policies upon applying on APIs eventually gets executed on Mule Runtimes only (Either Embedded or API Proxy).
>> Similarly all API Implementations also run on Mule Runtimes.
So, most of the day required for monitoring and alerts are originated from Mule Runtimes only irrespective of whether the deployment model is MuleSoft-hosted or Customer-hosted or Hybrid.
The Line of Business (LoB) of an eCommerce company is requesting a process that sends automated notifications via email every time a new order is processed through the customer’s mobile application or through the internal company’s web application. In the future, multiple notification channels may be added: for example, text messages and push notifications.
What is the most effective API-led connectivity approach for the scenario described above?
- A . Create one Experience API for the web application and one for the mobile application.
Create a Process API to orchestrate and retrieve the email template from = database.
Create a System API that sends the email using the Anypoint Connector for Email.
Create one Experience API for the web application and one for the mobile application.
Create a Process API to orchestrate and retrieve the email template from = database.
Create a System API that sends the email using the Anypoint Connector for Email. - B . Create one Experience API for the web application and one for the mobile application,
Create a Process API to orchestrate, retrieve the email template from a database, and send the email using the Anypoint Connector for Email.
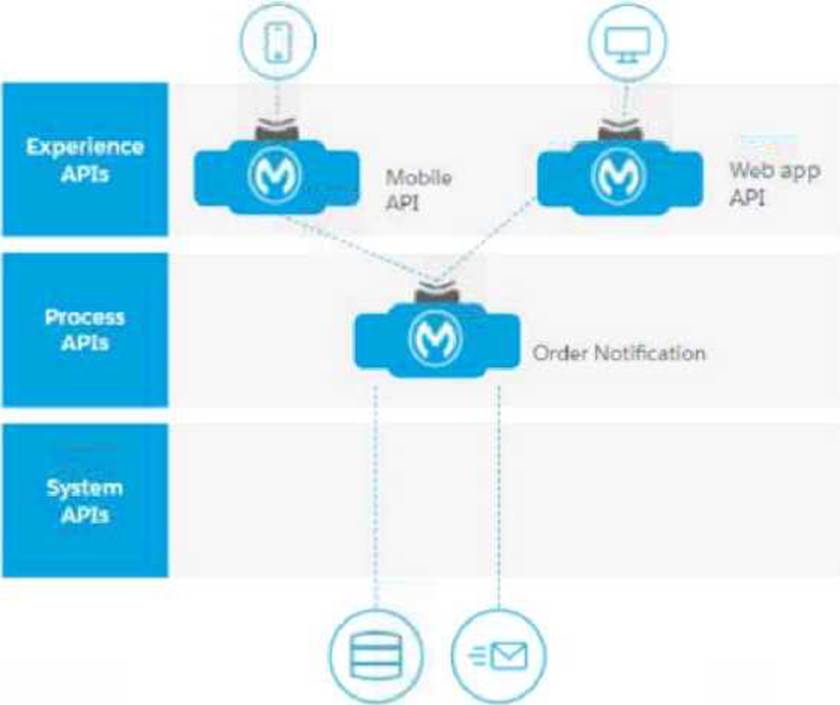
- C . Create Experience APIs for both the web application and mobile application.
Create a Process API ta orchestrate, retrieve the email template from e database, and send the email
using the Anypoint Connector for Email. - D . Create Experience APIs for both the web application and mobile application.
(Create 3 Process API to orchestrate and retrieve the email template from 2 databese.
Create a System API that sends the email using the Anypoint Connector for Email.
A
Explanation:
In this scenario, the best approach to satisfy the API-led connectivity principles and support future scalability is:
Experience APIs:
Create separate Experience APIs for the web application and the mobile application. This allows each application to have an optimized interface, supporting different needs and potential differences in request/response structures or security configurations.
Process API:
A single Process API can be used to orchestrate the workflow, including retrieving the email template
from a database and preparing the email content. By centralizing this logic in the Process layer, we can ensure it is reusable and easily adaptable for different notification channels in the future.
System API:
A System API specifically designed for sending emails (using the Anypoint Connector for Email) abstracts the email-sending functionality from the business logic. This approach ensures that the email-sending function is reusable and scalable, and it can easily be extended or modified if other notification channels (like SMS or push notifications) are added later.
Why Option A is Correct:
This structure aligns with API-led connectivity principles by separating concerns across Experience, Process, and System layers. It provides flexibility for future notification channels and isolates each layer’s responsibility, making it easier to maintain and scale. of Incorrect Options:
Option B lacks a separate System API for sending emails, which goes against the principle of isolating back-end functionality in System APIs.
Option C similarly lacks a dedicated System API, reducing flexibility and reusability.
Option D suggests creating multiple Process APIs for database retrieval, which adds unnecessary complexity and does not adhere to the single-orchestration principle typically followed in API-led design.
Reference
For further guidance on API-led connectivity and the responsibilities of each API layer, refer to MuleSoft’s documentation on API-led architecture and design best practices.
Which three tools automate the deployment of Mule applications? Choose 3 answers
- A . Runtime Manager
- B . Anypoint Platform CLI
- C . Platform APIs
- D . Anypoint Studio
- E . Mule Mayen plugin
- F . API Community Manager
ABC
Explanation:
MuleSoft offers various tools to automate the deployment of Mule applications, which can streamline deployment and management processes. Here’s how each tool supports automated deployment:
Runtime Manager:
Anypoint Runtime Manager is MuleSoft’s web-based interface that allows users to deploy, manage, and monitor applications directly. It provides deployment automation through its user-friendly interface.
Anypoint Platform CLI:
The Anypoint CLI enables scripting of deployment and management tasks, making it possible to automate deployments via command-line scripts. This tool is ideal for CI/CD pipelines as it integrates with automated processes.
Platform APIs:
MuleSoft’s Platform APIs allow programmatic access to deployment functions, enabling integration with external automation tools and CI/CD systems. These APIs facilitate deployment through RESTful calls, which can be automated for continuous delivery. of Incorrect Options:
Option D (Anypoint Studio) is primarily for development and does not support deployment automation.
Option E (Maven Plugin) can be used for building and deploying Mule applications but isn’t classified as a platform tool for deployment.
Option F (API Community Manager) is unrelated to deployment and instead focuses on managing
API communities.
Reference
For detailed steps on automating deployments with these tools, refer to MuleSoft documentation on
Runtime Manager, CLI, and Platform APIs.