
Practice Free DP-100 Exam Online Questions
You are moving a large dataset from Azure Machine Learning Studio to a Weka environment.
You need to format the data for the Weka environment.
Which module should you use?
- A . Convert to CSV
- B . Convert to Dataset
- C . Convert to ARFF
- D . Convert to SVMLight
You write a Python script that processes data in a comma-separated values (CSV) file.
You plan to run this script as an Azure Machine Learning experiment.
The script loads the data and determines the number of rows it contains using the following code:

You need to record the row count as a metric named row_count that can be returned using the get_metrics method of the Run object after the experiment run completes.
Which code should you use?
- A . run.upload_file(‘row_count’, ‘./data.csv’)
- B . run.log(‘row_count’, rows)
- C . run.tag(‘row_count’, rows)
- D . run.log_table(‘row_count’, rows)
- E . run.log_row(‘row_count’, rows)
You must use the Azure Machine Learning SDK to interact with data and experiments in the workspace.
You need to configure the config.json file to connect to the workspace from the Python environment.
You create the following config.json file.
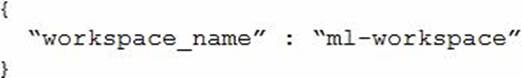
Which two additional parameters must you add to the config.json file in order to connect to the workspace? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . subscription_Id
- B . Key
- C . resource_group
- D . region
- E . Login
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are creating a new experiment in Azure Machine Learning Studio.
One class has a much smaller number of observations than tin- other classes in the training set.
You need to select an appropriate data sampling strategy to compensate for the class imbalance.
Solution: You use the Principal Components Analysis (PCA) sampling mode.
Does the solution meet the goal?
- A . Yes
- B . No
You have an Azure Machine Learning workspace. You build a deep learning model.
You need to publish a GPU-enabled model as a web service.
Which two compute targets can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . Azure Kubernetes Service (AKS)
- B . Azure Container Instances (ACI)
- C . Local web service
- D . Azure Machine Learning compute clusters
You are a data scientist working for a hotel booking website company. You use the Azure Machine Learning service to train a model that identifies fraudulent transactions.
You must deploy the model as an Azure Machine Learning real-time web service using the Model.deploy method in the Azure Machine Learning SDK. The deployed web service must return real-time predictions of fraud based on transaction data input.
You need to create the script that is specified as the entry_script parameter for the InferenceConfig class used to deploy the model.
What should the entry script do?
- A . Start a node on the inference cluster where the web service is deployed.
- B . Register the model with appropriate tags and properties.
- C . Create a Conda environment for the web service compute and install the necessary Python packages.
- D . Load the model and use it to predict labels from input data.
- E . Specify the number of cores and the amount of memory required for the inference compute.
You are a data scientist working for a hotel booking website company. You use the Azure Machine Learning service to train a model that identifies fraudulent transactions.
You must deploy the model as an Azure Machine Learning real-time web service using the Model.deploy method in the Azure Machine Learning SDK. The deployed web service must return real-time predictions of fraud based on transaction data input.
You need to create the script that is specified as the entry_script parameter for the InferenceConfig class used to deploy the model.
What should the entry script do?
- A . Start a node on the inference cluster where the web service is deployed.
- B . Register the model with appropriate tags and properties.
- C . Create a Conda environment for the web service compute and install the necessary Python packages.
- D . Load the model and use it to predict labels from input data.
- E . Specify the number of cores and the amount of memory required for the inference compute.
HOTSPOT
You use Azure Machine Learning to implement hyperparameter tuning for an Azure ML Python SDK v2-based model training.
Training runs must terminate when the primary metric is lowered by 25 percent or more compared to the best performing run.
You need to configure an early termination policy to terminate training jobs.
Which values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.

You plan to run a Python script as an Azure Machine Learning experiment.
The script contains the following code:
import os, argparse, glob
from azureml.core import Run
parser = argparse.ArgumentParser()
parser.add_argument(‘–input-data’,
type=str, dest=’data_folder’)
args = parser.parse_args()
data_path = args.data_folder
file_paths = glob.glob(data_path + "/*.jpg")
You must specify a file dataset as an input to the script. The dataset consists of multiple large image files and must be streamed directly from its source.
You need to write code to define a ScriptRunConfig object for the experiment and pass the ds dataset as an argument.
Which code segment should you use?
- A . arguments = [‘–input-data’, ds.to_pandas_dataframe()]
- B . arguments = [‘–input-data’, ds.as_mount()]
- C . arguments = [‘–data-data’, ds]
- D . arguments = [‘–input-data’, ds.as_download()]
You plan to run a Python script as an Azure Machine Learning experiment.
The script contains the following code:
import os, argparse, glob
from azureml.core import Run
parser = argparse.ArgumentParser()
parser.add_argument(‘–input-data’,
type=str, dest=’data_folder’)
args = parser.parse_args()
data_path = args.data_folder
file_paths = glob.glob(data_path + "/*.jpg")
You must specify a file dataset as an input to the script. The dataset consists of multiple large image files and must be streamed directly from its source.
You need to write code to define a ScriptRunConfig object for the experiment and pass the ds dataset as an argument.
Which code segment should you use?
- A . arguments = [‘–input-data’, ds.to_pandas_dataframe()]
- B . arguments = [‘–input-data’, ds.as_mount()]
- C . arguments = [‘–data-data’, ds]
- D . arguments = [‘–input-data’, ds.as_download()]