
Practice Free DP-100 Exam Online Questions
DRAG DROP
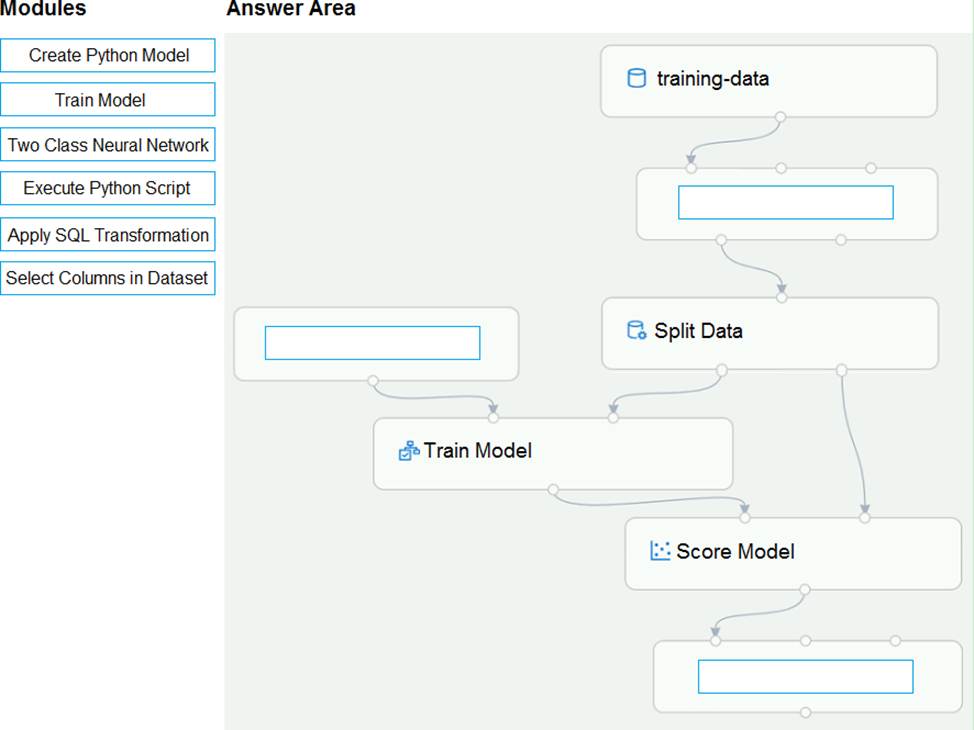
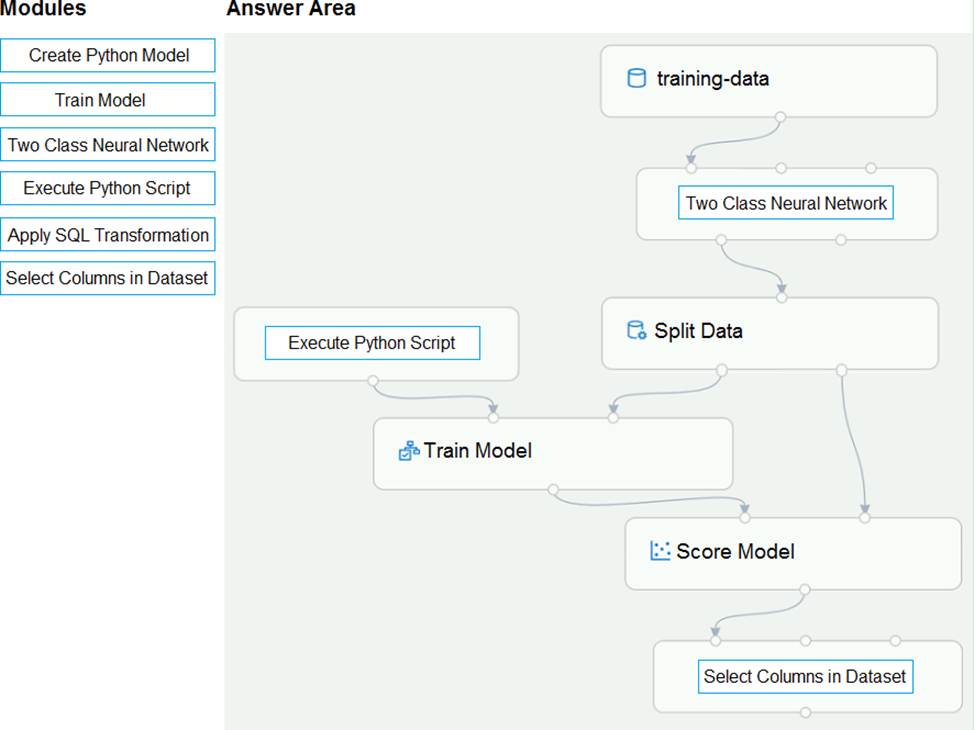
You create a training pipeline using the Azure Machine Learning designer. You upload a CSV file that contains the data from which you want to train your model.
You need to use the designer to create a pipeline that includes steps to perform the following tasks:
Select the training features using the pandas filter method.
Train a model based on the naive_bayes.GaussianNB algorithm.
Return only the Scored Labels column by using the query SELECT [Scored Labels] FROM t1;
Which modules should you use? To answer, drag the appropriate modules to the appropriate locations. Each module name may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
You use the Azure Machine Learning SDK in a notebook to run an experiment using a script file in an experiment folder.
The experiment fails.
You need to troubleshoot the failed experiment.
What are two possible ways to achieve this goal? Each correct answer presents a complete solution.
- A . Use the get_metrics() method of the run object to retrieve the experiment run logs.
- B . Use the get_details_with_logs() method of the run object to display the experiment run logs.
- C . View the log files for the experiment run in the experiment folder.
- D . View the logs for the experiment run in Azure Machine Learning studio.
- E . Use the get_output() method of the run object to retrieve the experiment run logs.
HOTSPOT
You are implementing hyperparameter tuning for a model training from a notebook. The notebook is in an Azure Machine Learning workspace. You add code that imports all relevant Python libraries.
You must configure Bayesian sampling over the search space for the num_hidden_layers and batch_size hyperparameters.
You need to complete the following Python code to configure Bayesian sampling.
Which code segments should you use? To answer, select the appropriate options in the answer area NOTE: Each correct selection is worth one point.


You create a batch inference pipeline by using the Azure ML SDK.
You configure the pipeline parameters by executing the following code:

You need to obtain the output from the pipeline execution.
Where will you find the output?
- A . the Activity Log in the Azure portal for the Machine Learning workspace
- B . a file named parallel_run_step.txt located in the output folder
- C . the digitjdentification.py script
- D . the Inference Clusters tab in Machine Learning studio
- E . the debug log
You are performing a filter based feature selection for a dataset 10 build a multi class classifies by using Azure Machine Learning Studio.
The dataset contains categorical features that are highly correlated to the output label column.
You need to select the appropriate feature scoring statistical method to identify the key predictors.
Which method should you use?
- A . Chi-squared
- B . Spearman correlation
- C . Kendall correlation
- D . Person correlation
You are building a binary classification model by using a supplied training set.
The training set is imbalanced between two classes.
You need to resolve the data imbalance.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution NOTE: Each correct selection is worth one point.
- A . Penalize the classification
- B . Resample the data set using under sampling or oversampling
- C . Generate synthetic samples in the minority class.
- D . Use accuracy as the evaluation metric of the model.
- E . Normalize the training feature set.
You plan to deliver a hands-on workshop to several students. The workshop will focus on creating data visualizations using Python. Each student will use a device that has internet access.
Student devices are not configured for Python development. Students do not have administrator access to install software on their devices. Azure subscriptions are not available for students. You need to ensure that students can run Python-based data visualization code.
Which Azure tool should you use?
- A . Anaconda Data Science Platform
- B . Azure BatchAl
- C . Azure Notebooks
- D . Azure Machine Learning Service
HOTSPOT
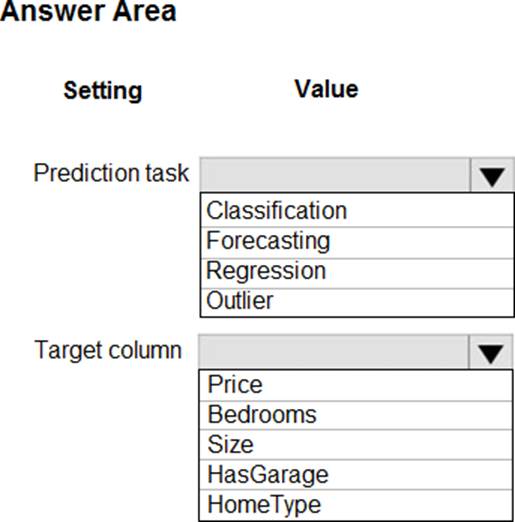
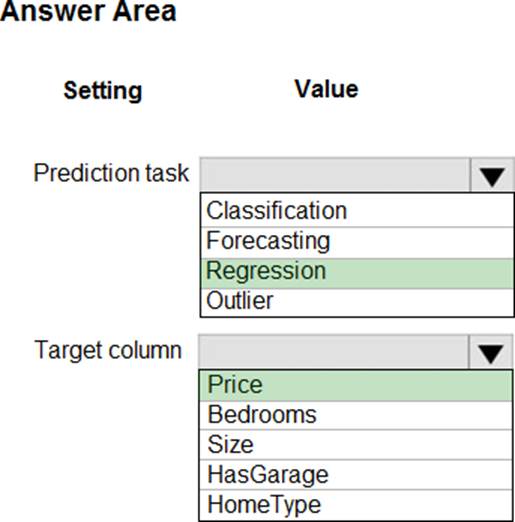
You have a dataset that includes home sales data for a city.
The dataset includes the following columns.

Each row in the dataset corresponds to an individual home sales transaction.
You need to use automated machine learning to generate the best model for predicting the sales price based on the features of the house.
Which values should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You are analyzing a dataset by using Azure Machine Learning Studio.
YOU need to generate a statistical summary that contains the p value and the unique value count for each feature column.
Which two modules can you users? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
- A . Execute Python Script
- B . Export Count Table
- C . Convert to Indicator Values
- D . Summarize Data
- E . Compute linear Correlation
HOTSPOT
You use an Azure Machine Learning workspace.
You create the following Python code:

For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.

