Practice Free DP-100 Exam Online Questions
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using Azure Machine Learning to run an experiment that trains a classification model.
You want to use Hyperdrive to find parameters that optimize the AUC metric for the model.
You configure a HyperDriveConfig for the experiment by running the following code:

You plan to use this configuration to run a script that trains a random forest model and then tests it with validation data. The label values for the validation data are stored in a variable named y_test variable, and the predicted probabilities from the model are stored in a variable named y_predicted.
Solution: Run the following code:

Does the solution meet the goal?
- A . Yes
- B . No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using Azure Machine Learning to run an experiment that trains a classification model.
You want to use Hyperdrive to find parameters that optimize the AUC metric for the model.
You configure a HyperDriveConfig for the experiment by running the following code:
You plan to use this configuration to run a script that trains a random forest model and then tests it with validation data. The label values for the validation data are stored in a variable named y_test variable, and the predicted probabilities from the model are stored in a variable named y_predicted.
Solution: Run the following code:
Does the solution meet the goal?
- A . Yes
- B . No
You are creating a machine learning model. You have a dataset that contains null rows.
You need to use the Clean Missing Data module in Azure Machine Learning Studio to identify and resolve the null and missing data in the dataset.
Which parameter should you use?
- A . Replace with mean
- B . Remove entire column
- C . Remove entire row
- D . Hot Deck
You manage an Azure Machine Learning workspace.
You experiment with an MLflow model that trains interactively by using a notebook in the workspace. You need to log dictionary type artifacts of the experiments in Azure Machine Learning by using MLflow.
Which syntax should you use?
- A . mlflow.log_artifact(my_dict)
- B . mlflow.log_metric("my_metric", my_dict)
- C . mlflow.log_artifacts(my_dict>
- D . mlflow.log metrics(my diet)
HOTSPOT
You are using the Azure Machine Learning Service to automate hyperparameter exploration of your neural network classification model.
You must define the hyperparameter space to automatically tune hyperparameters using random sampling according to following requirements:
The learning rate must be selected from a normal distribution with a mean value of 10 and a standard deviation of 3.
Batch size must be 16, 32 and 64.
Keep probability must be a value selected from a uniform distribution between the range of 0.05 and 0.1.
You need to use the param_sampling method of the Python API for the Azure Machine Learning Service.
How should you complete the code segment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


2.1.0
You run the following code:
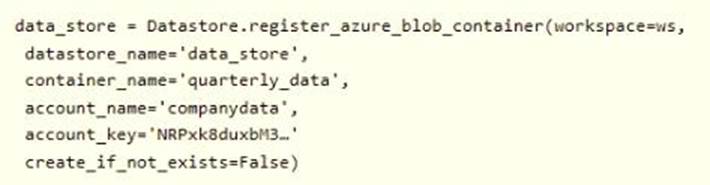
You need to create a dataset named training_data and load the data from all files into a single data
frame by using the following code:
![]()
Solution: Run the following code:

Does the solution meet the goal?
- A . Yes
- B . No
You need to select a feature extraction method.
Which method should you use?
- A . Mutual information
- B . Mood’s median test
- C . Kendall correlation
- D . Permutation Feature Importance
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Machine Learning workspace. You connect to a terminal session from the Notebooks page in Azure Machine Learning studio.
You plan to add a new Jupyter kernel that will be accessible from the same terminal session.
You need to perform the task that must be completed before you can add the new kernel.
Solution: Delete the Python 3.6 – AzureML kernel.
Does the solution meet the goal?
- A . Yes
- B . No
DRAG DROP
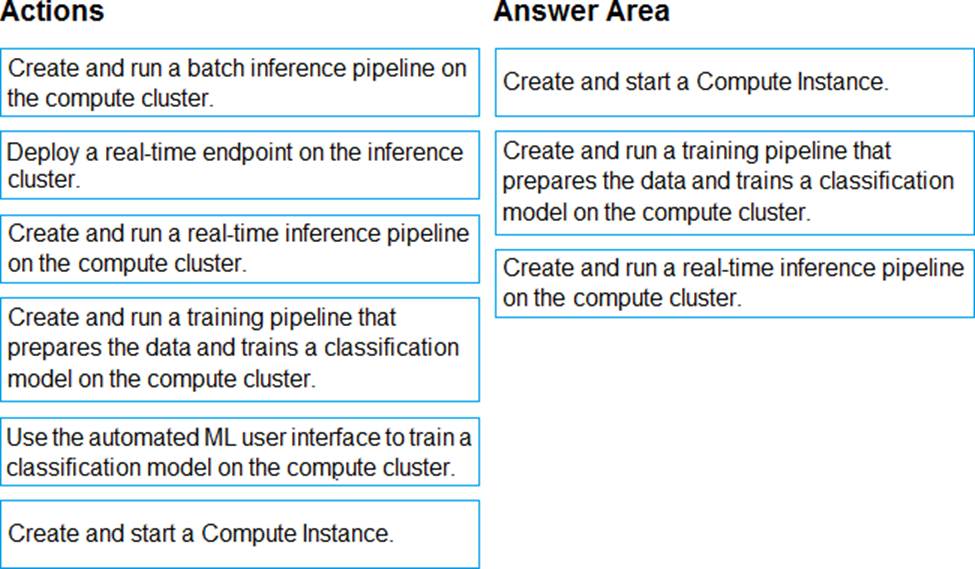
You have an Azure Machine Learning workspace that contains a CPU-based compute cluster and an Azure Kubernetes Services (AKS) inference cluster. You create a tabular dataset containing data that you plan to use to create a classification model.
You need to use the Azure Machine Learning designer to create a web service through which client applications can consume the classification model by submitting new data and getting an immediate prediction as a response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

HOTSPOT
You manage an Azure Machine Learning workspace named workspace1.
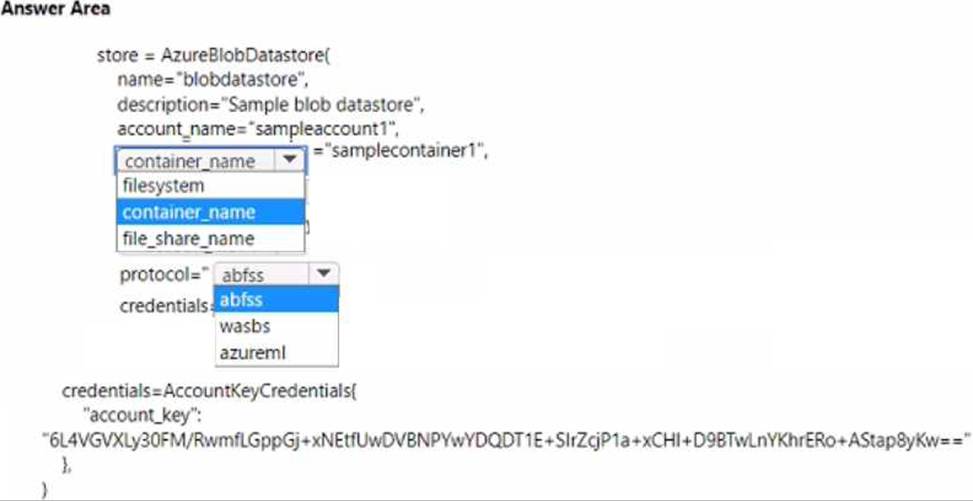
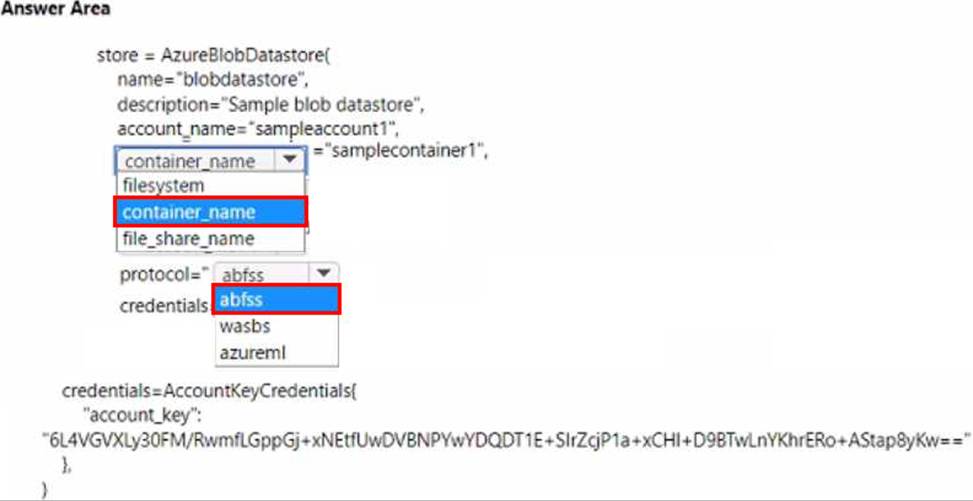
You must register an Azure Blob storage datastore in workspace1 by using an access key. You develop Python SDK v2 code to import all modules required to register the datastore.
You need to complete the Python SDK v2 code to define the datastore.
How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.