Practice Free DP-100 Exam Online Questions
You manage an Azure Machine Learning workspace. The Pylhon scrip! named scriptpy reads an argument named training_data. The trainlng.data argument specifies the path to the training data in a file named datasetl.csv. You plan to run the scriptpy Python script as a command job that trains a machine learning model. You need to provide the command to pass the path for the datasct as a parameter value when you submit the script as a training job.
Solution: python script.py Ctraining_data dataset1, csv
Does the solution meet the goal?
- A . Yes
- B . No
You create a multi-class image classification model with automated machine learning in Azure Machine Learning.
You need to prepare labeled image data as input for model training in the form of an Azure Machine Learning tabular dataset.
Which data format should you use?
- A . COCO
- B . JSONL
- C . JSON
- D . Pascal VOC
HOTSPOT
You train a model by using Azure Machine Learning. You use Azure Blob Storage to store production data.
The model must be re-trained when new data is uploaded to Azure Blob Storage. You need to minimize development and coding.
You need to configure Azure services to develop a re-training solution.
Which Azure services should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.


You manage an Azure Machine Learning workspace. The Pylhon scrip! named scriptpy reads an argument named training_data. The trainlng.data argument specifies the path to the training data in a file named datasetl.csv. You plan to run the scriptpy Python script as a command job that trains a machine learning model. You need to provide the command to pass the path for the datasct as a parameter value when you submit the script as a training job.
Solution: python script.py Ctraining_data ${{inputs,training_data}}
Does the solution meet the goal?
- A . Yes
- B . No
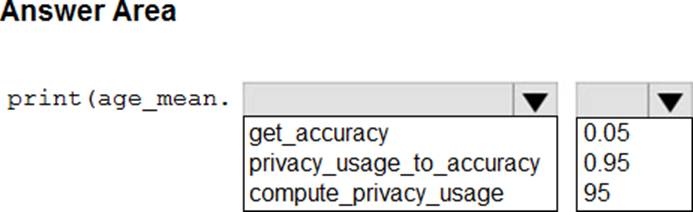
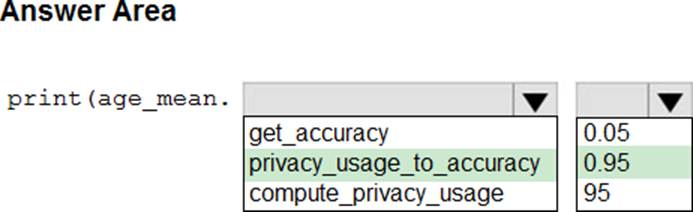
HOTSPOT
You create an Azure Machine Learning workspace and a dataset. The dataset includes age values for a large group of diabetes patients. You use the dp.mean function from the SmartNoise library to calculate the mean of the age value. You store the value in a variable named age.mean.
You must output the value of the interval range of released mean values that will be returned 95 percent of the time.
You need to complete the code.
Which code values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You plan to use a Python script to run an Azure Machine Learning experiment.
The script creates a reference to the experiment run context, loads data from a file, identifies the set of unique values for the label column, and completes the experiment run:
from azureml.core import Run
import pandas as pd
run = Run.get_context()
data = pd.read_csv(‘data.csv’)
label_vals = data[‘label’].unique()
# Add code to record metrics here
run.complete()
The experiment must record the unique labels in the data as metrics for the run that can be reviewed later.
You must add code to the script to record the unique label values as run metrics at the point indicated by the comment.
Solution: Replace the comment with the following code:
run.log_list(‘Label Values’, label_vals)
Does the solution meet the goal?
- A . Yes
- B . No
You run a script as an experiment in Azure Machine Learning.
You have a Run object named run that references the experiment run. You must review the log files that were generated during the experiment run.
You need to download the log files to a local folder for review.
Which two code segments can you run to achieve this goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . run.get_details()
- B . run.get_file_names()
- C . run.get_metrics()
- D . run.download_files(output_directory=’./runfiles’)
- E . run.get_all_logs(destination=’./runlogs’)
HOTSPOT
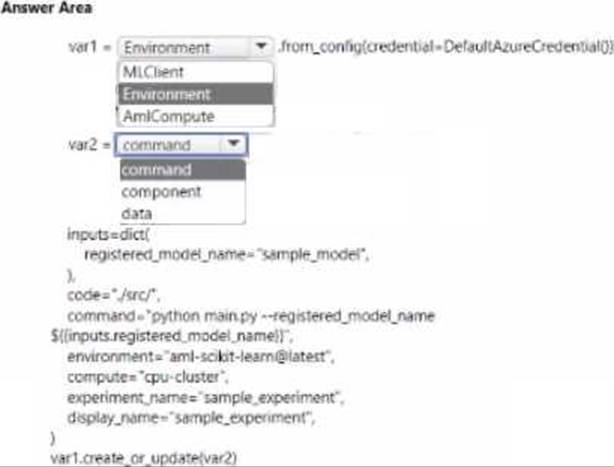
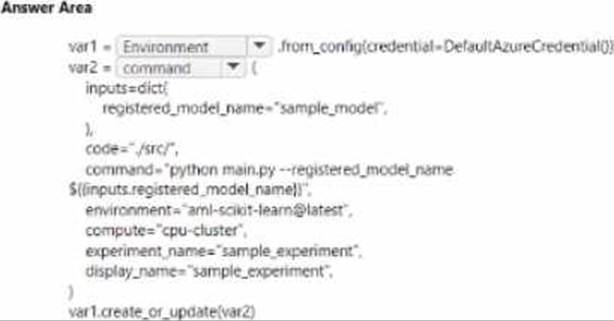
You create an Azure Machine Learning workspace
You are developing a Python SDK v2 notebook to perform custom model training in the workspace.
The notebook code imports all required packages.
You need to complete the Python SDK v2 code to include a training script. environment, and compute information.
How should you complete ten code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point
You create an MLflow model
You must deploy the model to Azure Machine Learning for batch inference.
You need to create the batch deployment.
Which two components should you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point
- A . Compute target
- B . Kubernetes online endpoint
- C . Model files
- D . Online endpoint
- E . Environment
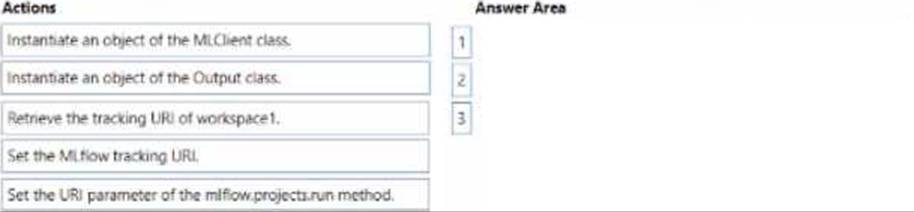
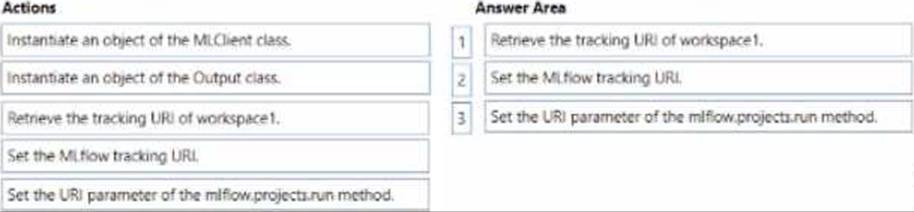
DRAG DROP
You manage an Azure Machine Learning workspace named workspace1 and a Data Science Virtual Machine (DSVM) named DSMV1.
You must an experiment in DSMV1 by using a Jupiter notebook and Python SDK v2 code. You must store metrics and artifacts in workspace 1 You start by creating Python SCK v2 code to import ail required packages.
You need to implement the Python SOK v2 code to store metrics and article in workspace1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them the correctly order.