
Practice Free GES-C01 Exam Online Questions
A team is designing a complex Gen AI application in Snowflake, which includes components for training a custom LLM, running batch inference, and providing a real-time conversational interface. They plan to leverage Snowpark Container Services (SPCS) for these workloads.
Which of the following statements accurately describe the suitable SPCS service design models and important considerations for these different application components? (Select all that apply.)
- A . GPU-accelerated LLM training, which is a finite and often resource-intensive task, is best implemented as a ‘‘job’’ in SPCS, invoked via "EXECUTE JOB SERVICE’, as it is designed to run to completion and then spin down.
- B . Real-time LLM inference for a conversational interface is ideally deployed as a ‘ ‘Service’ ‘ in SPCS, which is long-running and accessible via an HTTP endpoint, ensuring continuous availability and responsiveness.
- C . For batch inference on Snowflake data where data locality and efficiency are key, using ‘‘Service Functions’’ is highly efficient because data is passed as input parameters directly from SQL queries, and this design ensures the data never leaves the Snowflake network boundary.
- D . When deploying LLMs to SPCS, it’s generally most cost-efficient to use generic CPU instance types like ‘CPU X64 XS’ for all tasks, as GPU instances (e.g., are exclusively for highly specialized computer vision tasks and not optimized for LLMs.
- E . Container images for SPCS deployments are typically pushed to a public Docker Hub repository, and Snowflake pulls them as needed during service creation and scaling, simplifying image management.
A,B,C
Explanation:
Options A, B, and C are correct descriptions of SPCS service design models and their applications.
Option A is correct: Jobs in SPCS are containerized tasks that execute and run to completion, making them ideal for finite operations like GPU-accelerated machine learning model training.
Option B is correct: Services are designed for long-running applications, offering continuous availability and accessibility via internal and external endpoints, which is suitable for real-time inference in conversational interfaces.
Option C is correct: Service Functions are callable computations that accept data as input, often from SQL queries. A key advantage is that data processing occurs within the Snowflake network boundary, making them efficient and secure for data-intensive tasks like batch inference.
Option D is incorrect: While is a cost- effective CPU instance, GPU instances like ‘GPU_NV_M’ are explicitly optimized for ‘intensive GPU usage scenarios like Computer Vision or LLMs/VLMs’. Therefore, using CPU-only instances for all LLM tasks, especially performance-critical ones, is not the general best practice.
Option E is incorrect: Container images for Snowpark Container Services are stored in Snowflake’s OCIv2 compliant Image Registry, not typically pulled directly from public Docker Hub repositories for deployment within Snowflake. The image registry has a unique hostname which allows OCI clients to access it via REST API calls, and images are pushed to image repositories within this registry.
A data engineer is tasked with establishing AI Observability for a generative AI application that integrates with external systems and will undergo continuous improvement. The goal is to compare different iterations of the application efficiently.
Which combination of configuration best practices, features, and governance aspects are most relevant for a robust setup of AI Observability within Snowflake for this scenario?
- A . Ensure the Python environment includes ‘trulens-core’, ‘trulens-connectors-snowflake’, and ‘trulens-providers-cortex’ (version 2.1.2 or later) and set the environment variable TRULENS_OTEL_TRACING to 1.
- B . For access control, the role used to create and execute runs must be granted the ‘SNOWFLAKE.CORTEX_USER database role and the ‘AI_OBSERVABILITY_EVENTS_LOOKUPS application role.
- C . To compare different LLMs or prompt configurations, rely on the AI Observability’s ‘Comparisons’ feature, which allows side-by-side analysis of evaluation metrics across multiple evaluations.
- D . If the AI Observability service is not natively available in the primary region, enable to ‘ ANY_REGION’ or a specific supported region to allow tracing and evaluation to proceed.
- E . Run the AI Observability project directly within a Snowflake Notebook to leverage its integrated environment for easier debugging and iteration.
A,B,C,D
Explanation:
Option A is correct because installing the specified TruLens Python packages (version 2.1.2 or later) and setting STRULENS OTEL TRACINGS to are prerequisites for instrumenting the application and enabling tracing for AI Observability.
Option B is correct because the ‘CORTEX_USER database role and application role are explicitly required for creating and executing runs for AI Observability.
Option C is correct as the ‘Comparisons’ feature is a core component of AI Observability, designed precisely for assessing and comparing application quality, accuracy, and performance across various LLMs, prompts, and configurations.
Option D is correct because AI Observability, like other Cortex LLM Functions, might require ‘CORTEX ENABLED_CROSS REGION’ to be configured if the service or specific LLMs are not natively available in the primary Snowflake region.
Option E is incorrect because the sources explicitly state that you cannot run your project using the TruLens SDK in a Snowflake Notebook for AI Observability.
A data analytics team aims to enhance their understanding of customer feedback stored in a Snowflake table called CUSTOMER_FEEDBACK. This table has a REVIEW_TEXT column containing raw customer comments and a CUSTOMER_SEGMENT column. The team wants to classify each review into predefined categories and then generate a concise summary of all reviews for each customer segment.
Which of the following Snowflake Cortex AI functions and approaches should they use?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A,C,E
Explanation:

A data engineer is designing an automated pipeline in Snowflake to process streaming customer support tickets using LLM functions. To ensure the pipeline is robust against unexpected LLM errors (e.g., due to malformed input or transient service issues), they decide to use SNOWFLAKE.CORTEX.TRY_COMPLETE instead of SNOWF LAKE.CORTEX.COMPLETE.
Which of the following is the most significant advantage of using TRY_COMPLETE in this scenario?
- A . It provides a built-in retry mechanism for LLM calls that encounter temporary failures, automatically re-submitting the prompt up to three times.
- B . It processes tokens at a significantly reduced rate compared to COMPLETE, leading to lower compute costs regardless of success or failure.
- C . It returns NULL when an LLM operation cannot be performed, allowing the pipeline to continue processing other data without raising an error that would halt the task.
- D . It automatically adjusts the LLM’s temperature and max_tokens parameters to prevent errors, optimizing for successful responses.
- E . It offers enhanced security features, such as automatic input sanitization, which are not available in the standard COMPLETE function.
C
Explanation:
Option C is correct because
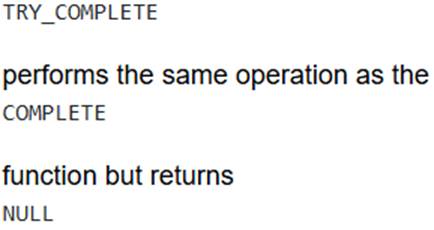
instead of raising an error when the operation cannot be performed. This feature is crucial for building robust data pipelines, as it allows the pipeline to gracefully handle individual LLM call failures and continue processing other records, preventing the entire task from halting.
Option A is incorrect; the sources do not mention an automatic retry mechanism for

A Gen AI Specialist is leveraging Snowflake Document AI to extract specific entities and table data from a large and varied collection of documents. They are aware of potential limitations and want to understand the expected outcomes when processing different types of files.
Considering a scenario where a Document AI model build is used with the ‘!PREDICT’ method, which of the following statements accurately describe the expected behavior or potential issues based on Document AI’s conditions and limitations?
- A . Processing a legal contract document that is 130 pages long will likely result in a ‘_processingErrors’ message indicating that the document has too many pages.
- B . If a question for an entity, like ‘total_invoice_amount’, does not find a corresponding value in a document, the JSON output for will contain a ‘value’ key with a ‘null’ string and a ‘score’ key indicating the model’s confidence in the absence of the answer.
- C . A document written entirely in Ukrainian will be processed by Document AI, and the extracted information will be of satisfactory quality due to extensive multilingual support.
- D . In a table extraction task, if a specific cell (e.g., ‘tablellitem’) is empty, the resulting JSON will omit the ‘value’ key for that cell, but will still provide a ‘score’ indicating the model’s confidence that the cell is empty.
- E . If the extracted answer to a question for a single entity (e.g., is very long, it will be automatically truncated to a maximum of 2048 tokens.
A,D
Explanation:
Option A is correct. Document AI documents must be no more than 125 pages long. A 130-page document would exceed this limit, leading to an error such as ‘Document has too many pages. Actual: 150. Maximum: 125.’.
Option B is incorrect. If the Document AI model does not find an answer in the document, the model does not return a ‘value’ key. It only retums the ‘score’ key, which indicates how confident the model is that the document does not contain the answer.
Option C is incorrect. Document AI supports processing documents in English, Spanish, French, German, Portuguese, Italian, and Polish, but notes that results for other languages might not be satisfactory. Ukrainian is not listed among the supported languages.
Option D is correct. The sources state that in table extraction, if a cell is empty, the Document AI model does not return a ‘value’ key but does return the ‘score’ key, which indicates how confident the model is that the cell is empty. This is illustrated in the example output for ‘tablel Itak and ‘table21date’ .
Option E is incorrect. For general entity extraction, the Document AI model returns answers that are up to 512 tokens long (about 320 words) per question. The 2048-token limit applies specifically to answers from the model for table extraction.
A security administrator is implementing strict model access controls for Snowflake Cortex LLM functions, including those accessed via the Cortex REST API. By default, the ‘SNOWFLAKE.CORTEX USER’ database role is granted to the ‘PUBLIC’ role, allowing all users to call Cortex AI functions. To enforce a more restrictive access policy, the administrator revokes ‘SNOWFLAKE.CORTEX USER from ‘PUBLIC’.
Which of the following actions must the administrator take to ensure specific roles can ‘still’ make Cortex REST API requests, and what are the implications?
- A . The ‘SNOWFLAKE.CORTEX USER database role must be granted directly to individual users who need access, as it cannot be granted to other account roles.
- B . The ‘SNOWFLAKE.CORTEX USER database role must be granted to the specific account roles, and then these account roles must be granted to users. Additionally, the account parameter can be used to restrict which models are accessible.
- C . Access for Cortex REST API is managed independently of database roles; a separate REST API key must be provisioned for each user or application.
- D . Only the role can make cortex REST API calls after revoking ‘SNOWFLAKE.CORTEX_USER from ‘PUBLIC’, as this role inherently bypasses all other access controls.
- E . The from ‘SNOWFLAKE.CORTEX USER database role is only required for SQL functions, not for the Cortex REST API, so no further action is needed after revoking ‘PUBLIC for REST API access.
B
Explanation:
To send a REST API request to Cortex, the default role of the calling user must be granted the ‘SNOWFLAKE.CORTEX_USER database role. By default, this role is granted to ‘PUBLIC’, but it can be revoked. If revoked, the ‘CORTEX USER role must be explicitly granted to other account roles, which are then granted to users. The ‘CORTEX_USER role cannot be granted directly to a user. The ‘CORTEX MODELS_ALLOWLIST’ parameter can also be used to restrict which models are accessible at the account level for Cortex functions, including those accessed via the REST API. Therefore, option B correctly outlines the required actions and an additional control.
Options A, C, D, and E are incorrect as they misrepresent the access control mechanisms or requirements for Cortex REST API.
A development team is building an AI-powered data pipeline in Snowflake. The pipeline involves extracting text from documents, generating embeddings using
![]()
,and then performing similarity searches using
![]()
to find related documents. They plan to manage this pipeline using Snowflake tasks and want to integrate with a Python application for some custom processing.
Considering this scenario, which of the following statements about implementing this pipeline are true?
- A . To generate document embeddings, the EMBED_TEXT_768 function must be called within a Snowpark-optimized warehouse to achieve optimal performance, especially for large datasets.
- B . If the team wants to use the Snowpark Python library to call
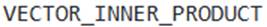
they can seamlessly do so, as it fully supports all vector similarity functions. - C . Snowflake VECTOR data type columns can be used directly as clustering keys to optimize queries that involve range-based searches on vector values.
- D .
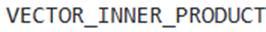
and other vector similarity functions can be effectively used in SQL queries with ORDER BY and LIMIT clauses to retrieve the most similar documents, after creating embeddings. - E . When using Snowflake tasks to automate the embedding generation and similarity search, VECTOR data type columns are compatible with streams and dynamic tables for incremental processing.
D
Explanation:
Option A is incorrect. Snowflake recommends executing queries that call Cortex AI SQL functions like EMBED_TEXT_768 with a smaller warehouse (no larger than MEDIUM), as larger warehouses do not increase performance. Snowpark-optimized warehouses are recommended for workloads with large memory requirements or specific CPU architectures, typically for ML training, not for general Cortex AI function calls.
Option B is incorrect. The Snowpark Python library explicitly states that it does not support the VECTOR_COSINE_SIMILARITY
function, meaning it does not ‘fully support all vector similarity functions’.
Option C is incorrect. The VECTOR data type is not supported as clustering keys.
Option D is correct. After generating embeddings (e.g., storing them in a VECTOR column like issue vec), vector similarity functions can be effectively used in SQL queries with ORDER BY and LIMIT clauses to retrieve the most similar results, as demonstrated with VECTOR_COSINE_SIMILARITY in a RAG example. This pattem applies to VECTOR_INNER_PRODUCT as well.
Option E is incorrect. The VECTOR data type is not supported for use with dynamic tables. Additionally, Snowflake Cortex functions (including EMBED_TEXT_768) do not support dynamic tables.
A development team is constructing a Gen AI application using Snowflake Cortex LLM functions, particularly for conversational and text generation tasks. They are concerned about potential high costs due to token consumption.
Which of the following strategies would most effectively help minimize token usage and optimize costs when working with these Cortex LLM functions?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B,C,E
Explanation:
Option B is correct because while schema validation itself doesn’t incur extra cost, a large or complex schema can increase token consumptiom Providing precise and concise descriptions for schema fields helps the LLM understand and adhere to the desired format more efficiently, potentially reducing the overall tokens consumed for accurate responses.
Option C is correct as the ‘COUNT_TOKENS function allows developers to determine the token count of an input prompt for a specific model, enabling them to pre-emptively avoid exceeding the model’s context window, thus preventing errors and wasted compute from re-runs.
Option E is correct because for multi-turn conversations in Cortex Analyst, a summarization agent is specifically used to rephrase follow-up questions by incorporating previous context, without passing the entire, potentially long, conversation history. This significantly reduces the ‘prompt_tokens’ sent to the main LLM for each turn and optimizes inference times.
Option A is incorrect because ‘COMPLETE (and ‘TRY_COMPLETE’) functions are stateless; to maintain conversational context, all previous user prompts and model responses must be included in the array, which increases token count proportionally. Simply sending the latest prompt would lose context.
Option D is incorrect as setting a higher ‘temperature’ value (e.g., 0.7) increases the ‘randomness and diversity’ of the LLM’s output, not necessarily its conciseness for cost optimization. For the most consistent (and often direct) results, a ‘temperature of 0 is recommended.
A Gen AI developer is deploying a customer support chatbot using ‘SNOWFLAKE.CORTEX.COMPLETE for generating responses. To ensure the chatbot does not provide inappropriate or harmful content, they have enabled Cortex Guard. A specific user prompt is now causing the LLM to attempt generating content that violates the defined safety policies.
What is the expected outcome of the ‘COMPLETE’ function call in this scenario, and how is it typically communicated to the application?
- A . The ‘COMPLETE function will raise a SQL exception, indicating a ‘PROHIBITED_CONTENT error, which the calling application must handle with a ‘TRY…CATCH’ block.
- B . The ‘COMPLETE function will return a generic, pre-defined filtered message, such as ‘Response filtered by Cortex Guard’, in place of the harmful content.
- C . The LLM, through Cortex Guard’s internal mechanisms, will automatically rephrase or redact the harmful parts of its response to comply with safety guidelines before returning it.
- D . The Snowflake account will be temporarily locked for violating the acceptable use policy, and all subsequent LLM calls will fail until manual intervention.
- E . The ‘COMPLETE function will return a NULL value in the response, signifying that no safe response could be generated, similar to error handling.
B
Explanation:
When Cortex Guard is enabled (‘guardrails: true) for ‘SNOWFLAKE.CORTEX.COMPLETE’ or via the Cortex LLM REST API, and the LLM generates potentially unsafe or harmful content, Cortex Guard filters this content and returns a generic filtered message, typically ‘Response filtered by Cortex Guard’. It does not raise a SQL exception (Option A) or automatically rephrase the content (Option C). Account locking (Option D) is not the immediate and direct outcome of a single filtered response. While ‘TRY_COMPLETE returns NULL for execution errors, Cortex Guard’s filtering mechanism returns a specific message within the normal function output flow, not a NULL, for detected harmful content.
A data scientist, ‘Dl DEV’, has been granted the
![]()

Despite these grants, ‘DI_DEV’ still receives a ‘permission denied’ error when attempting to ‘‘prepare’’ the Document AI model build in Snowsight.
Which ‘single missing privilege’ is the most likely direct cause of this specific error for Document AI model build preparation?
A)
![]()
B)
![]()
C)
![]()
D)
![]()
E)
![]()
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
C
Explanation:
