
Practice Free GES-C01 Exam Online Questions

A)
![]()
B)
![]()
C)
![]()
D)
![]()
E)
![]()
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
C
Explanation:

A Gen AI Specialist is tasked with preparing a Cortex Analyst semantic model to provide a predefined set of initial questions for new business users to explore their data. They want these specific questions to always be displayed, irrespective of what the user might initially type, as part of an onboarding experience.
Which of the following actions, or combinations of actions, must the Specialist take to successfully configure a semantic model to display a full set of predefined "onboarding questions" in Cortex Analyst?
- A . Define a Verified Query Repository (VQR) within the semantic model YAML file and include the specific questions as
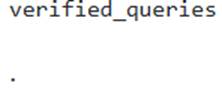
- B . For each desired onboarding question in the VQR, set the

- C . Ensure that the sql field for each onboarding question explicitly references physical column names from the underlying base tables, not logical column names.
- D . Limit the total number of onboarding questions to a maximum of five to ensure they are all displayed.
- E . Provide a detailed task_description in the semantic model for Cortex Analyst to generate these onboarding questions via LLMs.
A,B
Explanation:
To configure onboarding questions, a Verified Query Repository (VQR) must be defined in the semantic model, and the specific questions must be included as ‘verified_queries’. Therefore, option A is correct. For each desired question to function as an onboarding question, the flag must be set to ‘true’ within its VQR entry, which ensures these questions are returned regardless of user input similarity. This makes option B correct. Verified SQL queries in the VQR must use the names of logical tables and columns defined in the semantic model, not the underlying physical column names, so option C is incorrect. Cortex Analyst will return all questions marked as onboarding questions, even if there are more than five, if the feature is configured in Customizable Mode, making option D incorrect. The task_description’ is an optional argument in functions like ‘CLASSIFY_TEXT’ and is not used by Cortex Analyst to generate onboarding questions via LLMs; onboarding questions are drawn from the VQR.
A security architect is configuring access controls for a new custom role, ‘document_processor_role’, which will manage Document AI operations within a designated database ‘doc_processing_db’ and schema ‘doc_workflow_schema’. The goal is to grant only the minimum essential database-level role required to begin working with Document AI features.
A)
![]()
B)
![]()
C)
![]()
D)
![]()
E)
![]()
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
C
Explanation:
To work with Document AI, the database role must be granted to the account role. This role specifically enables creating Document AI model builds and working on document processing pipelines.
Option A grants a more general Cortex user role, which is not the specific foundational role for Document AI.
Option B grants access to all Cortex models, but not the foundational Document AI database role itself.
Options D and E grant schema-level or warehouse-level privileges, which are also necessary but are not the database-level ‘role’ specifically for DocumentAI capabilities.
An organization has implemented a strict governance policy where the ‘ACCOUNTADMIN’ has set the ‘CORTEX MODELS ALLOWLIST’ to only permit ‘gemma-7b’ and ‘llama3.1-8b’ models. A developer then executes the following SQL statements in a Snowflake worksheet using ‘TRY COMPLETE (SNOWFLAKE.CORTEX)". Assuming no specific RBAC model object grants are in place for the developer’s role, what would be the outcome of these queries? SELECT
![]()
- A . The first query will return a completion, the second will return ‘NULL’, and the third will return a completion.
- B . All three queries will return because ‘TRY COMPLETE’ will always prioritize strict adherence to the allowlist and any model not explicitly listed is considered unavailable.
- C . The first and third queries will return completions, but the second query will raise an error indicating an unauthorized model attempt.
- D . Only the first query will return a completion, as ‘gemma-7W is the smallest and most readily available model, while the others will return ‘NULL’.
- E . The first and second queries will return completions, while the third will return ‘NULL’ due to potential resource constraints for larger models.
A
Explanation:
The parameter restricts which models can be used with The ‘TRY_COMPLETE function executes the same operation as ‘COMPLETE’ but returns ‘NULL’ instead of raising an error when the operation cannot be performed. – The first query uses ‘gemma-7b’, which is in the Therefore, it will execute successfully and return a completion. – The second query uses ‘llama3.1-70b’, which is not in the configured ‘CORTEX_MODELS_ALLOWLIST’. As a result, ‘TRY COMPLETE will return ‘NULL’ because the model is not permitted by the allowlist. – The third query uses ‘llama3.1-8b’, which is also in the ‘CORTEX MODELS ALLOWLIST. Therefore, it will execute successfully and return a completion. Hence, option A accurately describes the outcome.
A data platform administrator needs to retrieve a consolidated overview of credit consumption for all Snowflake Cortex AI functions (e.g., LLM functions, Document AI, Cortex Search) across their entire account for the past week. They are interested in the aggregated daily credit usage rather than specific token counts per query.
Which Snowflake account usage views should the administrator primarily leverage to gather this information?
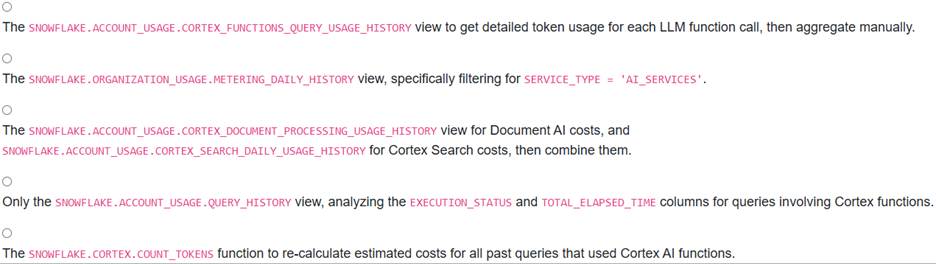
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B
Explanation:

A data application developer is building a Streamlit chat application within Snowflake. This application uses a RAG pattern to answer user questions about a knowledge base, leveraging a Cortex Search Service for retrieval and an LLM for generating responses. The developer wants to ensure responses are relevant, concise, and structured.
Which of the following practices are crucial when integrating Cortex Search with Snowflake Cortex LLM functions like AI_COMPLETE for this RAG chatbot?
- A . The
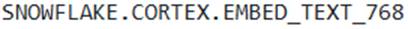
function should be used directly within the AI_COMPLETE call to dynamically generate embeddings for the user’s query and then perform a similarity search for context. - B . To maintain conversational context in a multi-turn chat, the developer should pass all previous user prompts and model responses in the prompt_or_history array to the AI_COMPLETE function for each turn.
- C . The retrieved context from Cortex Search should be directly concatenated with the user’s prompt as input to the AI_COMPLETE function without any specific formatting, as LLMs can inherently understand raw context.
- D . Using the response_format option within AI_COMPLETE or COMPLETE with a JSON schema is an effective way to enforce structured outputs from the LLM, reducing post-processing needs for downstream applications.
- E . For performance and cost optimization, it is always recommended to query Cortex Search and the LLM function within a single SELECT statement for all complex RAG flows, to minimize data movement across Snowflake’s compute layers.
B,D
Explanation:

A security-conscious data scientist in an Azure East US 2 (Virginia) account wants to fine-tune a mistral-7b model for a specific text summarization task and then deploy it for real-time inference using the Cortex REST API. The base model is natively mistral -7b available for fine-tuning in Azure East US 2 (Virginia). For subsequent inference using the fine-tuned model, they need to understand the regional and cross-region inference considerations.
Which of the following statements are correct?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A,B,D,E
Explanation:

A data scientist is tasked with improving the accuracy of an LLM-powered chatbot that answers user questions based on internal company documents stored in Snowflake. They decide to implement a Retrieval Augmented Generation (RAG) architecture using Snowflake Cortex Search.
Which of the following statements correctly describe the features and considerations when leveraging Snowflake Cortex Search for this RAG application?
- A . Cortex Search automatically handles text chunking and embedding generation for the source data, eliminating the need for manual ETL processes for these steps.
- B . To create a Cortex Search Service, one must explicitly specify an embedding model and manually manage its underlying infrastructure, similar to deploying a custom model via Snowpark Container Services.
- C . For optimal search results with Cortex Search, source text should be pre-split into chunks of no more than 512 tokens, even when using models with larger context windows like

- D . The SNOWFLAKE.CORTEX.SEARCH_PREVIEW function can be used to test the search service with a query and optional filters before integrating it into a full application, for example:

- E . Enabling change tracking on the source table for the Cortex Search Service is optional; the service will still refresh automatically even if change tracking is disabled.
A,C,D
Explanation:
Option A is correct because Cortex Search is a fully managed service that gets users started with a hybrid (vector and keyword) search engine on text data in minutes, without needing to worry about embedding, infrastructure maintenance, or index refreshes.
Option B is incorrect because Cortex Search is a fully managed service; users do not need to manually manage the embedding model infrastructure. A default embedding model is used if not specified.
Option C is correct because, for best search results with Cortex Search, Snowflake recommends splitting text into chunks of no more than 512 tokens, as smaller chunks typically lead to higher retrieval and downstream LLM response quality, even with models that have larger context windows.
Option D is correct because the ‘SNOWFLAKE.CORTEX.SEARCH_PREVIEW’ function allows users to test the search service to confirm it is populated with data and serving reasonable results for a given query.
Option E is incorrect because change tracking is required on the source table for the Cortex Search Service to function correctly and reflect updates to the base data.
An ML engineering team is preparing to log a custom Python model to the Snowflake Model Registry. This model has several Python package dependencies. The team wants to ensure the model can be deployed optimally, either in a Snowflake warehouse or to Snowpark Container Services (SPCS), depending on future needs. They are particularly concerned with how dependency specification impacts deployment eligibility.
Which statements accurately describe how Snowflake handles model dependencies and determines deployment eligibility for custom Python models logged in the Model Registry, particularly when considering both Snowflake warehouse and Snowpark Container Services (SPCS) environments? (Select all that apply.)
- A . If all of a model’s ‘conda_dependencieS are available in the Snowflake conda channel, the model is automatically deemed eligible to run in a warehouse.
- B . For models intended for SPCS, ‘pip_requirements’ are always preferred over ‘conda_dependencies’ because SPCS strictly prohibits the use of any conda packages from ‘conda-forge’
- C . When ‘conda_dependencies’ are specified for a model to be deployed to SPCS, these dependencies are by default obtained from ‘conda-forge’ rather than the Snowflake conda channel.
- D . The function will fail if ‘WAREHOUSE is specified in ‘target_platforms’ but the model’s size or GPU requirements make it ineligible for warehouse deployment.
- E . Specifying both ‘conda_dependencies’ and ‘pip_requirements’ for a model is recommended to cover all possible deployment scenarios, and Snowflake’s build process ensures compatibility between them.
A,C,D
Explanation:
Option A is correct. When a model version is logged using ‘reg.log_moder, its ‘conda_dependencies’ are validated against the Snowflake conda channel. If all dependencies are found there, the model is considered eligible to run in a warehouse.
Option B is incorrect. Snowpark Container Services models, by default, obtain their ‘conda_dependencieS from ‘conda-forge’. Therefore, SPCS does not prohibit conda packages from ‘conda-forge’.
Option C is correct. The Snowflake documentation explicitly states that for models running on Snowpark Container Services (SPCS), ‘conda-forge’ is the assumed channel for ‘conda_dependencies’, while the Snowflake conda channel is for warehouse deployments only.
Option D is correct. If the ‘WAREHOUSE platform is specified in the ‘target_platforms’ argument of, and the model is ineligible for warehouse deployment (e.g., due to its size, dependencies, or GPU requirements), the call will fail.
Option E is incorrect. Snowflake recommends using ‘either’ ‘conda_dependencieS ‘or’, but not both simultaneously. This is because combining both can lead to package conflicts, causing the container image to build successfully but potentially resulting in an unexpected or non-functional container image.
A developer is building a real-time chat application and wants to integrate a Large Language Model (LLM) hosted in Snowflake Cortex using its REST API. They need to send user prompts and receive streaming responses, ensuring secure authentication.
Which of the following statements about using the Cortex REST API for the COMPLETE function are correct?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A,B,D
Explanation:
