
Practice Free GES-C01 Exam Online Questions
A company is building a chatbot for internal support, powered by Snowflake Cortex LLMs. The primary goals are to provide answers that are accurate, grounded in proprietary documentation, and to minimize factual ‘hallucinations’. They are considering various strategies to achieve this.
Which of the following statements correctly describe effective methods or tools within Snowflake for addressing these concerns?
- A . Deploying a custom fine-tuned model using SNOWFLAKE.CORTEX.FINETUNE on proprietary documentation is the most effective approach to ensure factual accuracy for any LLM task.
- B . Using Cortex Search as a Retrieval Augmented Generation (RAG) engine can enhance LLM responses by providing relevant context from proprietary documentation, thereby reducing hallucinations.
- C . AI Observability can be leveraged to systematically evaluate applications, measuring metrics like ‘factual correctness and ‘groundedness’ to detect and mitigate hallucinations, especially in summarization.
- D . For tasks requiring LLMs to generate SQL queries from natural language, using the Cortex Analyst verified Query Repository (VQR) can improve accuracy by leveraging pre-verified SQL queries for similar questions.
- E . Enabling Cortex Guard with guardrails: true directly addresses model hallucinations by ensuring responses are always factually correct and aligned with the provided context.
B,C,D
Explanation:
Option B is correct: Cortex Search is explicitly designed as a RAG engine to enhance LLM responses with contextualized information from Snowflake data, which directly addresses factual accuracy and reduces hallucinations.
Option C is correct: AI Observability’s evaluation features, including ‘factual correctness and ‘groundednes’ scores, are specifically mentioned for detecting the truthfulness and relevance of responses based on retrieved context, and for avoiding LLMs with high hallucination frequencies, especially in summarization tasks.
Option D is correct: The Cortex Analyst Verified Query Repository (VQR) provides a collection of pre-verified SQL queries for specific natural language questions, significantly improving the accuracy and trustworthiness of SQL generation and reducing errors that could be seen as ‘hallucinations’ in the text-to-SQL context.
Option A is incorrect: While fine-tuning (using ‘SNOWFLAKE.CORTEX.FINETUNE) can adapt a model to specific tasks and data, it is not a direct guarantee against ‘all’ factual inaccuracies or ‘hallucinations’ for ‘any’ LLM task, especially if the fine- tuning data itself is limited or the model generalizes poorly. RAG is generally preferred for grounding responses in up-to-date external knowledge.
Option E is incorrect: Cortex Guard is designed to filter ‘harmful or unsafe’ LLM responses, not to directly ensure factual correctness or prevent hallucinations related to content accuracy or grounding.
A data engineering team needs to establish an automated pipeline in Snowflake to continuously extract ‘contract_id’ and effective_date’ from new PDF contract documents uploaded to an internal stage named They have a pre-trained Document AI model named ‘contract_processor’.
Which of the following sets of SQL commands correctly configures the necessary Snowflake objects for this automated processing pipeline, including handling file access and initial data loading?
A )
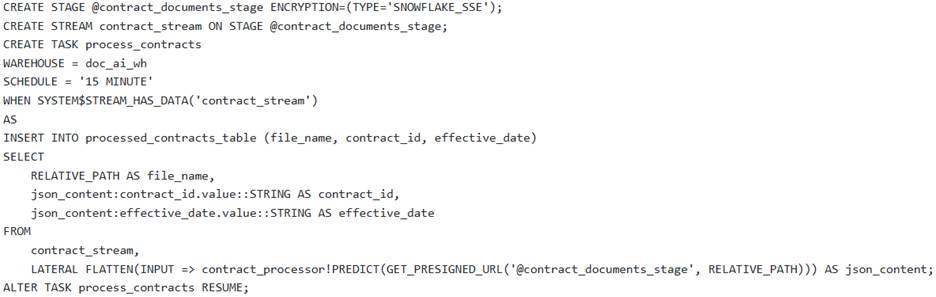
B )
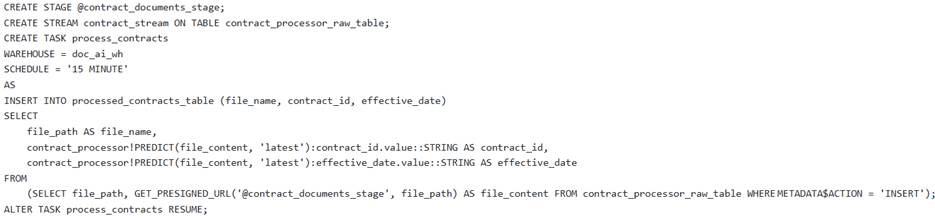
C )
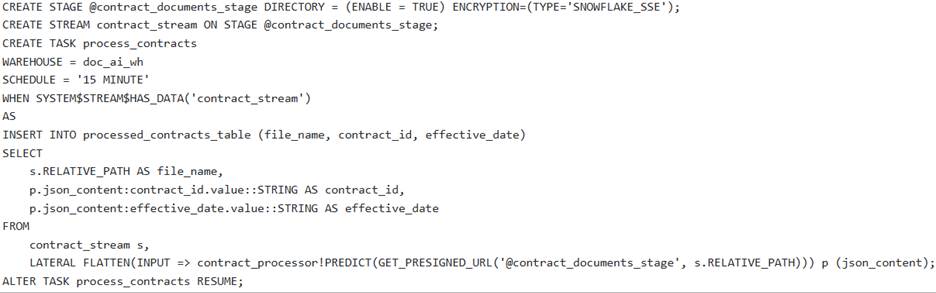
D )
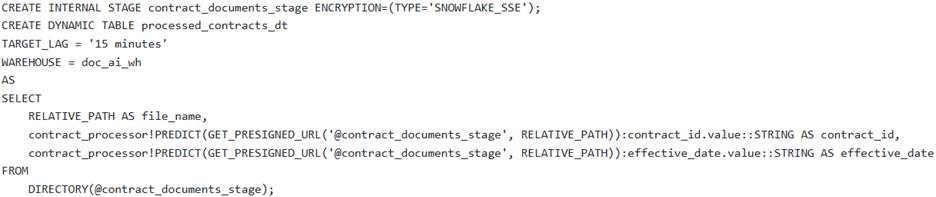
E )

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
C
Explanation:

An analytics engineering team is building a complex, real-time data pipeline in Snowflake. They want to automatically summarize new incoming product reviews using SNOWFLAKE. CORTEX. SUMMARIZE as part of a continuous process. They consider integrating this function into a dynamic table definition for efficient, automated refreshes.
Which of the following statements regarding the integration of SNOWFLAKE. CORTEX. SUMMARIZE with Snowflake’s data pipeline features is true?
- A . SNOWFLAKE. CORTEX. SUMMARIZE can be directly used within a dynamic table’s SELECT statement, enabling real-time summarization with automated refreshes, provided the source data is a stream.
- B . Snowflake Cortex functions, including SNOWFLAKE. CORTEX.SUMMARIZE, are explicitly incompatible with dynamic tables, requiring alternative automation methods such as streams and tasks.
- C . While SNOWFLAKE. CORTEX. SUMMARIZE does not support dynamic tables, its updated version, is fully compatible with dynamic tables for continuous summarization.
- D . SNOWFLAKE. CORTEX. SUMMARIZE can be used with dynamic tables if the TARGET_LAG is explicitly set to ‘1 day’ or longer, allowing for asynchronous processing.
- E . SNOWFLAKE. CORTEX. SUMMARIZE is supported in dynamic tables only if a Snowpark-optimized warehouse is explicitly assigned to the dynamic table for processing.
B
Explanation:
Option B is correct. The sources explicitly state that ‘Snowflake Cortex functions do not support dynamic tables’. This limitation applies to ‘SUMMARIZE’ (SNOWFLAKE.CORTEX). Therefore, attempting to use it directly in a dynamic table would result in a failure.
Option A is incorrect due to this explicit limitation.
Option C is incorrect; while is an updated function, there is no indication that it overcomes the fundamental incompatibility of Cortex functions with dynamic tables.
Option D and E propose non-existent conditions for compatibility.
A data scientist wants to fine-tune a mistral -7b model to improve its ability to generate specific product descriptions based on brief input features. They have a table named PRODUCT_CATALOG with columns
PRODUCT_FEATURES (text) and GENERATED_DESCRIPTION (text).
Which of the following statements correctly describe the preparation and initiation of this fine-tuning job in Snowflake Cortex? (Select all that apply)
- A . The FINETUNE function requires that the training data explicitly includes a system role message to define the model’s persona for optimal output during fine-tuning.
- B . The SQL query for the training data must select columns aliased as prompt and completion, such as:
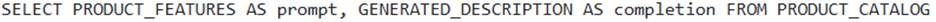
- C . The fine-tuning job must be created using a CREATE SNOWFLAKE.ML. FINETUNE command, similar to how ANOMALY_DETECTION models are created, to register the model object.
- D . O To generate highly structured completion data for fine-tuning, the AI_COMPLETE function with the response_format argument can be used in a prior step to ensure JSON adherence.
- E . Once a fine-tuned model is created, it is fully managed by the Snowflake Model Registry API, allowing for programmatic updates to its parameters and versions.
B,D
Explanation:
Option A is incorrect. While prompt engineering with system roles is crucial for general COMPLETE function calls, the FINETUNE training data query only requires prompt and completion columns. It does not explicitly require system role messages within the training data format itself.
Option B is correct. The FINETUNE function’s required arguments for training data specify that the SQL query must return columns named prompt and completion. Aliases can be used if the source columns have different names.
Option C is incorrect. FINETUNE is a SQL function invoked with the string ‘CREATE’ as its first argument, e.g., SELECT SNOWFLAKE-CORTEX. FINETUNE( ‘ CREATE’,…). It is not a DDL CREATE SNOWFLAKE .ML. FINETUNE statement, unlike ANOMALY DETECTION models which are created as objects using CREATE SNOWFLAKE .ML.ANOMALY DETECTION
Option D is correct. Structured outputs from the AI COMPLETE function, by specifying a JSON schema with the response_format argument, can be used to generate high-quality, schema-conforming data. This is an effective way to prepare the prompt and completion
columns needed for fine-tuning, especially when specific output formats (like JSON) are desired.
Option E is incorrect. While Cortex Fine-tuned LLMs do appear in the Model Registry UI, they are explicitly stated as not being managed by the Model Registry API directly. Models that contain user code, such as those developed with Snowpark ML modeling classes, are managed by the Model Registry API.
A team is developing a Retrieval Augmented Generation (RAG) pipeline in Snowflake, where document chunks are embedded using
Cortex AI functions and then retrieved using
VECTOR_COSINE_SIMILARITY
They are planning their infrastructure and cost management strategy.
Which of the following statements correctly describes the cost or performance characteristics of these operations in Snowflake? (Select all that apply)

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B,E
Explanation:
Option A is incorrect because vector similarity functions, including

incur token-based costs.
Option B is correct. Snowflake recommends executing queries that call Cortex AI SQL functions, which includes vector
similarity functions, with a smaller warehouse (no larger than MEDIUM) because larger warehouses do not increase performance for these functions.
Option C is incorrect. While cross-region inference involves data movement, the documentation states that user inputs, service generated prompts, and outputs are not stored or cached during cross-region inference. The cost is based on tokens or pages processed, and there’s no mention of additional explicit data transfer charges for the function call itself for cross-region inference, only latency considerations.
Option D is incorrect. Vector similarity functions do not incur token-based costs.
Option E is correct. For

A Snowflake administrator is tasked with ensuring that a specific data science team can only use approved LLMs (mistral-7b, llama3.1-8b) for generative AI tasks within a particular schema, and also needs to enable the use of an LLM in a non-native region due to specific project requirements.
Which combination of configurations would meet these requirements?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A,B
Explanation:

A software development team is building a conversational AI application within Snowflake, aiming to provide a dynamic and stateful chat experience for users. The application needs to handle follow-up questions while maintaining context, provide responses with a degree of creative variation, and actively filter out any potentially harmful content. The team utilizes the SNOWFLAKE. CORTEX. COMPLETE (or AI_COMPLETE) function.
A)

B)

C)

D)

E)

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B
Explanation:
The scenario requires statefulness (multi-turn conversation), creative variation in responses, and safety (filtering harmful content).
Option B correctly demonstrates a multi-turn conversation by passing a history of user and assistant messages in the prompt array. It uses a of which allows for creative variation in the output, as higher temperatures result in more diverse output. It also sets guardrails temperature 0.8, to enable content filtering.
Option A’s prompt is single-turn, not multi-turn.
Option C uses a single-turn prompt and disables guardrails. to TRUE Option D uses a of which produces deterministic results and lacks creative variation.
Option E has an incorrect conversation temperature 0.0, history structure with two consecutive ‘user’ roles without an ‘assistant’ response in between, which is not supported for stateful conversations.
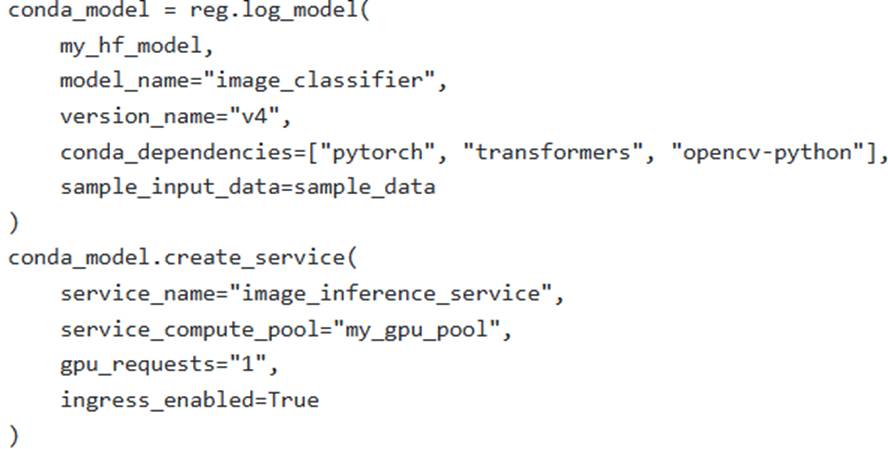
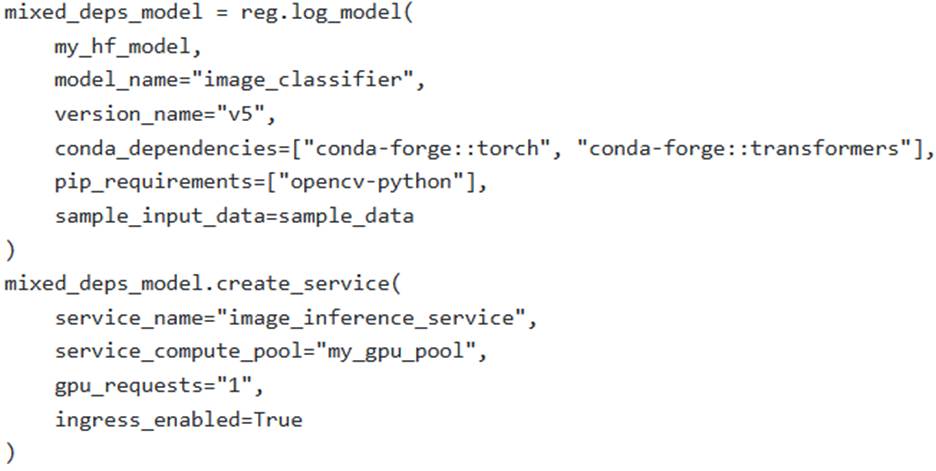
An ML engineer is deploying a custom PyTorch-based image classification model, obtained from Hugging Face, to Snowpark Container Services (SPCS). The deployment requires GPU acceleration on a compute pool named ‘my_gpu_pool’ and specific Python packages (‘torch’, ‘transformers’, ‘opencv-python’). The scenario dictates that ‘opencv-python’ is only available via PyPl, while ‘torch’ and ‘transformers’ can be sourced from either conda-forge or PyPl. The engineer uses the Snowflake Model Registry to log the model.
Which of the following and configurations correctly specify the necessary Python dependencies and GPU utilization for this inference service, adhering to Snowflake’s recommendations?
A)

B)

C)

D)
E)
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A
Explanation:
Option A is correct. The ‘pip_requirementS argument can be used to specify all necessary Python packages, including ‘torch ‘transformers’, and ‘opencv-python’, which are commonly available on PyPl. The ‘create_service’ call correctly specifies and to leverage GPU acceleration. This approach aligns with the Snowflake recommendation to use either ‘conda_dependencieS or ‘pip_requirementS, but not both, for dependency management.
Option B is incorrect because ‘opencv-python’ is specified as only available via PyPl in the scenario, meaning it cannot be installed via ‘conda-forge’.
Option C is incorrect because is chosen, which will not provide GPU acceleration required by the model.
Option D is incorrect because ‘opencv-python’ is not available through Anaconda channels (as per the scenario that it is PyPl only), and for other conda packages, explicitly specifying the ‘conda-forge’ channel (e.g., is the recommended practice for SPCS dependencies if they are not in the Snowflake Anaconda channel.
Option E is incorrect because, while it correctly separates conda and pip dependencies, Snowflake explicitly recommends ‘using only ‘conda_dependencieS or only ‘pip_requirementss, not both’ for managing dependencies to avoid potential conflicts.
A developer is instrumenting a RAG application using the TruLens SDK within Snowflake AI Observability. The application has distinct functions for retrieving context and generating a completion. To ensure clear tracing and readability, which span_type should ideally be used for the function responsible for retrieving relevant text from the vector store?
- A .
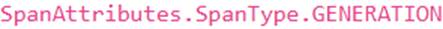
- B .

- C .

- D .

- E . No specific span_type is needed; the default instrumentation is sufficient for all functions.
C
Explanation:
The TruLens SDK allows for specifying span_type to improve the readability and understanding of traces. For a RAG application, RETRIEVAL the span type is explicitly recommended for search services or retrievers (functions that retrieve context). GENERATION is used for LLM inference calls that generate answers, and RECORD_ROOT identifies the entry point method of the application.
![]()
Which ‘combination of missing schema-level privileges’ is explicitly cited in the documentation as a direct cause for this error, assuming a unique model build name?
A)
![]()
B)
![]()
C)
![]()
D)
![]()
E)
![]()
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B
Explanation:
The troubleshooting documentation for the error message ‘Unable to create a build on the specified database and schema’ explicitly lists two primary causes related to missing schema-level privileges: ‘The ‘CREATE SNOWFLAKE.ML.DOCUMENT_INTELLIGENCE privilege is not granted to your role’ and ‘Your role has not been granted the ‘CREATE MODEL’ privilege on the schema that uses the model’. Both of these privileges are required on the schema to prepare a DocumentAI model build. Therefore, the combination of both missing would directly lead to this specific error.
Options C and D are individual components of the correct answer, but the question asks for the ‘combination of missing schema-level privileges’ as cited in the documentation.