
Practice Free MLA-C01 Exam Online Questions
HOTSPOT
A company needs to combine data from multiple sources. The company must use Amazon Redshift Serverless to query an AWS Glue Data Catalog database and underlying data that is stored in an Amazon S3 bucket.
Select and order the correct steps from the following list to meet these requirements. Select each step one time or not at all. (Select and order three.)
• Attach the IAM role to the Redshift cluster.
• Attach the IAM role to the Redshift namespace.
• Create an external database in Amazon Redshift to point to the Data Catalog schema.
• Create an external schema in Amazon Redshift to point to the Data Catalog database.
• Create an IAM role for Amazon Redshift to use to access only the S3 bucket that contains underlying data.
• Create an IAM role for Amazon Redshift to use to access the Data Catalog and the S3 bucket that contains underlying data.

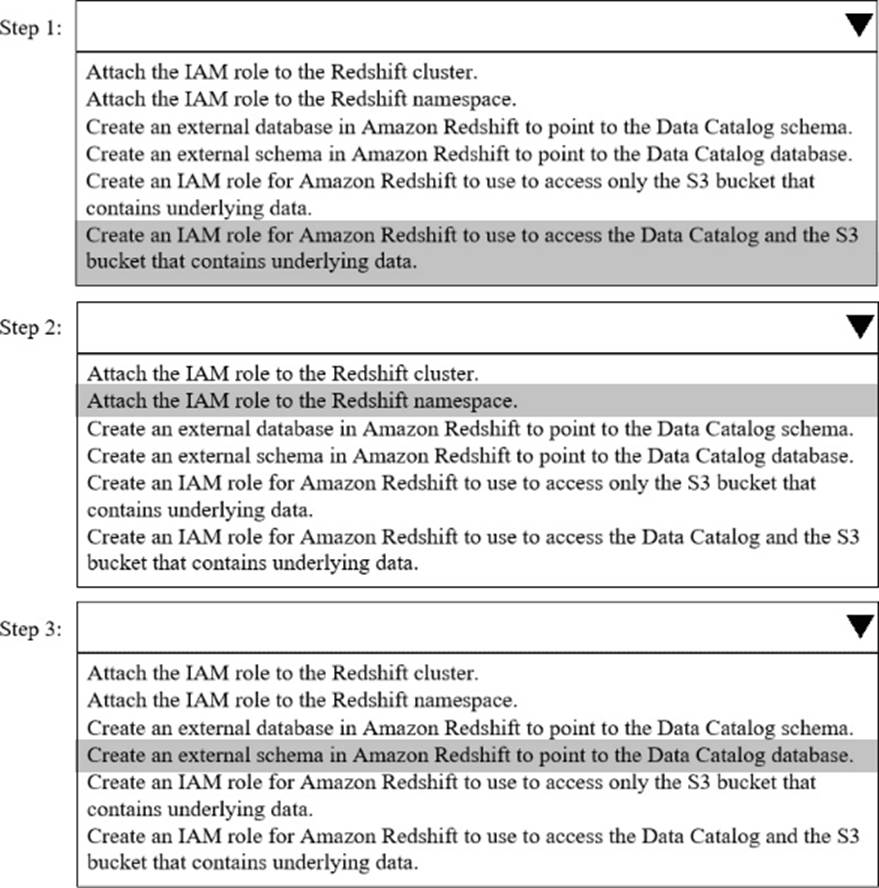
Explanation:
Step 1
Create an IAM role for Amazon Redshift to use to access the Data Catalog and the S3 bucket that contains underlying data.
This role must include:
Permissions for AWS Glue Data Catalog (e.g., glue:GetDatabase, glue:GetTables)
Permissions for the Amazon S3 bucket that stores the underlying data
Step 2
Attach the IAM role to the Redshift namespace.
Redshift Serverless uses a namespace, not a cluster, so the role must be associated with the namespace to allow Redshift to assume it when querying external data.
Step 3
Create an external schema in Amazon Redshift to point to the Data Catalog database.
The external schema maps Redshift to the Glue Data Catalog database so Redshift can query the tables stored in S3.
A company has a large collection of chat recordings from customer interactions after a product
release. An ML engineer needs to create an ML model to analyze the chat data. The ML engineer needs to determine the success of the product by reviewing customer sentiments about the product.
Which action should the ML engineer take to complete the evaluation in the LEAST amount of time?
- A . Use Amazon Rekognition to analyze sentiments of the chat conversations.
- B . Train a Naive Bayes classifier to analyze sentiments of the chat conversations.
- C . Use Amazon Comprehend to analyze sentiments of the chat conversations.
- D . Use random forests to classify sentiments of the chat conversations.
C
Explanation:
Amazon Comprehend is a fully managed natural language processing (NLP) service that includes a built-in sentiment analysis feature. It can quickly and efficiently analyze text data to determine whether the sentiment is positive, negative, neutral, or mixed. Using Amazon Comprehend requires minimal setup and provides accurate results without the need to train and deploy custom models, making it the fastest and most efficient solution for this task.
A company wants to migrate ML models from an on-premises environment to Amazon SageMaker AI. The models are based on the PyTorch algorithm. The company needs to reuse its existing custom scripts as much as possible.
Which SageMaker AI feature should the company use?
- A . SageMaker AI built-in algorithms
- B . SageMaker Canvas
- C . SageMaker JumpStart
- D . SageMaker AI script mode
D
Explanation:
SageMaker script mode allows ML engineers to bring existing training scripts written for frameworks such as PyTorch and TensorFlow directly into SageMaker with minimal changes. AWS documentation explicitly states that script mode is designed to support migration of existing ML workloads.
With script mode, the user provides a custom training script, and SageMaker handles infrastructure provisioning, distributed training, logging, and model artifact storage. This makes script mode ideal for companies that want to reuse established codebases without rewriting them.
Built-in algorithms require adopting AWS-provided implementations. SageMaker Canvas is a no-code tool, and JumpStart provides pretrained models and templates but does not focus on custom script reuse.
Therefore, Option D is the correct and AWS-recommended choice.
A company has significantly increased the amount of data stored as .csv files in an Amazon S3 bucket.
Data transformation scripts and queries are now taking much longer than before.
An ML engineer must implement a solution to optimize the data for query performance with the LEAST operational overhead.
Which solution will meet this requirement?
- A . Configure an AWS Lambda function to split the .csv files into smaller objects.
- B . Configure an AWS Glue job to drop string-type columns and save the results to S3.
- C . Configure an AWS Glue ETL job to convert the .csv files to Apache Parquet format.
- D . Configure an Amazon EMR cluster to process the data in S3.
C
Explanation:
AWS strongly recommends converting large CSV datasets into columnar formats such as Apache Parquet to improve query performance. Parquet reduces I/O by reading only the required columns and applies compression, which significantly speeds up analytics workloads.
AWS Glue ETL jobs provide a fully managed, serverless way to perform this conversion with minimal operational overhead. Once converted, the Parquet files can be queried efficiently by services such as Amazon Athena, Redshift Spectrum, and SageMaker processing jobs.
Splitting CSV files does not address inefficient storage format. Dropping columns risks data loss. Amazon EMR introduces infrastructure management overhead and is unnecessary for a straightforward format conversion.
AWS documentation clearly identifies CSV-to-Parquet conversion using Glue ETL as a best practice for scalable analytics.
Therefore, Option C is the correct answer.
A company is running ML models on premises by using custom Python scripts and proprietary datasets. The company is using PyTorch. The model building requires unique domain knowledge. The company needs to move the models to AWS.
Which solution will meet these requirements with the LEAST effort?
- A . Use SageMaker built-in algorithms to train the proprietary datasets.
- B . Use SageMaker script mode and premade images for ML frameworks.
- C . Build a container on AWS that includes custom packages and a choice of ML frameworks.
- D . Purchase similar production models through AWS Marketplace.
B
Explanation:
SageMaker script mode allows you to bring existing custom Python scripts and run them on AWS with minimal changes. SageMaker provides prebuilt containers for ML frameworks like PyTorch, simplifying the migration process. This approach enables the company to leverage their existing Python scripts and domain knowledge while benefiting from the scalability and managed environment of SageMaker. It requires the least effort compared to building custom containers or retraining models from scratch.
A company uses Amazon Athena to query a dataset in Amazon S3. The dataset has a target variable that the company wants to predict.
The company needs to use the dataset in a solution to determine if a model can predict the target variable.
Which solution will provide this information with the LEAST development effort?
- A . Create a new model by using Amazon SageMaker Autopilot. Report the model’s achieved performance.
- B . Implement custom scripts to perform data pre-processing, multiple linear regression, and performance evaluation. Run the scripts on Amazon EC2 instances.
- C . Configure Amazon Macie to analyze the dataset and to create a model. Report the model’s achieved performance.
- D . Select a model from Amazon Bedrock. Tune the model with the data. Report the model’s achieved performance.
A
Explanation:
The requirement is to quickly determine whether the target variable is predictable, with minimal development effort. Amazon SageMaker Autopilot is specifically designed for this purpose.
SageMaker Autopilot automatically handles data preprocessing, feature engineering, algorithm selection, model training, and evaluation. It generates multiple candidate models and provides detailed performance metrics, allowing teams to quickly assess predictability without writing custom code.
Option B requires significant manual development.
Option C is incorrect because Amazon Macie is a data security and classification service, not an ML modeling service.
Option D is unsuitable because Amazon Bedrock models are not intended for structured tabular prediction tasks.
Therefore, SageMaker Autopilot provides the fastest and least effort solution.
A company is planning to use Amazon Redshift ML in its primary AWS account. The source data is in an Amazon S3 bucket in a secondary account.
An ML engineer needs to set up an ML pipeline in the primary account to access the S3 bucket in the secondary account. The solution must not require public IPv4 addresses.
Which solution will meet these requirements?
- A . Provision a Redshift cluster and Amazon SageMaker Studio in a VPC with no public access enabled in the primary account. Create a VPC peering connection between the accounts. Update the VPC route tables to remove the route to 0.0.0.0/0.
- B . Provision a Redshift cluster and Amazon SageMaker Studio in a VPC with no public access enabled in the primary account. Create an AWS Direct Connect connection and a transit gateway. Associate the VPCs from both accounts with the transit gateway. Update the VPC route tables to remove the route to 0.0.0.0/0.
- C . Provision a Redshift cluster and Amazon SageMaker Studio in a VPC in the primary account. Create an AWS Site-to-Site VPN connection with two encrypted IPsec tunnels between the accounts. Set up interface VPC endpoints for Amazon S3.
- D . Provision a Redshift cluster and Amazon SageMaker Studio in a VPC in the primary account. Create an S3 gateway endpoint. Update the S3 bucket policy to allow IAM principals from the primary account. Set up interface VPC endpoints for SageMaker and Amazon Redshift.
D
Explanation:
S3 Gateway Endpoint: Allows private access to S3 from within a VPC without requiring a public IPv4 address, ensuring that data transfer between the primary and secondary accounts is secure and private.
Bucket Policy Update: The S3 bucket policy in the secondary account must explicitly allow access from the primary account’s IAM principals to provide the necessary permissions.
Interface VPC Endpoints: Required for private communication between the VPC and Amazon SageMaker and Amazon Redshift services, ensuring the solution operates without public internet access.
This configuration meets the requirement to avoid public IPv4 addresses and allows secure and private communication between the accounts.
A company is running ML models on premises by using custom Python scripts and proprietary datasets. The company is using PyTorch. The model building requires unique domain knowledge. The company needs to move the models to AWS.
Which solution will meet these requirements with the LEAST development effort?
- A . Use SageMaker AI built-in algorithms to train the proprietary datasets.
- B . Use SageMaker AI script mode and premade images for ML frameworks.
- C . Build a container on AWS that includes custom packages and a choice of ML frameworks.
- D . Purchase similar production models through AWS Marketplace.
B
Explanation:
The company already has custom Python training scripts, proprietary datasets, and uses PyTorch, with significant domain-specific logic embedded in the model. The goal is to migrate these workloads to AWS with the least development effort.
According to AWS documentation, Amazon SageMaker AI script mode is explicitly designed for this scenario. Script mode allows customers to bring their existing training scripts with minimal or no code changes and run them using prebuilt SageMaker framework containers, including PyTorch. This approach eliminates the need to redesign models or rewrite training logic while still benefiting from SageMaker’s managed infrastructure, scalability, monitoring, and security.
Option A is incorrect because SageMaker built-in algorithms require adapting data formats and training logic to AWS-provided implementations, which would increase development effort and may not support proprietary domain logic.
Option C is also incorrect because building and maintaining a custom container requires additional effort for containerization, dependency management, security updates, and lifecycle maintenance― making it more complex than necessary.
Option D is not viable because purchasing models from AWS Marketplace would not support the company’s proprietary datasets or unique domain knowledge embedded in existing models.
Therefore, using SageMaker AI script mode with prebuilt PyTorch containers is the fastest, most efficient, and AWS-recommended migration path that minimizes development effort while preserving existing workflows.
A company ingests sales transaction data using Amazon Data Firehose into Amazon OpenSearch Service. The Firehose buffer interval is set to 60 seconds.
The company needs sub-second latency for a real-time OpenSearch dashboard.
Which architectural change will meet this requirement?
- A . Use zero buffering in the Firehose stream and tune the PutRecordBatch batch size.
- B . Replace Firehose with AWS DataSync and enhanced fan-out consumers.
- C . Increase the Firehose buffer interval to 120 seconds.
- D . Replace Firehose with Amazon SQS.
A
Explanation:
Amazon Data Firehose supports near real-time delivery by configuring the buffer interval and buffer size. AWS documentation states that setting the buffer interval to the minimum (as low as 1 second) enables low-latency ingestion.
By using zero or minimal buffering and tuning PutRecordBatch, data is delivered to OpenSearch almost immediately, enabling sub-second dashboard updates.
DataSync and SQS are not designed for real-time streaming analytics. Increasing the buffer interval worsens latency.
AWS explicitly recommends Firehose with minimal buffering for real-time OpenSearch ingestion.
Therefore, Option A is the correct and AWS-verified solution.
Case study
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model’s algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
Before the ML engineer trains the model, the ML engineer must resolve the issue of the imbalanced data.
Which solution will meet this requirement with the LEAST operational effort?
- A . Use Amazon Athena to identify patterns that contribute to the imbalance. Adjust the dataset accordingly.
- B . Use Amazon SageMaker Studio Classic built-in algorithms to process the imbalanced dataset.
- C . Use AWS Glue DataBrew built-in features to oversample the minority class.
- D . Use the Amazon SageMaker Data Wrangler balance data operation to oversample the minority class.
D
Explanation:
Problem Description:
The training dataset has a class imbalance, meaning one class (e.g., fraudulent transactions) has fewer samples compared to the majority class (e.g., non-fraudulent transactions). This imbalance affects the model’s ability to learn patterns from the minority class.
Why SageMaker Data Wrangler?
SageMaker Data Wrangler provides a built-in operation called "Balance Data," which includes oversampling and undersampling techniques to address class imbalances.
Oversampling the minority class replicates samples of the minority class, ensuring the algorithm receives balanced inputs without significant additional operational overhead.
Steps to Implement:
Import the dataset into SageMaker Data Wrangler.
Apply the "Balance Data" operation and configure it to oversample the minority class.
Export the balanced dataset for training.
Advantages:
Ease of Use: Minimal configuration is required.
Integrated Workflow: Works seamlessly with the SageMaker ecosystem for preprocessing and model training.
Time Efficiency: Reduces manual effort compared to external tools or scripts.