Practice Free MuleSoft Integration Architect I Exam Online Questions
An organization if struggling frequent plugin version upgrades and external plugin project dependencies. The team wants to minimize the impact on applications by creating best practices that will define a set of default dependencies across all new and in progress projects.
How can these best practices be achieved with the applications having the least amount of responsibility?
- A . Create a Mule plugin project with all the dependencies and add it as a dependency in each application’s POM.xml file
- B . Create a mule domain project with all the dependencies define in its POM.xml file and add each application to the domain Project
- C . Add all dependencies in each application’s POM.xml file
- D . Create a parent POM of all the required dependencies and reference each in each application’s POM.xml file
An organization is designing a mule application to support an all or nothing transaction between serval database operations and some other connectors so that they all roll back if there is a problem with any of the connectors
Besides the database connector, what other connector can be used in the transaction.
- A . VM
- B . Anypoint MQ
- C . SFTP
- D . ObjectStore
A
Explanation:
Correct answer is VM VM support Transactional Type. When an exception occur, The transaction rolls back to its original state for reprocessing. This feature is not supported by other connectors. Here is additional information about Transaction management:

A leading e-commerce giant will use Mulesoft API’s on runtime fabric (RTF) to process customer orders. Some customer’s sensitive information such as credit card information is also there as a part of a API payload.
What approach minimizes the risk of matching sensitive data to the original and can convert back to the original value whenever and wherever required?
- A . Apply masking to hide the sensitive information and then use API
- B . manager to detokenize the masking format to return the original value
- C . create a tokenization format and apply a tokenization policy to the API Gateway
- D . Used both masking and tokenization
- E . Apply a field level encryption policy in the API Gateway
An organization needs to enable access to their customer data from both a mobile app and a web application, which each need access to common fields as well as certain unique fields. The data is available partially in a database and partially in a 3rd-party CRM system.
What APIs should be created to best fit these design requirements?
- A . A Process API that contains the data required by both the web and mobile apps, allowing these applications to invoke it directly and access the data they need thereby providing the flexibility to add more fields in the future without needing API changes.
- B . One set of APIs (Experience API, Process API, and System API) for the web app, and another set for
the mobile app. - C . Separate Experience APIs for the mobile and web app, but a common Process API that invokes separate System APIs created for the database and CRM system
- D . A common Experience API used by both the web and mobile apps, but separate Process APIs for the web and mobile apps that interact with the database and the CRM System.
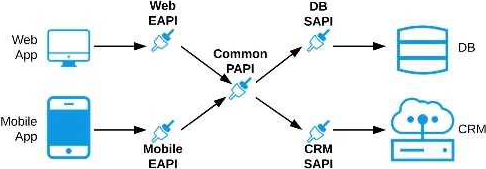
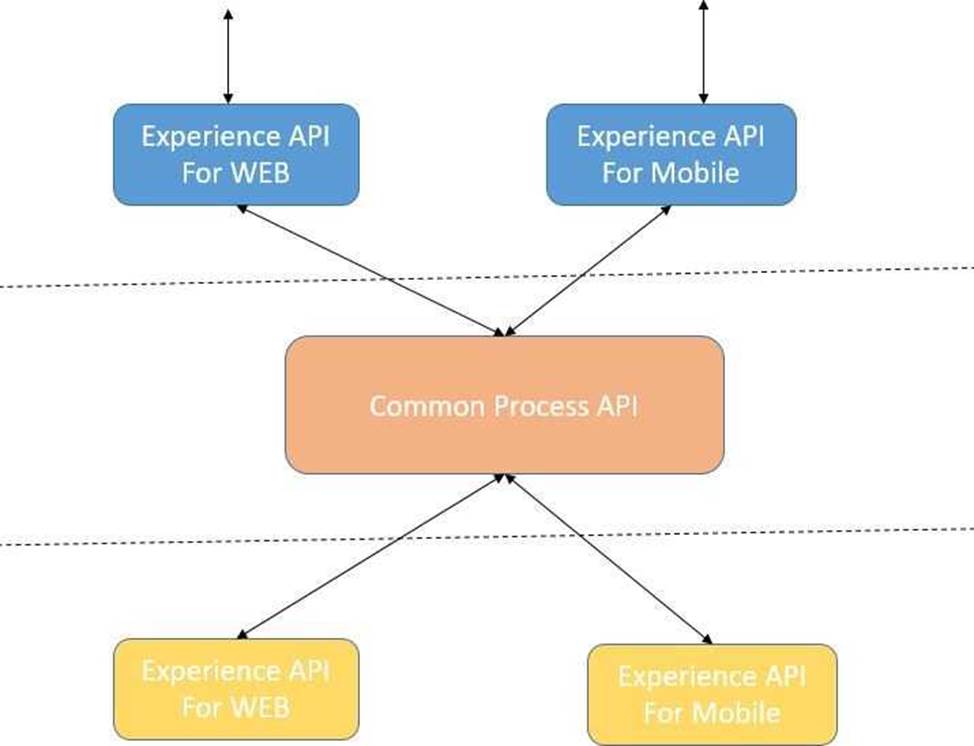
C
Explanation:
Lets analyze the situation in regards to the different options available Option: A common Experience API but separate Process APIs Analysis: This solution will not work because having common experience layer will not help the purpose as mobile and web applications will have different set of requirements which cannot be fulfilled by single experience layer API
Option: Common Process API Analysis: This solution will not work because creating a common process API will impose limitations in terms of flexibility to customize API;s as per the requirements of different applications. It is not a recommended approach.
Option: Separate set of API’s for both the applications Analysis: This goes against the principle of Anypoint API-led connectivity approach which promotes creating reusable assets. This solution may work but this is not efficient solution and creates duplicity of code.
Hence the correct answer is: Separate Experience APIs for the mobile and web app, but a common Process API that invokes separate System APIs created for the database and CRM system
Lets analyze the situation in regards to the different options available Option: A common Experience API but separate Process APIs Analysis: This solution will not work because having common experience layer will not help the purpose as mobile and web applications will have different set of requirements which cannot be fulfilled by single experience layer API
Option: Common Process API Analysis: This solution will not work because creating a common process API will impose limitations in terms of flexibility to customize API; s as per the requirements of different applications. It is not a recommended approach.
Option: Separate set of API’s for both the applications Analysis: This goes against the principle of Anypoint API-led connectivity approach which promotes creating reusable assets. This solution may work but this is not efficient solution and creates duplicity of code.
Hence the correct answer is: Separate Experience APIs for the mobile and web app, but a common Process API that invokes separate System APIs created for the database and CRM system
An organization uses a set of customer-hosted Mule runtimes that are managed using the Mulesoft-hosted control plane.
What is a condition that can be alerted on from Anypoint Runtime Manager without any custom components or custom coding?
- A . When a Mule runtime on a given customer-hosted server is experiencing high memory consumption during certain periods
- B . When an SSL certificate used by one of the deployed Mule applications is about to expire
- C . When the Mute runtime license installed on a Mule runtime is about to expire
- D . When a Mule runtime’s customer-hosted server is about to run out of disk space
A
Explanation:
Correct answer is When a Mule runtime on a given customer-hosted server is experiencing high memory consumption during certain periods Using Anypoint Monitoring, you can configure two different types of alerts: Basic alerts for servers and Mule apps Limit per organization: Up to 50 basic alerts for users who do not have a Titanium subscription to Anypoint Platform You can set up basic alerts to trigger email notifications when a metric you are measuring passes a specified threshold. You can create basic alerts for the following metrics for servers or Mule apps:
For on-premises servers and CloudHub apps:
* CPU utilization
* Memory utilization
* Thread count Advanced alerts for graphs in custom dashboards in Anypoint Monitoring.
You must have a Titanium subscription to use this feature. Limit per organization: Up to 20 advanced alerts
A Mule application is being designed to do the following:
Step 1: Read a SalesOrder message from a JMS queue, where each SalesOrder consists of a header and a list of SalesOrderLineltems.
Step 2: Insert the SalesOrder header and each SalesOrderLineltem into different tables in an RDBMS. Step 3: Insert the SalesOrder header and the sum of the prices of all its SalesOrderLineltems into a table In a different RDBMS.
No SalesOrder message can be lost and the consistency of all SalesOrder-related information in both RDBMSs must be ensured at all times.
What design choice (including choice of transactions) and order of steps addresses these requirements?
- A . 1) Read the JMS message (NOT in an XA transaction)
2) Perform BOTH DB inserts in ONE DB transaction
3) Acknowledge the JMS message - B . 1) Read the JMS message (NOT in an XA transaction)
2) Perform EACH DB insert in a SEPARATE DB transaction
3) Acknowledge the JMS message - C . 1) Read the JMS message in an XA transaction
2) In the SAME XA transaction, perform BOTH DB inserts but do NOT acknowledge the JMS message - D . 1) Read and acknowledge the JMS message (NOT in an XA transaction)
2) In a NEW XA transaction, perform BOTH DB inserts
A
Explanation:
● Option A says "Perform EACH DB insert in a SEPARATE DB transaction". In this case if first DB insert is successful and second one fails then first insert won’t be rolled back causing inconsistency. This option is ruled out.
● Option D says Perform BOTH DB inserts in ONE DB transaction.
Rule of thumb is when one or more DB connections are required we must use XA transaction as local transactions support only one resource. So this option is also ruled out.
● Option B acknowledges the before DB processing, so message is removed from the queue. In case of system failure at later point, message can’t be retrieved.
● Option C is Valid: Though it says "do not ack JMS message", message will be auto acknowledged at the end of transaction. Here is how we can ensure all components are part of XA transaction: https://docs.mulesoft.com/jms-connector/1.7/jms-transactions
Additional Information about transactions:
● XA Transactions – You can use an XA transaction to group together a series of operations from multiple transactional resources, such as JMS, VM or JDBC resources, into a single, very reliable, global transaction.
● The XA (eXtended Architecture) standard is an X/Open group standard which specifies the interface between a global transaction manager and local transactional resource managers.
The XA protocol defines a 2-phase commit protocol which can be used to more reliably coordinate and sequence a series of "all or nothing" operations across multiple servers, even servers of different types
● Use JMS ack if
C Acknowledgment should occur eventually, perhaps asynchronously
C The performance of the message receipt is paramount
C The message processing is idempotent
C For the choreography portion of the SAGA pattern
● Use JMS transactions
C For all other times in the integration you want to perform an atomic unit of work
C When the unit of work comprises more than the receipt of a single message
C To simply and unify the programming model (begin/commit/rollback)
An application deployed to a runtime fabric environment with two cluster replicas is designed to periodically trigger of flow for processing a high-volume set of records from the source system and synchronize with the SaaS system using the Batch job scope
After processing 1000 records in a periodic synchronization of 1 lakh records, the replicas in which batch job instance was started went down due to unexpected failure in the runtime fabric environment
What is the consequence of losing the replicas that run the Batch job instance?
- A . The remaining 99000 records will be lost and left and processed
- B . The second replicas will take over processing the remaining 99000 records
- C . A new replacement replica will be available and will be process all 1,00,000 records from scratch leading to duplicate record processing
- D . A new placement replica will be available and will take or processing the remaining 99,000 records
Refer to the exhibit.
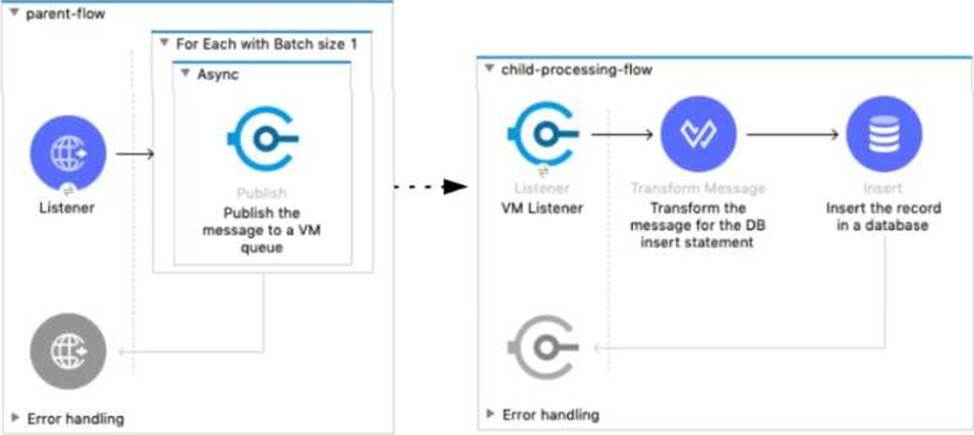
A Mule 4 application has a parent flow that breaks up a JSON array payload into 200 separate items, then sends each item one at a time inside an Async scope to a VM queue.
A second flow to process orders has a VM Listener on the same VM queue. The rest of this flow processes each received item by writing the item to a database.
This Mule application is deployed to four CloudHub workers with persistent queues enabled.
What message processing guarantees are provided by the VM queue and the CloudHub workers, and how are VM messages routed among the CloudHub workers for each invocation of the parent flow under normal operating conditions where all the CloudHub workers remain online?
- A . EACH item VM message is processed AT MOST ONCE by ONE CloudHub worker, with workers chosen in a deterministic round-robin fashion Each of the four CloudHub workers can be expected to process 1/4 of the Item VM messages (about 50 items)
- B . EACH item VM message is processed AT LEAST ONCE by ONE ARBITRARY CloudHub worker Each of the four CloudHub workers can be expected to process some item VM messages
- C . ALL Item VM messages are processed AT LEAST ONCE by the SAME CloudHub worker where the parent flow was invoked
This one CloudHub worker processes ALL 200 item VM messages - D . ALL item VM messages are processed AT MOST ONCE by ONE ARBITRARY CloudHub worker This one CloudHub worker processes ALL 200 item VM messages
B
Explanation:
Correct answer is EACH item VM message is processed AT LEAST ONCE by ONE ARBITRARY CloudHub worker. Each of the four CloudHub workers can be expected to process some item VM messages In Cloudhub, each persistent VM queue is listened on by every CloudHub worker – But each message is read and processed at least once by only one CloudHub worker and the duplicate processing is possible – If the CloudHub worker fails, the message can be read by another worker to prevent loss of messages and this can lead to duplicate processing – By default, every CloudHub worker’s VM Listener receives different messages from VM Queue Referenece: https://dzone.com/articles/deploying-mulesoft-application-on-1-worker-vs-mult
A company is building an application network and has deployed four Mule APIs: one experience API, one process API, and two system APIs. The logs from all the APIs are aggregated in an external log aggregation tool. The company wants to trace messages that are exchanged between multiple API implementations.
What is the most idiomatic (based on its intended use) identifier that should be used to implement Mule event tracing across the multiple API implementations?
- A . Mule event ID
- B . Mule correlation ID
- C . Client’s IP address
- D . DataWeave UUID
B
Explanation:
Correct answer is Mule correlation ID By design, Correlation Ids cannot be changed within a flow in Mule 4 applications and can be set only at source. This ID is part of the Event Context and is generated as soon as the message is received by the application. When a HTTP Request is received, the request is inspected for "X-Correlation-Id" header. If "X-Correlation-Id" header is present, HTTP connector uses this as the Correlation Id. If "X-Correlation-Id" header is NOT present, a Correlation Id is randomly generated. For Incoming HTTP Requests: In order to set a custom Correlation Id, the client invoking the HTTP request must set "X-Correlation-Id" header. This will ensure that the Mule Flow uses this Correlation Id. For Outgoing HTTP Requests: You can also propagate the existing Correlation Id to downstream APIs. By default, all outgoing HTTP Requests send "X-Correlation-Id" header. However, you can choose to set a different value to "X-Correlation-Id" header or set "Send Correlation Id" to NEVER.
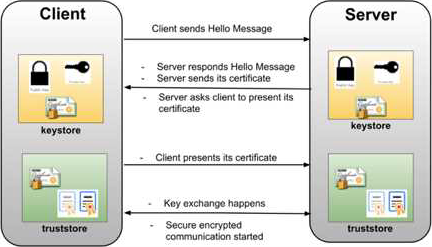
What requires configuration of both a key store and a trust store for an HTTP Listener?
- A . Support for TLS mutual (two-way) authentication with HTTP clients
- B . Encryption of requests to both subdomains and API resource endpoints fhttPs://aDi.customer.com/ and https://customer.com/api)
- C . Encryption of both HTTP request and HTTP response bodies for all HTTP clients
- D . Encryption of both HTTP request header and HTTP request body for all HTTP clients
A
Explanation:
1 way SSL: The server presents its certificate to the client and the client adds it to its list of trusted certificate. And so, the client can talk to the server.
2-way SSL: The same principle but both ways. i.e. both the client and the server has to establish trust between themselves using a trusted certificate. In this way of a digital handshake, the server needs to present a certificate to authenticate itself to client and client has to present its certificate to server.
* TLS is a cryptographic protocol that provides communications security for your Mule app.
* TLS offers many different ways of exchanging keys for authentication, encrypting data, and guaranteeing message integrity Keystores and Truststores Truststore and keystore contents differ depending on whether they are used for clients or servers:
For servers: the truststore contains certificates of the trusted clients, the keystore contains the
private and public key of the server. For clients: the truststore contains certificates of the trusted servers, the keystore contains the private and public key of the client.
Adding both a keystore and a truststore to the configuration implements two-way TLS authentication also known as mutual authentication.
* in this case, correct answer is Support for TLS mutual (two-way) authentication with HTTP clients.