
Practice Free DP-100 Exam Online Questions
You use the Two-Class Neural Network module in Azure Machine Learning Studio to build a binary classification model. You use the Tune Model Hyperparameters module to tune accuracy for the model.
You need to select the hyperparameters that should be tuned using the Tune Model Hyperparameters module.
Which two hyperparameters should you use? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Number of hidden nodes
- B . Learning Rate
- C . The type of the normalizer
- D . Number of learning iterations
- E . Hidden layer specification
DRAG DROP
You need to produce a visualization for the diagnostic test evaluation according to the data visualization requirements.
Which three modules should you recommend be used in sequence? To answer, move the appropriate modules from the list of modules to the answer area and arrange them in the correct order.


HOTSPOT
You are developing a deep learning model by using TensorFlow. You plan to run the model training workload on an Azure Machine Learning Compute Instance.
You must use CUDA-based model training.
You need to provision the Compute Instance.
Which two virtual machines sizes can you use? To answer, select the appropriate virtual machine sizes in the answer area. NOTE: Each correct selection is worth one point.
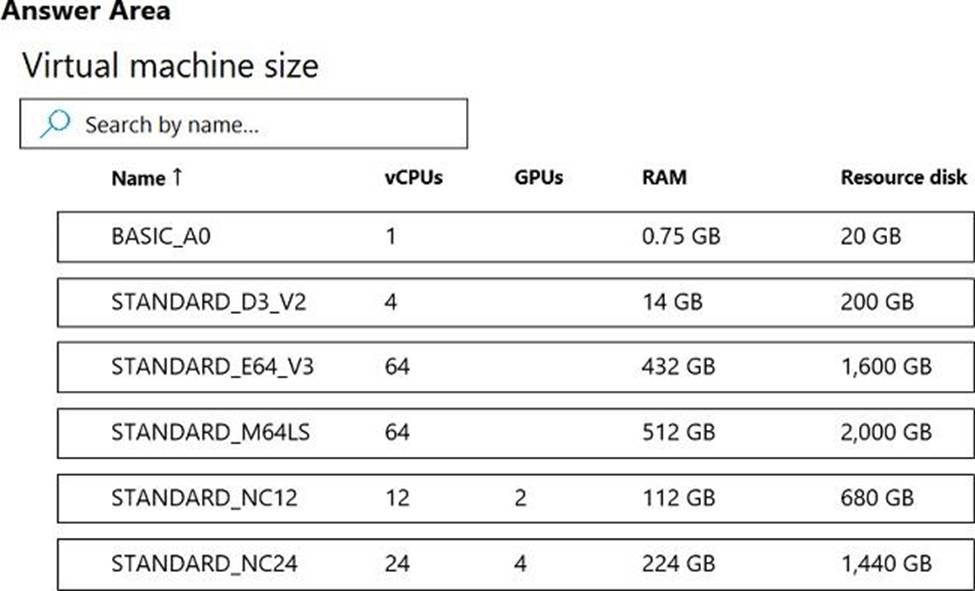
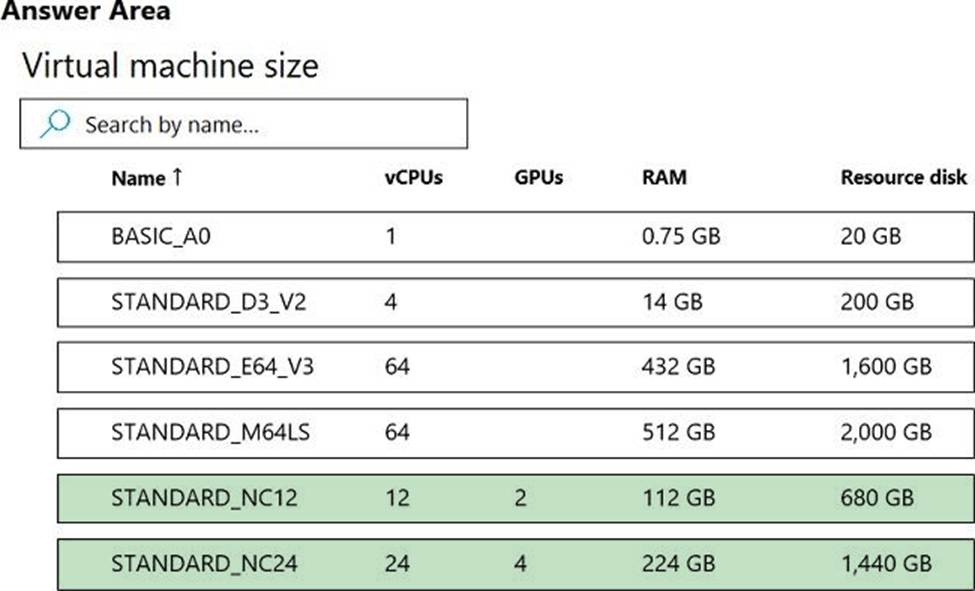
HOTSPOT
You are a lead data scientist for a project that tracks the health and migration of birds. You create a multi-image classification deep learning model that uses a set of labeled bird photos collected by experts. You plan to use the model to develop a cross-platform mobile app that predicts the species of bird captured by app users.
You must test and deploy the trained model as a web service.
The deployed model must meet the following requirements:
✑ An authenticated connection must not be required for testing.
✑ The deployed model must perform with low latency during inferencing.
✑ The REST endpoints must be scalable and should have a capacity to handle large number of requests when multiple end users are using the mobile application.
You need to verify that the web service returns predictions in the expected JSON format when a valid REST request is submitted.
Which compute resources should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


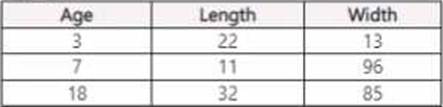
You use Azure Machine Learning Designer to load the following datasets into an experiment:
Dataset1
Dataset2
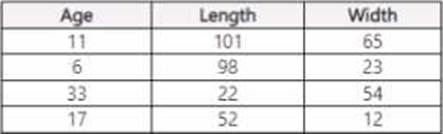
You use Azure Machine Learning Designer to load the following datasets into an experiment:
You need to create a dataset that has the same columns and header row as the input datasets and contains all rows from both input datasets.
Solution: Use the Join Data component.
Does the solution meet the goal?
- A . Yes
- B . No
Your team is building a data engineering and data science development environment.
The environment must support the following requirements:
✑ support Python and Scala
✑ compose data storage, movement, and processing services into automated data pipelines
✑ the same tool should be used for the orchestration of both data engineering and data science
✑ support workload isolation and interactive workloads
✑ enable scaling across a cluster of machines
You need to create the environment.
What should you do?
- A . Build the environment in Apache Hive for HDInsight and use Azure Data Factory for orchestration.
- B . Build the environment in Azure Databricks and use Azure Data Factory for orchestration.
- C . Build the environment in Apache Spark for HDInsight and use Azure Container Instances for orchestration.
- D . Build the environment in Azure Databricks and use Azure Container Instances for orchestration.
You have a Python script that executes a pipeline.
The script includes the following code:
from azureml.core import Experiment
pipeline_run = Experiment(ws, ‘pipeline_test’).submit(pipeline)
You want to test the pipeline before deploying the script.
You need to display the pipeline run details written to the STDOUT output when the pipeline completes.
Which code segment should you add to the test script?
- A . pipeline_run.get.metrics()
- B . pipeline_run.wait_for_completion(show_output=True)
- C . pipeline_param = PipelineParameter(name="stdout", default_value="console")
- D . pipeline_run.get_status()
HOTSPOT
You use an Azure Machine Learning workspace. Azure Data Factor/ pipeline, and a dataset monitor that runs en a schedule to detect data drift.
You need to Implement an automated workflow to trigger when the dataset monitor detects data drift and launch the Azure Data Factory pipeline to update the dataset. The solution must minimize the effort to configure the workflow.
How should you configure the workflow? To answer select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You have an Azure Machine Learning workspace. You connect to a terminal session from the
Notebooks page in Azure Machine Learning studio. You plan to add a new Jupyter kernel that will be
accessible from the same terminal session. You need to perform the task that must be completed
before you can add the new kernel.
Solution: Create a compute instance.
Does the solution meet the goal?
- A . Yes
- B . No
You use differential privacy to ensure your reports are private. The calculated value of the epsilon for your data is 1.8. You need to modify your data to ensure your reports are private.
Which epsilon value should you accept for your data?
- A . between 0 and 1
- B . between 2 and 3
- C . between 3 and 10
- D . more than 10