
Practice Free Databricks Generative AI Engineer Associate Exam Online Questions
A Generative AI Engineer is building a RAG application that will rely on context retrieved from source documents that are currently in PDF format. These PDFs can contain both text and images. They want to develop a solution using the least amount of lines of code.
Which Python package should be used to extract the text from the source documents?
- A . flask
- B . beautifulsoup
- C . unstructured
- D . numpy
B
Explanation:
Problem Context: The engineer needs to extract text from PDF documents, which may contain both text and images. The goal is to find a Python package that simplifies this task using the least amount of code.
Explanation of Options:
Option A: flask: Flask is a web framework for Python, not suitable for processing or extracting content from PDFs.
Option B: beautifulsoup: Beautiful Soup is designed for parsing HTML and XML documents, not PDFs.
Option C: unstructured: This Python package is specifically designed to work with unstructured data, including extracting text from PDFs. It provides functionalities to handle various types of content in documents with minimal coding, making it ideal for the task.
Option D: numpy: Numpy is a powerful library for numerical computing in Python and does not provide any tools for text extraction from PDFs.
Given the requirement, Option C (unstructured) is the most appropriate as it directly addresses the need to efficiently extract text from PDF documents with minimal code.
A Generative Al Engineer is using an LLM to classify species of edible mushrooms based on text descriptions of certain features. The model is returning accurate responses in testing and the Generative Al Engineer is confident they have the correct list of possible labels, but the output frequently contains additional reasoning in the answer when the Generative Al Engineer only wants to return the label with no additional text.
Which action should they take to elicit the desired behavior from this LLM?
- A . Use few snot prompting to instruct the model on expected output format
- B . Use zero shot prompting to instruct the model on expected output format
- C . Use zero shot chain-of-thought prompting to prevent a verbose output format
- D . Use a system prompt to instruct the model to be succinct in its answer
D
Explanation:
The LLM classifies mushroom species accurately but includes unwanted reasoning text, and the engineer wants only the label. Let’s assess how to control output format effectively.
Option A: Use few shot prompting to instruct the model on expected output format Few-shot prompting provides examples (e.g., input: description, output: label). It can work but requires crafting multiple examples, which is effort-intensive and less direct than a clear instruction. Databricks
Reference: "Few-shot prompting guides LLMs via examples, effective for format control but requires careful design" ("Generative AI Cookbook").
Option B: Use zero shot prompting to instruct the model on expected output format Zero-shot prompting relies on a single instruction (e.g., “Return only the label”) without examples. It’s simpler than few-shot but may not consistently enforce succinctness if the LLM’s default behavior is verbose.
Databricks
Reference: "Zero-shot prompting can specify output but may lack precision without examples" ("Building LLM Applications with Databricks").
Option C: Use zero shot chain-of-thought prompting to prevent a verbose output format Chain-of-Thought (CoT) encourages step-by-step reasoning, which increases verbosity―opposite to the desired outcome. This contradicts the goal of label-only output.
Databricks
Reference: "CoT prompting enhances reasoning but often results in detailed responses" ("Databricks Generative AI Engineer Guide").
Option D: Use a system prompt to instruct the model to be succinct in its answer
A system prompt (e.g., “Respond with only the species label, no additional text”) sets a global instruction for the LLM’s behavior. It’s direct, reusable, and effective for controlling output style across queries.
Databricks
Reference: "System prompts define LLM behavior consistently, ideal for enforcing concise outputs" ("Generative AI Cookbook," 2023).
Conclusion: Option D is the most effective and straightforward action, using a system prompt to enforce succinct, label-only responses, aligning with Databricks’ best practices for output control.
A team wants to serve a code generation model as an assistant for their software developers. It should support multiple programming languages. Quality is the primary objective.
Which of the Databricks Foundation Model APIs, or models available in the Marketplace, would be the best fit?
- A . Llama2-70b
- B . BGE-large
- C . MPT-7b
- D . CodeLlama-34B
D
Explanation:
For a code generation model that supports multiple programming languages and where quality is the primary objective, CodeLlama-34B is the most suitable choice.
Here’s the reasoning:
Specialization in Code Generation:
CodeLlama-34B is specifically designed for code generation tasks. This model has been trained with a focus on understanding and generating code, which makes it particularly adept at handling various programming languages and coding contexts.
Capacity and Performance:
The "34B" indicates a model size of 34 billion parameters, suggesting a high capacity for handling complex tasks and generating high-quality outputs. The large model size typically correlates with better understanding and generation capabilities in diverse scenarios.
Suitability for Development Teams:
Given that the model is optimized for code, it will be able to assist software developers more effectively than general-purpose models. It understands coding syntax, semantics, and the nuances of different programming languages.
Why Other Options Are Less Suitable:
A (Llama2-70b): While also a large model, it’s more general-purpose and may not be as fine-tuned for code generation as CodeLlama.
B (BGE-large): This model may not specifically focus on code generation.
C (MPT-7b): Smaller than CodeLlama-34B and likely less capable in handling complex code generation tasks at high quality.
Therefore, for a high-quality, multi-language code generation application, CodeLlama-34B (option D) is the best fit.
A Generative Al Engineer is working with a retail company that wants to enhance its customer experience by automatically handling common customer inquiries. They are working on an LLM-powered Al solution that should improve response times while maintaining a personalized interaction. They want to define the appropriate input and LLM task to do this.
Which input/output pair will do this?
- A . Input: Customer reviews; Output Group the reviews by users and aggregate per-user average rating, then respond
- B . Input: Customer service chat logs; Output Group the chat logs by users, followed by summarizing each user’s interactions, then respond
- C . Input: Customer service chat logs; Output: Find the answers to similar questions and respond with a summary
- D . Input: Customer reviews: Output Classify review sentiment
C
Explanation:
The task described in the question involves enhancing customer experience by automatically handling common customer inquiries using an LLM-powered AI solution. This requires the system to process input data (customer inquiries) and generate personalized, relevant responses efficiently. Let’s evaluate the options step-by-step in the context of Databricks Generative AI Engineer principles, which emphasize leveraging LLMs for tasks like question answering, summarization, and retrieval-augmented generation (RAG).
Option A: Input: Customer reviews; Output: Group the reviews by users and aggregate per-user average rating, then respond
This option focuses on analyzing customer reviews to compute average ratings per user. While this might be useful for sentiment analysis or user profiling, it does not directly address the goal of handling common customer inquiries or improving response times for personalized interactions. Customer reviews are typically feedback data, not real-time inquiries requiring immediate responses.
Databricks
Reference: Databricks documentation on LLMs (e.g., "Building LLM Applications with Databricks") emphasizes that LLMs excel at tasks like question answering and conversational responses, not just aggregation or statistical analysis of reviews.
Option B: Input: Customer service chat logs; Output: Group the chat logs by users, followed by summarizing each user’s interactions, then respond
This option uses chat logs as input, which aligns with customer service scenarios. However, the output―grouping by users and summarizing interactions―focuses on user-specific summaries rather than directly addressing inquiries. While summarization is an LLM capability, this approach lacks the specificity of finding answers to common questions, which is central to the problem. Databricks
Reference: Per Databricks’ "Generative AI Cookbook," LLMs can summarize text, but for customer service, the emphasis is on retrieval and response generation (e.g., RAG workflows) rather than user interaction summaries alone.
Option C: Input: Customer service chat logs; Output: Find the answers to similar questions and respond with a summary
This option uses chat logs (real customer inquiries) as input and tasks the LLM with identifying answers to similar questions, then providing a summarized response. This directly aligns with the goal of handling common inquiries efficiently while maintaining personalization (by referencing past interactions or similar cases). It leverages LLM capabilities like semantic search, retrieval, and response generation, which are core to Databricks’ LLM workflows.
Databricks
Reference: From Databricks documentation ("Building LLM-Powered Applications," 2023),
an exact extract states: "For customer support use cases, LLMs can be used to retrieve relevant answers from historical data like chat logs and generate concise, contextually appropriate responses." This matches Option C’s approach of finding answers and summarizing them.
Option D: Input: Customer reviews; Output: Classify review sentiment
This option focuses on sentiment classification of reviews, which is a valid LLM task but unrelated to handling customer inquiries or improving response times in a conversational context. It’s more suited for feedback analysis than real-time customer service.
Databricks
Reference: Databricks’ "Generative AI Engineer Guide" notes that sentiment analysis is a common LLM task, but it’s not highlighted for real-time conversational applications like customer support.
Conclusion: Option C is the best fit because it uses relevant input (chat logs) and defines an LLM task (finding answers and summarizing) that meets the requirements of improving response times and maintaining personalized interaction. This aligns with Databricks’ recommended practices for LLM-powered customer service solutions, such as retrieval-augmented generation (RAG) workflows.
What is an effective method to preprocess prompts using custom code before sending them to an LLM?
- A . Directly modify the LLM’s internal architecture to include preprocessing steps
- B . It is better not to introduce custom code to preprocess prompts as the LLM has not been trained with examples of the preprocessed prompts
- C . Rather than preprocessing prompts, it’s more effective to postprocess the LLM outputs to align the outputs to desired outcomes
- D . Write a MLflow PyFunc model that has a separate function to process the prompts
D
Explanation:
The most effective way to preprocess prompts using custom code is to write a custom model, such as an MLflow PyFunc model. Here’s a breakdown of why this is the correct approach: MLflow PyFunc Models:
MLflow is a widely used platform for managing the machine learning lifecycle, including experimentation, reproducibility, and deployment. A PyFunc model is a generic Python function model that can implement custom logic, which includes preprocessing prompts.
Preprocessing Prompts:
Preprocessing could include various tasks like cleaning up the user input, formatting it according to specific rules, or augmenting it with additional context before passing it to the LLM. Writing this preprocessing as part of a PyFunc model allows the custom code to be managed, tested, and deployed easily.
Modular and Reusable:
By separating the preprocessing logic into a PyFunc model, the system becomes modular, making it easier to maintain and update without needing to modify the core LLM or retrain it.
Why Other Options Are Less Suitable:
A (Modify LLM’s Internal Architecture): Directly modifying the LLM’s architecture is highly impractical and can disrupt the model’s performance. LLMs are typically treated as black-box models for tasks like prompt processing.
B (Avoid Custom Code): While it’s true that LLMs haven’t been explicitly trained with preprocessed prompts, preprocessing can still improve clarity and alignment with desired input formats without confusing the model.
C (Postprocessing Outputs): While postprocessing the output can be useful, it doesn’t address the need for clean and well-formatted inputs, which directly affect the quality of the model’s responses. Thus, using an MLflow PyFunc model allows for flexible and controlled preprocessing of prompts in a scalable way, making it the most effective method.
A Generative Al Engineer needs to design an LLM pipeline to conduct multi-stage reasoning that leverages external tools. To be effective at this, the LLM will need to plan and adapt actions while performing complex reasoning tasks.
Which approach will do this?
- A . Tram the LLM to generate a single, comprehensive response without interacting with any external tools, relying solely on its pre-trained knowledge.
- B . Implement a framework like ReAct which allows the LLM to generate reasoning traces and perform task-specific actions that leverage external tools if necessary.
- C . Encourage the LLM to make multiple API calls in sequence without planning or structuring the calls, allowing the LLM to decide when and how to use external tools spontaneously.
- D . Use a Chain-of-Thought (CoT) prompting technique to guide the LLM through a series of reasoning steps, then manually input the results from external tools for the final answer.
B
Explanation:
The task requires an LLM pipeline for multi-stage reasoning with external tools, necessitating planning, adaptability, and complex reasoning. Let’s evaluate the options based on Databricks’ recommendations for advanced LLM workflows.
Option A: Train the LLM to generate a single, comprehensive response without interacting with any external tools, relying solely on its pre-trained knowledge
This approach limits the LLM to its static knowledge base, excluding external tools and multi-stage reasoning. It can’t adapt or plan actions dynamically, failing the requirements.
Databricks
Reference: "External tools enhance LLM capabilities beyond pre-trained knowledge" ("Building LLM Applications with Databricks," 2023).
Option B: Implement a framework like ReAct which allows the LLM to generate reasoning traces and perform task-specific actions that leverage external tools if necessary
ReAct (Reasoning + Acting) combines reasoning traces (step-by-step logic) with actions (e.g., tool calls), enabling the LLM to plan, adapt, and execute complex tasks iteratively. This meets all requirements: multi-stage reasoning, tool use, and adaptability.
Databricks
Reference: "Frameworks like ReAct enable LLMs to interleave reasoning and external tool interactions for complex problem-solving" ("Generative AI Cookbook," 2023).
Option C: Encourage the LLM to make multiple API calls in sequence without planning or structuring the calls, allowing the LLM to decide when and how to use external tools spontaneously Unstructured, spontaneous API calls lack planning and may lead to inefficient or incorrect tool usage. This doesn’t ensure effective multi-stage reasoning or adaptability.
Databricks
Reference: Structured frameworks are preferred: "Ad-hoc tool calls can reduce reliability in complex tasks" ("Building LLM-Powered Applications").
Option D: Use a Chain-of-Thought (CoT) prompting technique to guide the LLM through a series of reasoning steps, then manually input the results from external tools for the final answer CoT improves reasoning but relies on manual tool interaction, breaking automation and adaptability.
It’s not a scalable pipeline solution.
Databricks
Reference: "Manual intervention is impractical for production LLM pipelines" ("Databricks Generative AI Engineer Guide").
Conclusion: Option B (ReAct) is the best approach, as it integrates reasoning and tool use in a structured, adaptive framework, aligning with Databricks’ guidance for complex LLM workflows.
A Generative Al Engineer would like an LLM to generate formatted JSON from emails.
This will require parsing and extracting the following information: order ID, date, and sender email.
Here’s a sample email:
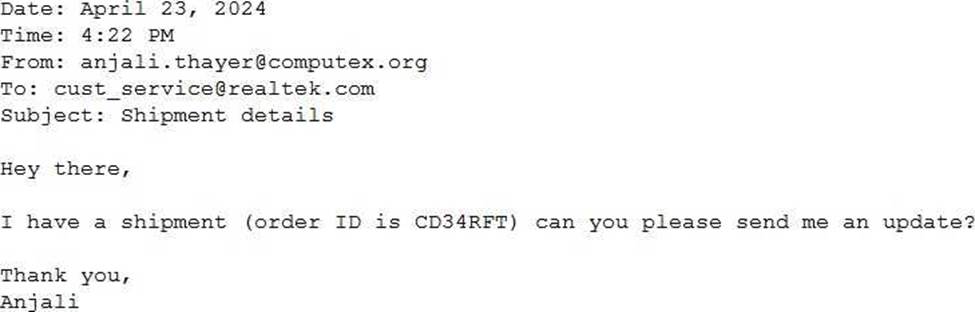
They will need to write a prompt that will extract the relevant information in JSON format with the
highest level of output accuracy.
Which prompt will do that?
- A . You will receive customer emails and need to extract date, sender email, and order ID. You should return the date, sender email, and order ID information in JSON format.
- B . You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
Here’s an example: {“date”: “April 16, 2024”, “sender_email”: “[email protected]”, “order_id”: “RE987D”} - C . You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in a human-readable format.
- D . You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
B
Explanation:
Problem Context: The goal is to parse emails to extract certain pieces of information and output this in a structured JSON format. Clarity and specificity in the prompt design will ensure higher accuracy in the LLM’s responses.
Explanation of Options:
Option A: Provides a general guideline but lacks an example, which helps an LLM understand the exact format expected.
Option B: Includes a clear instruction and a specific example of the output format. Providing an example is crucial as it helps set the pattern and format in which the information should be structured, leading to more accurate results.
Option C: Does not specify that the output should be in JSON format, thus not meeting the requirement.
Option D: While it correctly asks for JSON format, it lacks an example that would guide the LLM on how to structure the JSON correctly.
Therefore, Option B is optimal as it not only specifies the required format but also illustrates it with an example, enhancing the likelihood of accurate extraction and formatting by the LLM.
A Generative Al Engineer has created a RAG application to look up answers to questions about a series of fantasy novels that are being asked on the author’s web forum. The fantasy novel texts are chunked and embedded into a vector store with metadata (page number, chapter number, book title), retrieved with the user’s query, and provided to an LLM for response generation. The Generative AI Engineer used their intuition to pick the chunking strategy and associated configurations but now wants to more methodically choose the best values.
Which TWO strategies should the Generative AI Engineer take to optimize their chunking strategy and parameters? (Choose two.)
- A . Change embedding models and compare performance.
- B . Add a classifier for user queries that predicts which book will best contain the answer. Use this to filter retrieval.
- C . Choose an appropriate evaluation metric (such as recall or NDCG) and experiment with changes in the chunking strategy, such as splitting chunks by paragraphs or chapters. Choose the strategy that gives the best performance metric.
- D . Pass known questions and best answers to an LLM and instruct the LLM to provide the best token count. Use a summary statistic (mean, median, etc.) of the best token counts to choose chunk size.
- E . Create an LLM-as-a-judge metric to evaluate how well previous questions are answered by the most appropriate chunk. Optimize the chunking parameters based upon the values of the metric.
C, E
Explanation:
To optimize a chunking strategy for a Retrieval-Augmented Generation (RAG) application, the Generative AI Engineer needs a structured approach to evaluating the chunking strategy, ensuring that the chosen configuration retrieves the most relevant information and leads to accurate and coherent LLM responses. Here’s why C and E are the correct strategies: Strategy C: Evaluation Metrics (Recall, NDCG)
Define an evaluation metric: Common evaluation metrics such as recall, precision, or NDCG (Normalized Discounted Cumulative Gain) measure how well the retrieved chunks match the user’s query and the expected response.
Recall measures the proportion of relevant information retrieved.
NDCG is often used when you want to account for both the relevance of retrieved chunks and the ranking or order in which they are retrieved.
Experiment with chunking strategies: Adjusting chunking strategies based on text structure (e.g., splitting by paragraph, chapter, or a fixed number of tokens) allows the engineer to experiment with
various ways of slicing the text. Some chunks may better align with the user’s query than others. Evaluate performance: By using recall or NDCG, the engineer can methodically test various chunking strategies to identify which one yields the highest performance. This ensures that the chunking method provides the most relevant information when embedding and retrieving data from the vector store.
Strategy E: LLM-as-a-Judge Metric
Use the LLM as an evaluator: After retrieving chunks, the LLM can be used to evaluate the quality of answers based on the chunks provided. This could be framed as a "judge" function, where the LLM compares how well a given chunk answers previous user queries.
Optimize based on the LLM’s judgment: By having the LLM assess previous answers and rate their relevance and accuracy, the engineer can collect feedback on how well different chunking configurations perform in real-world scenarios.
This metric could be a qualitative judgment on how closely the retrieved information matches the user’s intent.
Tune chunking parameters: Based on the LLM’s judgment, the engineer can adjust the chunk size or structure to better align with the LLM’s responses, optimizing retrieval for future queries.
By combining these two approaches, the engineer ensures that the chunking strategy is systematically evaluated using both quantitative (recall/NDCG) and qualitative (LLM judgment) methods. This balanced optimization process results in improved retrieval relevance and, consequently, better response generation by the LLM.
A Generative Al Engineer is deciding between using LSH (Locality Sensitive Hashing) and HNSW (Hierarchical Navigable Small World) for indexing their vector database Their top priority is semantic accuracy
Which approach should the Generative Al Engineer use to evaluate these two techniques?
- A . Compare the cosine similarities of the embeddings of returned results against those of a representative sample of test inputs
- B . Compare the Bilingual Evaluation Understudy (BLEU) scores of returned results for a representative sample of test inputs
- C . Compare the Recall-Onented-Understudy for Gistmg Evaluation (ROUGE) scores of returned results for a representative sample of test inputs
- D . Compare the Levenshtein distances of returned results against a representative sample of test inputs
A
Explanation:
The task is to choose between LSH and HNSW for a vector database index, prioritizing semantic accuracy. The evaluation must assess how well each method retrieves semantically relevant results. Let’s evaluate the options.
Option A: Compare the cosine similarities of the embeddings of returned results against those of a representative sample of test inputs
Cosine similarity measures semantic closeness between vectors, directly assessing retrieval accuracy in a vector database. Comparing returned results’ embeddings to test inputs’ embeddings evaluates how well LSH or HNSW preserves semantic relationships, aligning with the priority.
Databricks
Reference: "Cosine similarity is a standard metric for evaluating vector search accuracy" ("Databricks Vector Search Documentation," 2023).
Option B: Compare the Bilingual Evaluation Understudy (BLEU) scores of returned results for a representative sample of test inputs
BLEU evaluates text generation (e.g., translations), not vector retrieval accuracy. It’s irrelevant for indexing performance.
Databricks
Reference: "BLEU applies to generative tasks, not retrieval" ("Generative AI Cookbook").
Option C: Compare the Recall-Oriented-Understudy for Gisting Evaluation (ROUGE) scores of returned results for a representative sample of test inputs
ROUGE is for summarization evaluation, not vector search. It doesn’t measure semantic accuracy in retrieval.
Databricks
Reference: "ROUGE is unsuited for vector database evaluation" ("Building LLM Applications with Databricks").
Option D: Compare the Levenshtein distances of returned results against a representative sample of test inputs
Levenshtein distance measures string edit distance, not semantic similarity in embeddings. It’s inappropriate for vector-based retrieval.
Databricks
Reference: No specific support for Levenshtein in vector search contexts. Conclusion: Option A (cosine similarity) is the correct approach, directly evaluating semantic accuracy in vector retrieval, as recommended by Databricks for Vector Search assessments.