
Practice Free MuleSoft Platform Architect I Exam Online Questions
An auto manufacturer has a mature CI/CD practice and wants to automate packaging and deployment of any Mule applications to various deployment targets, including CloudHub workers/replicas, customer-hosted Mule runtimes, and Anypoint Runtime Fabric.
Which MuleSoft-provided tool or component facilitates automating the packaging and deployment of Mule applications to various deployment targets as part of the company’s CI/CD practice?
- A . Anypoint Runtime Manager
- B . Mule Maven plugin
- C . Anypoint Platform CLI
- D . Anypoint Platform REST APIs
B
Explanation:
For organizations with established CI/CD practices, the Mule Maven plugin is the recommended tool for automating packaging and deployment across multiple environments, including CloudHub, on-premise Mule runtimes, and Anypoint Runtime Fabric.
Here’s why:
Automation with Maven:
The Mule Maven plugin allows for CI/CD integration by supporting automated build and deployment processes. It is commonly used in CI/CD pipelines to handle application packaging and deployment directly through Maven commands, making it ideal for teams that want consistent deployment automation across different MuleSoft environments.
Supported Deployment Targets:
The Mule Maven plugin supports deployment to various targets, including CloudHub, Runtime Fabric, and on-premises servers, thus meeting the needs of environments with diverse deployment destinations.
Why Option B is Correct:
The Mule Maven plugin is specifically designed for CI/CD pipelines and integrates with Jenkins, GitLab, and other CI/CD tools to facilitate continuous deployment. It is the most efficient MuleSoft-provided tool for this purpose.
of Incorrect Options:
Option A (Anypoint Runtime Manager) provides deployment management but does not automate CI/CD processes.
Option C (Anypoint Platform CLI) can script deployments but lacks direct integration with CI/CD tools.
Option D (Anypoint Platform REST APIs) requires custom scripting for deployment, which can be more complex than using the Mule Maven plugin.
Reference
For more details, refer to MuleSoft documentation on using the Mule Maven plugin for CI/CD.
What is true about the technology architecture of Anypoint VPCs?
- A . The private IP address range of an Anypoint VPC is automatically chosen by CloudHub
- B . Traffic between Mule applications deployed to an Anypoint VPC and on-premises systems can stay within a private network
- C . Each CloudHub environment requires a separate Anypoint VPC
- D . VPC peering can be used to link the underlying AWS VPC to an on-premises (non AWS) private network
B
Explanation:
Correct Answer Traffic between Mule applications deployed to an Anypoint VPC and on-premises systems can stay within a private network
>> The private IP address range of an Anypoint VPC is NOT automatically chosen by CloudHub. It is chosen by us at the time of creating VPC using thr CIDR blocks.
CIDR Block: The size of the Anypoint VPC in Classless Inter-Domain Routing (CIDR) notation. For example, if you set it to 10.111.0.0/24, the Anypoint VPC is granted 256 IP addresses from 10.111.0.0 to 10.111.0.255.
Ideally, the CIDR Blocks you choose for the Anypoint VPC come from a private IP space, and should not overlap with any other Anypoint VPC’s CIDR Blocks, or any CIDR Blocks in use in your corporate network.
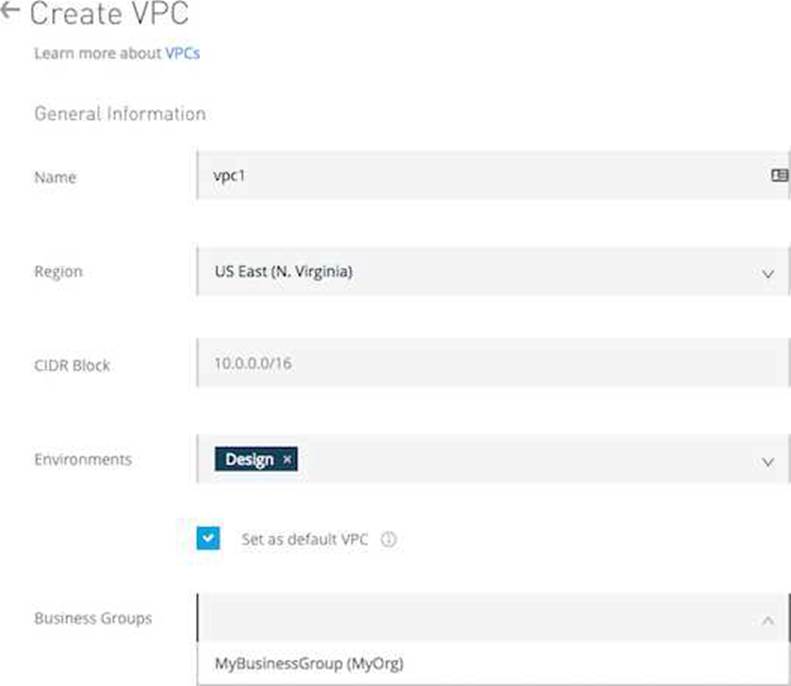
that each CloudHub environment requires a separate Anypoint VPC. Once an Anypoint VPC is created, we can choose a same VPC by multiple environments. However, it is generally a best and recommended practice to always have seperate Anypoint VPCs for Non-Prod and Prod environments.
>> We use Anypoint VPN to link the underlying AWS VPC to an on-premises (non AWS) private network. NOT VPC Peering.
Reference: https://docs.mulesoft.com/runtime-manager/vpn-about
Only true statement in the given choices is that the traffic between Mule applications deployed to an Anypoint VPC and on-premises systems can stay within a private network. https://docs.mulesoft.com/runtime-manager/vpc-connectivity-methods-concept
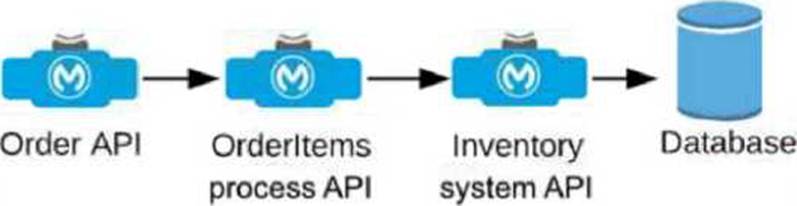
An Order API triggers a sequence of other API calls to look up details of an order’s items in a back-end inventory database. The Order API calls the OrderItems process API, which calls the Inventory system API. The Inventory system API performs database operations in the back-end inventory database.
The network connection between the Inventory system API and the database is known to be unreliable and hang at unpredictable times.
Where should a two-second timeout be configured in the API processing sequence so that the Order API never waits more than two seconds for a response from the Orderltems process API?
- A . In the Orderltems process API implementation
- B . In the Order API implementation
- C . In the Inventory system API implementation
- D . In the inventory database
A
Explanation:
Understanding the API Flow and Timeout Requirement:
The Order API initiates a call to the OrderItems process API, which in turn calls the Inventory system API to fetch details from the inventory database.
The requirement specifies that the Order API should not wait more than two seconds for a response
from the OrderItems process API, even if there are delays further down the chain (between
Inventory system API and the database).
Choosing the Appropriate Timeout Location:
Setting the timeout at the OrderItems process API level ensures that if the Inventory system API takes longer than two seconds to respond, the OrderItems process API will terminate the request and send a timeout response back to the Order API. This prevents the Order API from waiting indefinitely due to the unreliable connection to the database.
If the timeout were set in the Inventory system API or database, it would not help the Order API directly, as the OrderItems process API would still be waiting for a response. Detailed Analysis of Each Option:
Option A (Correct Answer): Setting the timeout in the OrderItems process API allows it to control how long it waits for a response from the Inventory system API. If the Inventory system API does not respond within two seconds, the OrderItems process API can terminate the call and return a timeout response to the Order API, meeting the requirement.
Option B: Setting the timeout in the Order API would not limit the wait time at the OrderItems process API level, meaning the OrderItems process API could still wait indefinitely for the Inventory system API, leading to a longer delay.
Option C: Setting the timeout in the Inventory system API only affects the connection to the database and does not influence how long the OrderItems process API waits for the Inventory system API’s response.
Option D: Setting a timeout in the database is not feasible in this context since database timeouts are
typically configured for database operations and would not directly control the API response times in
the overall API chain.
Conclusion:
Option A is the best choice, as it ensures that the OrderItems process API does not hold the Order API longer than the required two seconds, even if the downstream connection to the database hangs. This configuration aligns with MuleSoft best practices for setting timeouts in API orchestration to manage dependencies and prevent delays across a chain of API calls.
For additional information on timeout settings, refer to MuleSoft documentation on handling timeouts and API orchestration best practices.
When using CloudHub with the Shared Load Balancer, what is managed EXCLUSIVELY by the API implementation (the Mule application) and NOT by Anypoint Platform?
- A . The assignment of each HTTP request to a particular CloudHub worker
- B . The logging configuration that enables log entries to be visible in Runtime Manager
- C . The SSL certificates used by the API implementation to expose HTTPS endpoints
- D . The number of DNS entries allocated to the API implementation
C
Explanation:
Correct Answer The SSL certificates used by the API implementation to expose HTTPS endpoints >> The assignment of each HTTP request to a particular CloudHub worker is taken care by Anypoint Platform itself. We need not manage it explicitly in the API implementation and in fact we CANNOT manage it in the API implementation.
>> The logging configuration that enables log entries to be visible in Runtime Manager is ALWAYS managed in the API implementation and NOT just for SLB. So this is not something we do EXCLUSIVELY when using SLB.
>> We DO NOT manage the number of DNS entries allocated to the API implementation inside the code. Anypoint Platform takes care of this.
It is the SSL certificates used by the API implementation to expose HTTPS endpoints that is to be managed EXCLUSIVELY by the API implementation. Anypoint Platform does NOT do this when using SLBs.
What Anypoint Platform Capabilities listed below fall under APIs and API Invocations/Consumers category? Select TWO.
- A . API Operations and Management
- B . API Runtime Execution and Hosting
- C . API Consumer Engagement
- D . API Design and Development
D
Explanation:
Correct Answers: API Design and Development and API Runtime Execution and Hosting >> API Design and Development – Anypoint Studio, Anypoint Design Center, Anypoint Connectors
>> API Runtime Execution and Hosting – Mule Runtimes, CloudHub, Runtime Services
>> API Operations and Management – Anypoint API Manager, Anypoint Exchange
>> API Consumer Management – API Contracts, Public Portals, Anypoint Exchange, API Notebooks
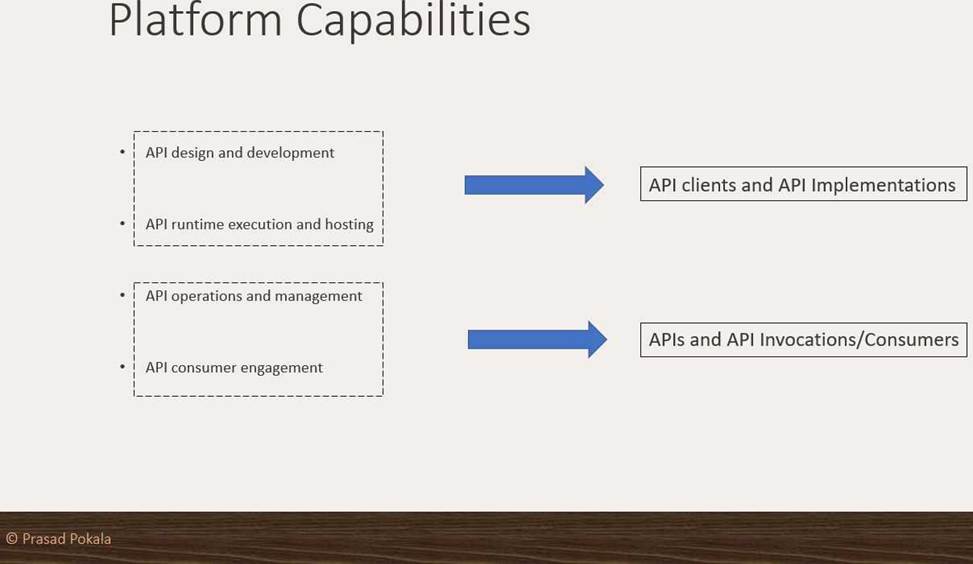
Correct Answers: API Operations and Management and API Consumer Engagement
>> API Design and Development – Anypoint Studio, Anypoint Design Center, Anypoint Connectors
>> API Runtime Execution and Hosting – Mule Runtimes, CloudHub, Runtime Services
>> API Operations and Management – Anypoint API Manager, Anypoint Exchange
>> API Consumer Management – API Contracts, Public Portals, Anypoint Exchange, API Notebooks
Bottom of Form
Top of Form
Version 3.0.1 of a REST API implementation represents time values in PST time using ISO 8601 hh:mm:ss format. The API implementation needs to be changed to instead represent time values in CEST time using ISO 8601 hh:mm:ss format.
When following the semver.org semantic versioning specification, what version should be assigned to the updated API implementation?
- A . 3.0.2
- B . 4.0.0
- C . 3.1.0
- D . 3.0.1
B
Explanation:
Correct Answer 4.0.0
As per semver.org semantic versioning specification:
Given a version number MAJOR.MINOR.PATCH, increment the:
– MAJOR version when you make incompatible API changes.
– MINOR version when you add functionality in a backwards compatible manner.
– PATCH version when you make backwards compatible bug fixes.
As per the scenario given in the question, the API implementation is completely changing its behavior. Although the format of the time is still being maintained as hh:mm:ss and there is no change in schema w.r.t format, the API will start functioning different after this change as the times are going to come completely different.
Example: Before the change, say, time is going as 09:00:00 representing the PST. Now on, after the change, the same time will go as 18:00:00 as Central European Summer Time is 9 hours ahead of Pacific Time.
>> This may lead to some uncertain behavior on API clients depending on how they are handling the times in the API response. All the API clients need to be informed that the API functionality is going to change and will return in CEST format. So, this considered as a MAJOR change and the version of API for this new change would be 4.0.0
A TemperatureSensors API instance is defined in API Manager in the PROD environment of the CAR_FACTORY business group. An AcmelemperatureSensors Mule application implements this API instance and is deployed from Runtime Manager to the PROD environment of the CAR_FACTORY business group. A policy that requires a valid client ID and client secret is applied in API Manager to the API instance.
Where can an API consumer obtain a valid client ID and client secret to call the AcmeTemperatureSensors Mule application?
- A . In secrets manager, request access to the Shared Secret static username/password
- B . In API Manager, from the PROD environment of the CAR_FACTORY business group
- C . In access management, from the PROD environment of the CAR_FACTORY business group
- D . In Anypoint Exchange, from an API client application that has been approved for the TemperatureSensors API instance
D
Explanation:
When an API policy requiring a client ID and client secret is applied to an API instance in API Manager, API consumers must obtain these credentials through a registered client application.
Here’s how it works:
Anypoint Exchange and Client Applications:
To access secured APIs, API consumers need to create or register a client application in Anypoint Exchange. This process involves requesting access to the specific API, and once approved, the consumer can retrieve the client ID and client secret associated with the application.
Why Option D is Correct:
Option D accurately describes the process, as the client ID and client secret are generated and managed within Anypoint Exchange. API consumers can use these credentials to authenticate with the TemperatureSensors API.
of Incorrect Options:
Option A (secrets manager) is incorrect because client credentials for API access are not managed via secrets manager.
Option B (API Manager) is incorrect as API Manager manages policies but does not provide client-specific credentials.
Option C (Access Management) does not apply, as Access Management is primarily used for user roles and permissions, not API client credentials. Reference
For further details on managing client applications in Anypoint Exchange, consult MuleSoft documentation on client application registration and API security policies.
A Rate Limiting policy is applied to an API implementation to protect the back-end system. Recently, there have been surges in demand that cause some API client POST requests to the API implementation to be rejected with policy-related errors, causing delays and complications to the API clients.
How should the API policies that are applied to the API implementation be changed to reduce the frequency of errors returned to API clients, while still protecting the back-end system?
- A . Keep the Rate Limiting policy and add 9 Client ID Enforcement policy
- B . Remove the Rate Limiting policy and add an HTTP Caching policy
- C . Remove the Rate Limiting policy and add a Spike Control policy
- D . Keep the Rate Limiting policy and add an SLA-based Spike Control policy
D
Explanation:
When managing high traffic to an API, especially with POST requests, it is crucial to ensure the API’s policies both protect the back-end systems and provide a smooth client experience. Here’s the approach to reducing errors:
Rate Limiting Policy: This policy enforces a limit on the number of requests within a defined time period. However, rate limiting alone may cause clients to hit limits during demand surges, leading to errors.
Adding an SLA-based Spike Control Policy:
Spike Control is designed to handle sudden increases in traffic by smoothing out bursts of requests, which is particularly useful during high-demand periods.
By configuring SLA-based Spike Control, you can define thresholds for specific client tiers. For instance, premium clients might have higher limits or more flexibility in traffic bursts than standard clients.
Why Option D is Correct:
Keeping the Rate Limiting policy continues to provide baseline protection for the back-end. Adding the SLA-based Spike Control policy allows for differentiated control, where requests are queued or delayed during bursts rather than outright rejected. This approach significantly reduces error responses to clients while still controlling overall traffic.
Of Incorrect Options:
Option A (adding Client ID Enforcement) would not reduce errors related to traffic surges.
Option B (HTTP Caching) is not applicable as caching is generally ineffective for non-idempotent requests like POST.
Option C (only Spike Control without Rate Limiting) may leave the back-end system vulnerable to sustained high traffic levels, reducing protection. Reference
For more information on configuring Rate Limiting and SLA-based Spike Control policies, refer to MuleSoft documentation on API Policies and Rate Limiting.
A Rate Limiting policy is applied to an API implementation to protect the back-end system. Recently, there have been surges in demand that cause some API client POST requests to the API implementation to be rejected with policy-related errors, causing delays and complications to the API clients.
How should the API policies that are applied to the API implementation be changed to reduce the frequency of errors returned to API clients, while still protecting the back-end system?
- A . Keep the Rate Limiting policy and add 9 Client ID Enforcement policy
- B . Remove the Rate Limiting policy and add an HTTP Caching policy
- C . Remove the Rate Limiting policy and add a Spike Control policy
- D . Keep the Rate Limiting policy and add an SLA-based Spike Control policy
D
Explanation:
When managing high traffic to an API, especially with POST requests, it is crucial to ensure the API’s policies both protect the back-end systems and provide a smooth client experience. Here’s the approach to reducing errors:
Rate Limiting Policy: This policy enforces a limit on the number of requests within a defined time period. However, rate limiting alone may cause clients to hit limits during demand surges, leading to errors.
Adding an SLA-based Spike Control Policy:
Spike Control is designed to handle sudden increases in traffic by smoothing out bursts of requests, which is particularly useful during high-demand periods.
By configuring SLA-based Spike Control, you can define thresholds for specific client tiers. For instance, premium clients might have higher limits or more flexibility in traffic bursts than standard clients.
Why Option D is Correct:
Keeping the Rate Limiting policy continues to provide baseline protection for the back-end. Adding the SLA-based Spike Control policy allows for differentiated control, where requests are queued or delayed during bursts rather than outright rejected. This approach significantly reduces error responses to clients while still controlling overall traffic.
Of Incorrect Options:
Option A (adding Client ID Enforcement) would not reduce errors related to traffic surges.
Option B (HTTP Caching) is not applicable as caching is generally ineffective for non-idempotent requests like POST.
Option C (only Spike Control without Rate Limiting) may leave the back-end system vulnerable to sustained high traffic levels, reducing protection. Reference
For more information on configuring Rate Limiting and SLA-based Spike Control policies, refer to MuleSoft documentation on API Policies and Rate Limiting.
The implementation of a Process API must change.
What is a valid approach that minimizes the impact of this change on API clients?
- A . Update the RAML definition of the current Process API and notify API client developers by sending them links to the updated RAML definition
- B . Postpone changes until API consumers acknowledge they are ready to migrate to a new Process API or API version
- C . Implement required changes to the Process API implementation so that whenever possible, the Process API’s RAML definition remains unchanged
- D . Implement the Process API changes in a new API implementation, and have the old API implementation return an HTTP status code 301 – Moved Permanently to inform API clients they should be calling the new API implementation
C
Explanation:
Correct Answer Implement required changes to the Process API implementation so that, whenever possible, the Process API’s RAML definition remains unchanged.
Key requirement in the question is:
>> Approach that minimizes the impact of this change on API clients Based on above:
>> Updating the RAML definition would possibly impact the API clients if the changes require any thing mandatory from client side. So, one should try to avoid doing that until really necessary.
>> Implementing the changes as a completely different API and then redirectly the clients with 3xx status code is really upsetting design and heavily impacts the API clients.
>> Organisations and IT cannot simply postpone the changes required until all API consumers acknowledge they are ready to migrate to a new Process API or API version. This is unrealistic and not possible.
The best way to handle the changes always is to implement required changes to the API implementations so that, whenever possible, the API’s RAML definition remains unchanged.