
Practice Free GES-C01 Exam Online Questions
A data scientist is leveraging various Snowflake Cortex LLM functions to process extensive text data for an application. To effectively manage their budget, they need a clear understanding of how costs are incurred for each specific function.
Which of the following statements accurately describe how costs are calculated for Snowflake Cortex LLM functions, with a particular focus on token usage?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B,D
Explanation:
Option B is correct because for the ‘EXTRACT ANSWER function, the number of billable tokens is the sum of the tokens in the ‘from_text’ (source_document) and ‘question’ fields.
Option D is correct as for ‘CLASSIFY_TEXT (or ‘AI_CLASSIFY), labels, descriptions, and examples provided in the categories are counted as input tokens for each record processed, which directly increases the cost.
Option A is incorrect because and functions only count ‘input tokens’ towards the billable total, not both input and output tokens.
Option C is incorrect because Cortex COMPLETE Structured Outputs does not incur additional compute cost for the overhead of verifying tokens against the supplied JSON schema, although schema complexity can increase total token consumption.
Option E is incorrect because ‘AI_PARSE_DOCUMENT (and ‘SNOWFLAKE.CORTEX.PARSE_DOCUMENT) billing is based on the ‘number of document pages processed’ (e.g., 3.33 Credits per 1,000 pages for Layout mode), not just the number of documents.
A Gen AI Engineer is configuring a new semantic model for Cortex Analyst to process customer feedback. The goal is to ensure that when a user asks for sentiment analysis, the generated SQL queries always include an aggregation by a dimension and present the results as a percentage. The engineer plans to use custom instructions for this purpose.
Which of the following details about is true and crucial for successful implementation?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
C
Explanation:
Custom instructions in Cortex Analyst provide unique business context to the LLM to control SQL query generation. These instructions are provided in natural language within the semantic model YAML. This means the engineer should describe the desired behavior (grouping by ‘customer_segment’ and presenting as a percentage) in plain English for the LLM to interpret and apply, making option C correct.
Option A is incorrect because ‘custom_instructionS guide the LLM’s *generation* process, not directly inject SQL snippets.
Option B is incorrect as custom instructions are part of the YAML, not a separate Python file.
Option D is incorrect; while Copilot’s custom instructions have a 2,000 character limit, the source does not specify such a limit for Cortex Analyst’s semantic model ‘custom_instructionS, and the ‘task_description’ for ‘CLASSIFY _ TEXT is limited to about 50 words.
Option E is incorrect; the ‘custom_instructions’ in the semantic model are part of the shared model definition, not user-specific in the way Snowflake Copilot’s custom instructions are.
A financial data team is implementing a Snowflake Cortex AI solution to summarize regulatory documents using SNOWFLAKE.CORTEX.TRY_COMPLETE
They aim for both cost efficiency and high reliability, especially when dealing with documents that might occasionally exceed model context limits or result in malformed output.
Which of the following statements about the cost and operational behavior of TRY_COMPLETE
are TRUE in this context? (Select all that apply)

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A,B,E
Explanation:
Option A is correct because

option is used), the number of tokens processed (and billed) increases with schema complexity. Larger and more complex schemas generally consume a larger number of input and output tokens.
A data engineer is building a Snowflake data pipeline to ingest customer reviews from a raw staging table into a processed table. For each review, they need to determine the overall sentiment (positive, neutral, negative) and store this as a distinct column. The pipeline is implemented using SQL with streams and tasks to process new data.
Which Snowflake Cortex LLM function, when integrated into the SQL task, is best suited for this sentiment classification and ensures a structured, single-label output for each review?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B
Explanation:
To classify text into predefined categories, the function (or its updated version, is purpose-built and directly returns the classification label. This approach is more direct and efficient than using ‘SENTIMENT()’ which returns a score, which extracts an answer to a question, or multiple calls which return Boolean values. While could be prompted for classification, is a more specific task-specific function designed for this exact use case within Cortex LLM functions.
A data team is refining their Cortex Analyst semantic model to improve the accuracy of responses for specific, frequently asked questions and to enable better literal value searches. Consider a semantic model being developed to address these requirements.
Which two configurations or features are directly relevant and correctly applied in the semantic model YAML for these purposes?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A,B
Explanation:
Option A is correct. Cortex Search Services can be integrated into a dimension’s definition (using the field with ‘service’ and ‘literal_column’ fields) to improve literal matching by performing semantic search over the underlying column. This enhances Cortex Analyst’s ability to find literal values for filtering, helping with ‘fuzzy’ searches.
Option B is correct. The ‘verified_queries’ section allows pre- defining accurate SQL queries for specific natural language questions. Setting ‘use_as_onboarding_question true’ for entries in the VQR ensures these queries are used when relevant and presented as suggested questions to users.
Option C is incorrect; while metrics can reference logical columns, ‘relationships’ between logical tables are necessary for defining joins, especially across different underlying base tables.
Option D is incorrect; ‘custom_instructions’ are provided at the model level to give general context to the LLM for SQL query generation, not embedded within individual dimension definitions.
Option E is incorrect; the ‘sample_valueS field is recommended for dimensions with relatively low-cardinality (approximately 1-10 distinct values) to aid in semantic search for literals, not for high-cardinality dimensions.

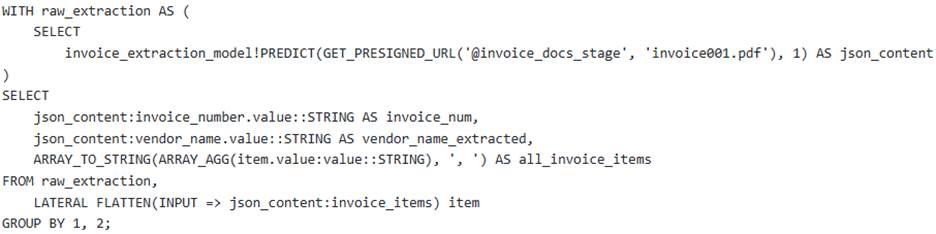
Which of the following SQL snippets, when executed against a single invoice file like "invoice001 .pdf", correctly extracts and transforms the desired data, assuming ‘json_content’ holds the raw Document AI output?
A)

B)
C)

D)

E)
![]()
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B
Explanation:
Option B correctly uses a Common Table Expression (CTE) to retrieve the raw JSON output from (which is a Document AI method for extracting information from documents in a stage), leveraging to access the document. It then accesses the ‘invoice_number’ and ‘vendor_name’ using .value’ syntax, appropriate for values returned as an array containing a single object with a ‘value’ field, as shown in Document AI output examples. The ‘LATERAL FLATTEN’ clause is correctly applied to expand the array of line items, and ‘ARRAY_AGG’ combined with ‘ARRAY _ TO STRING’ converts these items into a comma-separated string. Finally, it groups by the single-value extracted fields.
Option A attempts to flatten the result multiple times or in an incorrect way within the SELECT statement without a proper FROM’ clause for the flattened data, leading to inefficient or incorrect aggregation.
Option C directly references a staged file path (@invoice_docs_stage/invoice001.pdf) without the necessary GET PRESIGNED URL’ function, which is required when calling ‘!PREDICT’ with a file from a stage. It also incorrectly assumes direct .value’ access for array-wrapped single values and does not correctly transform the ‘invoice_itemS array into a string.
Option D’s subquery for ‘ARRAY AGG’ is syntactically problematic for direct column access from the outer query without explicit ‘LATERAL FLATTEN’ at the top level.
Option E only extracts the ‘ocrScore’ from the document metadata and does not perform the requested data transformations.
A data scientist needs to generate vector embeddings for product descriptions stored in a column ‘PRODUCT_DESCRIPTION’ in the ‘PRODUCT_CATALOG’ table. They want to use the ‘e5-base-v2 model for this task.
Which of the following SQL statements correctly applies the ‘SNOWFLAKE.CORTEX.EMBED TEXT 768′ function and accurately describes the expected data type of the resulting embedding?
- A . The query
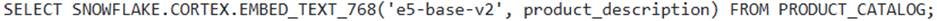
returns a VARIANT containing the embedding array. - B . The query
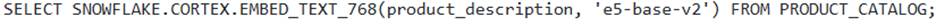
returns a JSON object with embedding details and a confidence score. - C . The query
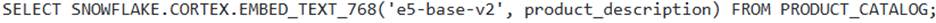
returns a VECTOR(FLOAT, 768) data type. - D . The query
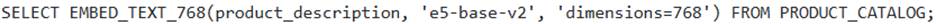
returns a STRING representation of the vector. - E . The query
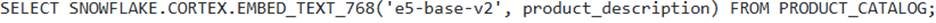
returns a BINARY data type for the embedding, requiring explicit conversion for use.
C
Explanation:
Option C is correct. The ‘SNOWFLAKE.CORTEX.EMBED_TEXT 768’ function takes the model name as the first argument and the text to be embedded as the second argument. The ‘e5-base-v2 model is a 768-dimension embedding model, and the function correctly returns a ‘VECTOR(FLOAT, 768)’ data type.
Options A, B, D, and E incorrectly describe the function’s arguments or the return data type.
A data scientist is tasked with improving the accuracy of an LLM-powered chatbot that answers user questions based on internal company documents stored in Snowflake. They decide to implement a Retrieval Augmented Generation (RAG) architecture using Snowflake Cortex Search.
Which of the following statements correctly describe the features and considerations when leveraging Snowflake Cortex Search for this RAG application?
- A . Cortex Search automatically handles text chunking and embedding generation for the source data, eliminating the need for manual ETL processes for these steps.
- B . To create a Cortex Search Service, one must explicitly specify an embedding model and manually manage its underlying infrastructure, similar to deploying a custom model via Snowpark Container Services.
- C . For optimal search results with Cortex Search, source text should be pre-split into chunks of no more than 512 tokens, even when using models with larger context windows like

- D . The
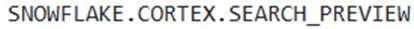
function can be used to test the search service with a query and optional filters before integrating it into a full application, for example:

- E . Enabling change tracking on the source table for the Cortex Search Service is optional; the service will still refresh automatically even if change tracking is disabled.
A,C,D
Explanation:
Option A is correct because Cortex Search is a fully managed service that gets users started with a hybrid (vector and keyword) search engine on text data in minutes, without needing to worry about embedding, infrastructure maintenance, or index refreshes.
Option B is incorrect because Cortex Search is a fully managed service; users do not need to manually manage the embedding model infrastructure. A default embedding model is used if not specified.
Option C is correct because, for best search results with Cortex Search, Snowflake recommends splitting text into chunks of no more than 512 tokens, as smaller chunks typically lead to higher retrieval and downstream LLM response quality, even with models that have larger context windows.
Option D is correct because the SNOWFLAKE.CORTEX.SEARCH_PREVIEW’ function allows users to test the search service to confirm it is populated with data and serving reasonable results for a given query.
Option E is incorrect because change tracking is required on the source table for the Cortex Search Service to function correctly and reflect updates to the base data.
A data engineer is designing an automated pipeline to process customer feedback comments from a ‘new_customer_reviews’ table, which includes a ‘review_text’ column. The pipeline needs to classify each comment into one of three predefined categories: ‘positive’, ‘negative’, or ‘neutral’, and store the classification label in a new ‘sentiment_label’ column.
Which of the following statements correctly describe aspects of implementing this data transformation using ‘SNOWFLAKE.CORTEX.CLASSIFY_TEXT’ in a Snowflake pipeline?
- A . The classification can be achieved by integrating a ‘SELECT statement with
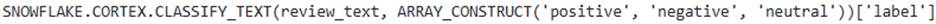
into an ‘INSERT or ‘UPDATE task. - B . Including an optional ‘task_description’ such as

can improve the accuracy of classification, especially if the relationship between text and categories is ambiguous. - C . The cost for ‘CLASSIFY _ TEXT is incurred based on the number of pages processed in the input document.
- D . The argument must contain exactly three unique categories for sentiment classification.
- E . Both the input string to classify and the are case-sensitive, potentially yielding different results for variations in capitalization.
A,B,E
Explanation:
Option A is correct. ‘SNOWFLAKE.CORTEX.CLASSIFY_TEXT classifies free-form text into categories and returns an ‘OBJECT’ value (VARIANT) where the ‘label’ field specifies the category. This can be extracted using ‘[‘labeI’]’ and seamlessly integrated into ‘INSERT or ‘UPDATE’ statements within a pipeline task for data transformation.
Option B is correct. Adding a clear ‘task_description’ to the ‘options’ argument for ‘CLASSIFY_TEXT’ can significantly improve classification accuracy. This is particularly useful when the relationship between the input text and the provided categories is ambiguous or nuanced.
Option C is incorrect. incurs compute cost based on the number of tokens processed (both input and output tokens), not on the number of pages in a document. Functions like ‘AI_PARSE_DOCUMENT bill based on pages.
Option D is incorrect. The argument for ‘CLASSIFY_TEXT’ must contain at least two and at most 100 unique categories. It is not strictly limited to three for any classification task, including sentiment.
Option E is correct. Both the ‘input’ string to classify and the are case-sensitive, meaning that differences in capitalization for either the input text or the category labels can lead to different classification results.
A data engineer is configuring a Document AI pipeline to process scanned PDF invoices stored in an internal stage named ‘invoice_docs_stage’. After uploading the PDF files, they execute an extracting query using ‘!PREDICT.
The query consistently returns the error:
![]()
Which of the following is the most likely cause of this error?
- A . The PDF documents exceed the maximum allowed file size of 50 MB.
- B . The internal stage was not created with ‘SNOWFLAKE_SSE’ encryption enabled.
- C . The Document AI model build is attempting to process more than 1000 documents in a single query.
- D . The ‘GET_PRESIGNED_URL’ function used in the ‘!PREDICT query has an expired URL.
- E . The documents contain non-English text, which is not fully supported by Document AI for optimal results.
B
Explanation:
The error message ‘File extension does not match actual mime type. Mime-Type: application/octet-stream’ is a specific error documented for DocumentAl when internal stages are not created with ‘SNOWFLAKE_SSE’ encryptiom For internal stages, Document AI requires server-side encryption to be enabled.
Options A, C, and D would typically result in different error messages or behaviors.
Option E refers to language support, which might impact accuracy but is not the cause of a file format identification error.