
Practice Free DP-100 Exam Online Questions
You are authoring a notebook in Azure Machine Learning studio.
You must install packages from the notebook into the currently running kernel. The installation must be limited to the currently running kernel only.
You need to install the packages.
Which magic function should you use?
- A . !pjp
- B . %load
- C . !conda
- D . %pip
You create a pipeline in designer to train a model that predicts automobile prices.
Because of non-linear relationships in the data, the pipeline calculates the natural log (Ln) of the prices in the training data, trains a model to predict this natural log of price value, and then calculates the exponential of the scored label to get the predicted price.
The training pipeline is shown in the exhibit. (Click the Training pipeline tab.)
Training pipeline
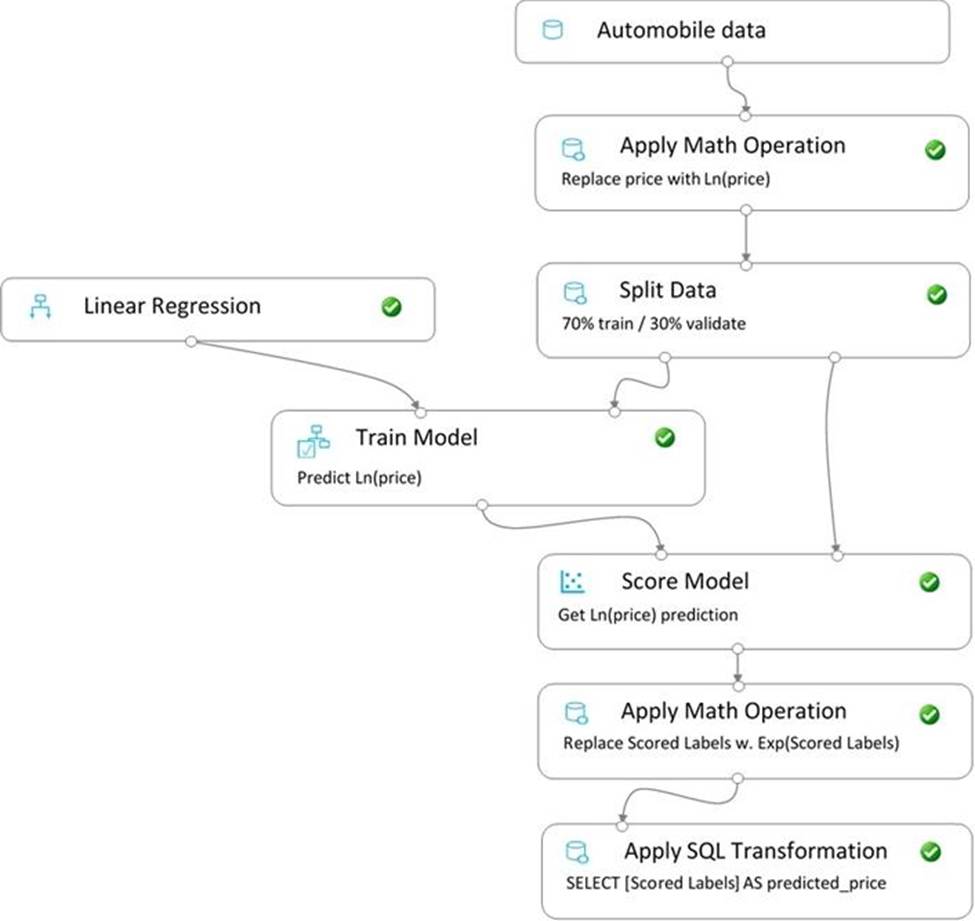
You create a real-time inference pipeline from the training pipeline, as shown in the exhibit. (Click the Real-time pipeline tab.)
Real-time pipeline
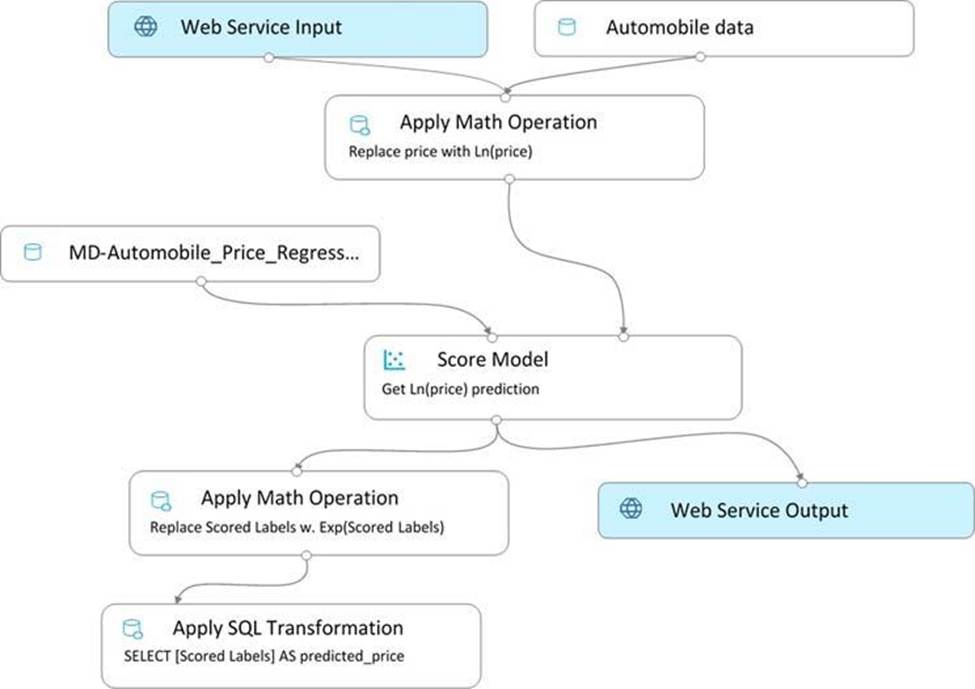
You need to modify the inference pipeline to ensure that the web service returns the exponential of the scored label as the predicted automobile price and that client applications are not required to include a price value in the input values.
Which three modifications must you make to the inference pipeline? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A . Connect the output of the Apply SQL Transformation to the Web Service Output module.
- B . Replace the Web Service Input module with a data input that does not include the price column.
- C . Add a Select Columns module before the Score Model module to select all columns other than price.
- D . Replace the training dataset module with a data input that does not include the price column.
- E . Remove the Apply Math Operation module that replaces price with its natural log from the data flow.
- F . Remove the Apply SQL Transformation module from the data flow.
You create a binary classification model. The model is registered in an Azure Machine Learning workspace. You use the Azure Machine Learning Fairness SDK to assess the model fairness.
You develop a training script for the model on a local machine.
You need to load the model fairness metrics into Azure Machine Learning studio.
What should you do?
- A . Implement the download_dashboard_by_upload_id function
- B . Implement the creace_group_metric_sec function
- C . Implement the upload_dashboard_dictionary function
- D . Upload the training script
You use Azure Machine Learning to train a model based on a dataset named dataset1.
You define a dataset monitor and create a dataset named dataset2 that contains new data.
You need to compare dataset1 and dataset2 by using the Azure Machine Learning SDK for Python.
Which method of the DataDriftDetector class should you use?
- A . run
- B . get
- C . backfill
- D . update
You use Azure Machine Learning to train a model based on a dataset named dataset1.
You define a dataset monitor and create a dataset named dataset2 that contains new data.
You need to compare dataset1 and dataset2 by using the Azure Machine Learning SDK for Python.
Which method of the DataDriftDetector class should you use?
- A . run
- B . get
- C . backfill
- D . update
You use Azure Machine Learning to train a model based on a dataset named dataset1.
You define a dataset monitor and create a dataset named dataset2 that contains new data.
You need to compare dataset1 and dataset2 by using the Azure Machine Learning SDK for Python.
Which method of the DataDriftDetector class should you use?
- A . run
- B . get
- C . backfill
- D . update
HOTSPOT
You have an Azure Machine Learning workspace.
You plan to use Azure Machine Learning Python SDK v2 lo register a component in the workspace. The component definition is stored in the local file ./components/train/train.yml.
You write code to connect to the workspace by using the ml_client object and import all required libraries
You need to complete the remaining code.
How should you complete the code? to answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
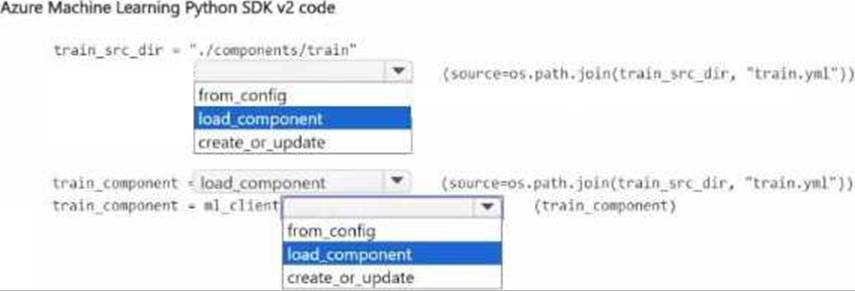

You are developing a data science workspace that uses an Azure Machine Learning service.
You need to select a compute target to deploy the workspace.
What should you use?
- A . Azure Data Lake Analytics
- B . Azure Databrick .
- C . Apache Spark for HDInsight.
- D . Azure Container Service
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You train and register an Azure Machine Learning model.
You plan to deploy the model to an online endpoint.
You need to ensure that applications will be able to use the authentication method with a non-expiring artifact to access the model.
Solution:
Create a managed online endpoint and set the value of its auto_mode parameter to key. Deploy the model to the inline endpoint.
Does the solution meet the goal?
- A . Yes
- B . No
You run an experiment that uses an AutoMLConfig class to define an automated machine learning task with a maximum of ten model training iterations. The task will attempt to find the best performing model based on a metric named accuracy.
You submit the experiment with the following code:

You need to create Python code that returns the best model that is generated by the automated machine learning task.
Which code segment should you use?
- A . best_model = automl_run.get_details()
- B . best_model = automl_run.get_output()[1]
- C . best_model = automl_run.get_file_names()[1]
- D . best_model = automl_run.get_metrics()