
Practice Free Associate Cloud Engineer Exam Online Questions
You are building an archival solution for your data warehouse and have selected Cloud Storage to archive your data. Your users need to be able to access this archived data once a quarter for some regulatory requirements. You want to select a cost-efficient option.
Which storage option should you use?
- A . Coldline Storage
- B . Nearline Storage
- C . Regional Storage
- D . Multi-Regional Storage
A
Explanation:
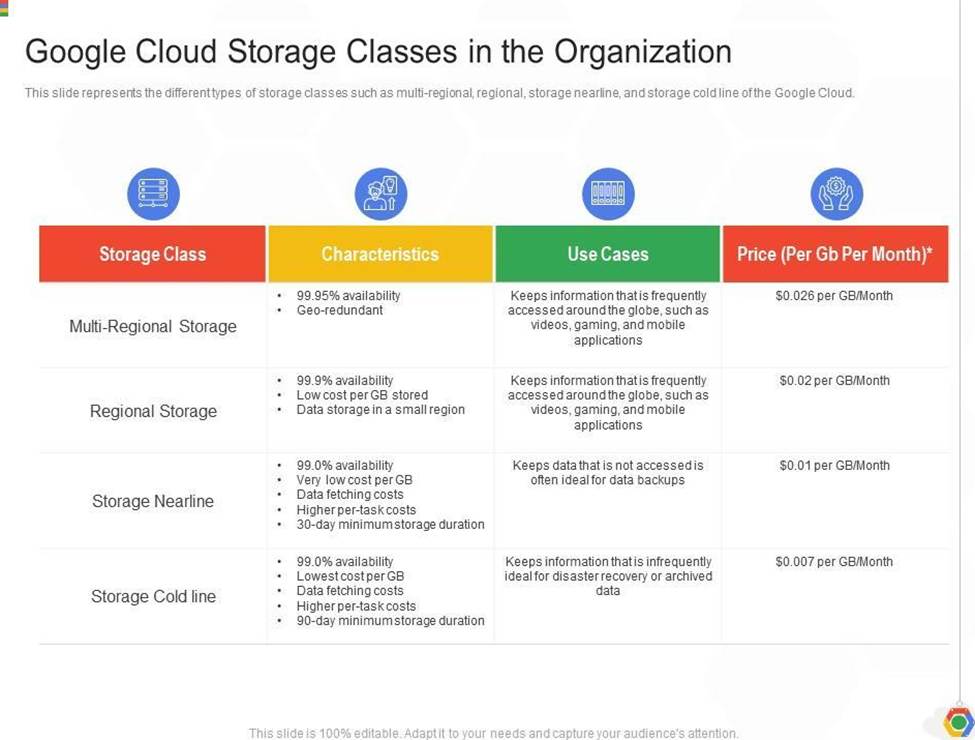
Coldline Storage is a very-low-cost, highly durable storage service for storing infrequently accessed data. Coldline Storage is ideal for data you plan to read or modify at most once a quarter. Since we have a requirement to access data once a quarter and want to go with the most cost-efficient option, we should select Coldline Storage.
Ref: https://cloud.google.com/storage/docs/storage-classes#coldline
You are building an archival solution for your data warehouse and have selected Cloud Storage to archive your data. Your users need to be able to access this archived data once a quarter for some regulatory requirements. You want to select a cost-efficient option.
Which storage option should you use?
- A . Coldline Storage
- B . Nearline Storage
- C . Regional Storage
- D . Multi-Regional Storage
A
Explanation:
Coldline Storage is a very-low-cost, highly durable storage service for storing infrequently accessed data. Coldline Storage is ideal for data you plan to read or modify at most once a quarter. Since we have a requirement to access data once a quarter and want to go with the most cost-efficient option, we should select Coldline Storage.
Ref: https://cloud.google.com/storage/docs/storage-classes#coldline
Your coworker has helped you set up several configurations for gcloud. You’ve noticed that you’re running commands against the wrong project. Being new to the company, you haven’t yet memorized any of the projects.
With the fewest steps possible, what’s the fastest way to switch to the correct configuration?
- A . Run gcloud configurations list followed by gcloud configurations activate .
- B . Run gcloud config list followed by gcloud config activate.
- C . Run gcloud config configurations list followed by gcloud config configurations activate.
- D . Re-authenticate with the gcloud auth login command and select the correct configurations on login.
C
Explanation:
as gcloud config configurations list can help check for the existing configurations and activate can help switch to the configuration.
gcloud config configurations list lists existing named configurations
gcloud config configurations activate activates an existing named configuration
Obtains access credentials for your user account via a web-based authorization flow. When this command completes successfully, it sets the active account in the current configuration to the account specified. If no configuration exists, it creates a configuration named default.
You are planning to migrate your containerized workloads to Google Kubernetes Engine (GKE). You need to determine which GKE option to use. Your solution must have high availability, minimal downtime, and the ability to promptly apply security updates to your nodes. You also want to pay only for the compute resources that your workloads use without managing nodes. You want to follow Google-recommended practices and minimize operational costs.
What should you do?
- A . Configure a Standard multi-zonal GKE cluster.
- B . Configure an Autopilot GKE cluster.
- C . Configure a Standard zonal GKE cluster.
- D . Configure a Standard regional GKE cluster.
You create a new Google Kubernetes Engine (GKE) cluster and want to make sure that it always runs a supported and stable version of Kubernetes.
What should you do?
- A . Enable the Node Auto-Repair feature for your GKE cluster.
- B . Enable the Node Auto-Upgrades feature for your GKE cluster.
- C . Select the latest available cluster version for your GKE cluster.
- D . Select “Container-Optimized OS (cos)” as a node image for your GKE cluster.
B
Explanation:
Creating or upgrading a cluster by specifying the version as latest does not provide automatic upgrades. Enable node auto-upgrades to ensure that the nodes in your cluster are up-to-date with the latest stable version.
https://cloud.google.com/kubernetes-engine/versioning-and-upgrades
Node auto-upgrades help you keep the nodes in your cluster up to date with the cluster master version when your master is updated on your behalf. When you create a new cluster or node pool with Google Cloud Console or the gcloud command, node auto-upgrade is enabled by default.
Ref: https://cloud.google.com/kubernetes-engine/docs/how-to/node-auto-upgrades
You need to manage a third-party application that will run on a Compute Engine instance. Other Compute Engine instances are already running with default configuration. Application installation files are hosted on Cloud Storage. You need to access these files from the new instance without allowing other virtual machines (VMs) to access these files.
What should you do?
- A . Create the instance with the default Compute Engine service account Grant the service account permissions on Cloud Storage.
- B . Create the instance with the default Compute Engine service account Add metadata to the objects on Cloud Storage that matches the metadata on the new instance.
- C . Create a new service account and assig n this service account to the new instance Grant the service account permissions on Cloud Storage.
- D . Create a new service account and assign this service account to the new instance Add metadata to the objects on Cloud Storage that matches the metadata on the new instance.
B
Explanation:
https://cloud.google.com/iam/docs/best-practices-for-using-and-managing-service-accounts
If an application uses third-party or custom identities and needs to access a resource, such as a BigQuery dataset or a Cloud Storage bucket, it must perform a transition between principals. Because Google Cloud APIs don’t recognize third-party or custom identities, the application can’t propagate the end-user’s identity to BigQuery or Cloud Storage. Instead, the application has to perform the access by using a different Google identity.
You need to manage a third-party application that will run on a Compute Engine instance. Other Compute Engine instances are already running with default configuration. Application installation files are hosted on Cloud Storage. You need to access these files from the new instance without allowing other virtual machines (VMs) to access these files.
What should you do?
- A . Create the instance with the default Compute Engine service account Grant the service account permissions on Cloud Storage.
- B . Create the instance with the default Compute Engine service account Add metadata to the objects on Cloud Storage that matches the metadata on the new instance.
- C . Create a new service account and assig n this service account to the new instance Grant the service account permissions on Cloud Storage.
- D . Create a new service account and assign this service account to the new instance Add metadata to the objects on Cloud Storage that matches the metadata on the new instance.
B
Explanation:
https://cloud.google.com/iam/docs/best-practices-for-using-and-managing-service-accounts
If an application uses third-party or custom identities and needs to access a resource, such as a BigQuery dataset or a Cloud Storage bucket, it must perform a transition between principals. Because Google Cloud APIs don’t recognize third-party or custom identities, the application can’t propagate the end-user’s identity to BigQuery or Cloud Storage. Instead, the application has to perform the access by using a different Google identity.
You need to manage a third-party application that will run on a Compute Engine instance. Other Compute Engine instances are already running with default configuration. Application installation files are hosted on Cloud Storage. You need to access these files from the new instance without allowing other virtual machines (VMs) to access these files.
What should you do?
- A . Create the instance with the default Compute Engine service account Grant the service account permissions on Cloud Storage.
- B . Create the instance with the default Compute Engine service account Add metadata to the objects on Cloud Storage that matches the metadata on the new instance.
- C . Create a new service account and assig n this service account to the new instance Grant the service account permissions on Cloud Storage.
- D . Create a new service account and assign this service account to the new instance Add metadata to the objects on Cloud Storage that matches the metadata on the new instance.
B
Explanation:
https://cloud.google.com/iam/docs/best-practices-for-using-and-managing-service-accounts
If an application uses third-party or custom identities and needs to access a resource, such as a BigQuery dataset or a Cloud Storage bucket, it must perform a transition between principals. Because Google Cloud APIs don’t recognize third-party or custom identities, the application can’t propagate the end-user’s identity to BigQuery or Cloud Storage. Instead, the application has to perform the access by using a different Google identity.
You are planning to move your company’s website and a specific asynchronous background job to
Google Cloud Your website contains only static HTML content The background job is started through an HTTP endpoint and generates monthly invoices for your customers. Your website needs to be available in multiple geographic locations and requires autoscaling. You want to have no costs when your workloads are not In use and follow recommended practices.
What should you do?
- A . Move your website to Google Kubemetes Engine (GKE). and move your background job to Cloud Functions
- B . Move both your website and background job to Compute Engine
- C . Move both your website and background job to Cloud Run.
- D . Move your website to Google Kubemetes Engine (GKE), and move your background job to Compute Engine
C
Explanation:
The critical constraint for both the website and the background job is the requirement for autoscaling and no costs when not in use (scale to zero). Both workloads are suitable for containerization and HTTP invocation.
Cloud Run is the single best platform for both use cases under these constraints. It is serverless, fully managed, and natively supports scaling to zero when a containerized service is not receiving requests, making it the most cost-effective option for sporadic workloads.
The static website can run in a simple web server container on Cloud Run. The HTTP-triggered background job is a perfect fit for a Cloud Run service that runs, performs its work (invoice generation), and then scales down to zero.
Reference: Google Cloud Documentation – Cloud Run (Overview):
"Because Cloud Run is serverless… It scales up or down automatically, including scaling to zero to minimize your cost."
Reference: Google Cloud Documentation – Cloud Run (Use cases):
"Cloud Run is suitable for… background processing (jobs, batch processing, and other non-HTTP services), and services that require scaling to zero."
You are planning to move your company’s website and a specific asynchronous background job to
Google Cloud Your website contains only static HTML content The background job is started through an HTTP endpoint and generates monthly invoices for your customers. Your website needs to be available in multiple geographic locations and requires autoscaling. You want to have no costs when your workloads are not In use and follow recommended practices.
What should you do?
- A . Move your website to Google Kubemetes Engine (GKE). and move your background job to Cloud Functions
- B . Move both your website and background job to Compute Engine
- C . Move both your website and background job to Cloud Run.
- D . Move your website to Google Kubemetes Engine (GKE), and move your background job to Compute Engine
C
Explanation:
The critical constraint for both the website and the background job is the requirement for autoscaling and no costs when not in use (scale to zero). Both workloads are suitable for containerization and HTTP invocation.
Cloud Run is the single best platform for both use cases under these constraints. It is serverless, fully managed, and natively supports scaling to zero when a containerized service is not receiving requests, making it the most cost-effective option for sporadic workloads.
The static website can run in a simple web server container on Cloud Run. The HTTP-triggered background job is a perfect fit for a Cloud Run service that runs, performs its work (invoice generation), and then scales down to zero.
Reference: Google Cloud Documentation – Cloud Run (Overview):
"Because Cloud Run is serverless… It scales up or down automatically, including scaling to zero to minimize your cost."
Reference: Google Cloud Documentation – Cloud Run (Use cases):
"Cloud Run is suitable for… background processing (jobs, batch processing, and other non-HTTP services), and services that require scaling to zero."