
Practice Free GES-C01 Exam Online Questions
An enterprise is deploying a new RAG application using Snowflake Cortex Search on a large dataset of customer support tickets. The operations team is concerned about managing compute costs and ensuring efficient index refreshes for the Cortex Search Service, which needs to be updated hourly.
Which of the following considerations and configurations are relevant for optimizing cost and performance of the Cortex Search Service in this scenario?
- A . The
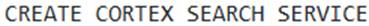
command requires specifying a dedicated virtual warehouse for materializing search results during initial creation and subsequent refreshes. - B . For embedding text, selecting a model like

cost per million tokens, assuming English-only content is sufficient. - C . For optimal performance and cost efficiency, Snowflake recommends using a dedicated warehouse of size no larger than MEDIUM for each Cortex Search Service.
- D . CHANGE_TRACKING must be explicitly enabled on the source table for the Cortex Search Service to leverage incremental refreshes and avoid full re-indexing, thus optimizing refresh costs.
- E . The primary cost driver for Cortex Search is the number of search queries executed against the service, with the volume of indexed data (GBImonth) having a minimal impact on overall billing.
A,B,C,D
Explanation:
Option A is correct because a Cortex Search Service requires a virtual warehouse to refresh the service, which runs queries against base objects when they are initialized and refreshed, incurring compute costs.
Option B is correct because the cost of embedding models varies.
For example, ‘snowflake-arctic-embed-m-vl .5 costs 0.03 credits per million tokens, while ‘voyage-multilingual-2 costs 0.07 credits per million tokens. Choosing a more cost-effective model like ‘snowflake-arctic-embed-m-vl for English-only data can reduce token costs.
Option C is correct because Snowflake recommends using a dedicated warehouse of size no larger than MEDIUM for each Cortex Search Service to achieve optimal performance.
Option D is correct because change tracking is required for the Cortex Search Service to be able to detect and process updates to the base table, enabling incremental refreshes that are more efficient than full re-indexing.
Option E is incorrect because Cortex Search Services incur costs based on virtual warehouse compute for refreshes, ‘EMBED TEXT TOKENS’ cost per input token, and a charge of 6.3 Credits per GB/mo of indexed data. The volume of indexed data has a significant impact, not minimal.
A data engineer is building an AI data pipeline to automatically extract specific sentiment categories from customer reviews using ‘AI_COMPLETE. They want the output to be a structured JSON object containing ‘food_quality’, ‘food_taste’, ‘wait_time’, and ‘food cost’ with their respective sentiments (e.g., ‘positive’, ‘negative’, ‘neutral’). The engineer aims for high accuracy and ensures that all these fields are present in the output.
Which of the following statements correctly describe the approach to achieve this?
- A . The ‘response_format’ argument in ‘AI COMPLETE should specify a JSON schema, and to ensure all fields are present, the ‘required’ field must be explicitly set for all desired properties in the schema.
- B . For optimal accuracy in structured output, it is always best to explicitly instruct the LLM within the prompt to ‘Respond in JSON’ and provide a detailed description of the schema, regardless of task complexity.
- C . When using OpenAl (GPT) models for structured output, the ‘additionalPropertieS field must be set to ‘true’ in every node of the schema to allow for flexibility in the generated JSON.
- D . To improve accuracy, the JSON schema should include detailed descriptions for each field (e.g., ‘food_quality’, ‘food_taste’) to guide the model more precisely in identifying and extracting the sentiments.
- E . The ‘temperature’ option should be set to a high value (e.g., 0.9) in the ‘CompleteOptionS to encourage the model to strictly adhere to the specified JSON schema and reduce non-deterministic responses.
A,D
Explanation:
Option A is correct. The argument is used to supply a JSON schema that completion responses must follow, and including the ‘required’ field in the schema ensures that specified fields are present in the output, with raising an error if a required field cannot be extracted.
Option B is incorrect. While prompting the model to ‘Respond in JSON’ can improve accuracy for complex tasks, it is not always necessary for simple tasks, as ‘AI_COMPLETE Structured OutputS already understands that its response should conform to the specified schema.
Option C is incorrect. For OpenAl (GPT) models, the ‘additionalPropertieS field must be set to ‘false’ in every node of the schema.
Option D is correct. Providing detailed descriptions of the fields to be extracted helps the model more accurately identify them, thereby improving the quality of the structured output.
Option E is incorrect. For the most consistent results, it is recommended to set the ‘temperature’ option to 0 when calling ‘COMPLETE (or regardless of the task or model, to make the output more deterministic and focused.

A)
![]()
B)
![]()
C)
![]()
D)
![]()
E)
![]()
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
A,B,C,D,E
Explanation:

A data engineering team is building an automated pipeline in Snowflake to process customer reviews. They need to use AI_COMPLETE to extract specific details like product, sentiment, and issue type, and store them in a strictly defined JSON format for seamless downstream integration. They aim to maximize the accuracy of the structured output and manage potential model limitations.
Which statements accurately reflect the best practices and characteristics when using AI_COMPLETE with structured outputs for this scenario?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
B,C,E
Explanation:
Option A is incorrect because Structured Outputs do not incur additional compute cost for the overhead of verifying each AI_COMPLETE token against the supplied JSON schema, though the number of tokens processed (and thus billed) can increase with schema complexity.
Option B is correct because for complex reasoning tasks, it is recommended to use the most powerful models and explicitly add ‘Respond in JSON’ to the prompt to optimize accuracy.
Option C is correct as for OpenAI (GPT) models, the schema has specific requirements: response_format must be set to in every node, and the field must include the names of every property in the schema.
Option D additional Properties false required is incorrect because verifies each generated token against the JSON schema to ensure conformity, and if the model cannot generate a AI_COMPLETE response that matches the schema, it will result in a validation error.
Option E is correct as setting the option to e is recommended for temperature the most consistent results, regardless of the task or model, especially for structured outputs.
A data application developer is using the Snowflake Cortex COMPLETE function to power a multi-turn conversational AI application. They want to ensure responses are creative but not excessively long, adhere to a specific JSON structure, and are filtered for safety. Given the following SQL query snippet, which statements accurately describe the impact of the specified options?
- A . Setting

will make the model’s output highly deterministic and focused on the most probable tokens, reducing creativity. - B . The
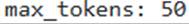
setting ensures that the generated response will not exceed 50 tokens, potentially leading to truncated but concise answers. - C . The
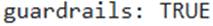
option, powered by Cortex Guard, will filter out potentially unsafe or harmful content from the LLM’s response, preventing it from being returned to the application. - D . Including a with a JSON schema will enforce the LLM to return a response that strictly conforms to the defined structure, and this functionality works for all models supported by AI_COMPLETE.
- E . For a multi-turn conversation, previous user prompts and model responses should be passed in the
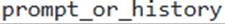
array to maintain state, but this will not impact the cost per round.
B,C,D
Explanation:
Option A is incorrect because a higher temperature, such as 0.8, controls the randomness of the output by influencing which possible token is chosen at each step, resulting in more diverse and random output, not deterministic and focused.
Option B is correct because the ‘max_tokens’ option sets the maximum number of output tokens in the response, and small values can result in truncated responses.
Option C is correct because the ‘guardrails: TRUE option enables Cortex Guard to filter potentially unsafe and harmful responses from a language model.
Option D is correct because AI_COMPLETE Structured Outputs allows you to supply a JSON schema that completion responses must follow, and every model supported by AI_COMPLETE supports structured output.
Option E is incorrect because to provide a stateful conversational experience, all previous user prompts and model responses should be passed in the ‘prompt_or_history’ array, but the number of tokens processed increases for each round, and costs increase proportionally. The ‘COMPLETE’ function is the older version of ‘AI_COMPLETE’.
An enterprise is deploying a new RAG application using Snowflake Cortex Search on a large dataset of customer support tickets. The operations team is concerned about managing compute costs and ensuring efficient index refreshes for the Cortex Search Service, which needs to be updated hourly.
Which of the following considerations and configurations are relevant for optimizing cost and performance of the Cortex Search Service in this scenario?
- A . The CREATE CORTEX SEARCH SERVICE command requires specifying a dedicated virtual warehouse for materializing search results during initial creation and subsequent refreshes.
- B . For embedding text, selecting a model like

cost per million tokens, assuming English-only content is sufficient. - C . For optimal performance and cost efficiency, Snowflake recommends using a dedicated warehouse of size no larger than MEDIUM for each Cortex Search Service.
- D . CHANGE_TRACKING must be explicitly enabled on the source table for the Cortex Search Service to leverage incremental refreshes and avoid full re-indexing, thus optimizing refresh costs.
- E . The primary cost driver for Cortex Search is the number of search queries executed against the service, with the volume of indexed data (GB/month) having a minimal impact on overall billing.
A,B,C,D
Explanation:
Option A is correct because a Cortex Search Service requires a virtual warehouse to refresh the service, which runs queries against base objects when they are initialized and refreshed, incurring compute costs.
Option B is correct because the cost of embedding models varies .
For example, ‘snowflake-arctic-embed-m-v1.5 costs 0.03 credits per million tokens, while ‘voyage-multilingual-2 costs 0.07 credits per million tokens. Choosing a more cost-effective model like ‘snowflake-arctic-embed-m-v1.5’ for English-only data can reduce token costs.
Option C is correct because Snowflake recommends using a dedicated warehouse of size no larger than MEDIUM for each Cortex Search Service to achieve optimal performance.
Option D is correct because change tracking is required for the Cortex Search Service to be able to detect and process updates to the base table, enabling incremental refreshes that are more efficient than full re-indexing.
Option E is incorrect because Cortex Search Services incur costs based on virtual warehouse compute for refreshes, ‘EMBED_TEXT_TOKENS’ cost per input token, and a charge of 6.3 Credits per GB/mo of indexed data. The volume of indexed data has a significant impact, not minimal.
A data engineering team is onboarding a new client whose workflow involves extracting critical financial data from thousands of daily scanned PDF receipts. They decide to use Snowflake Document AI and store all incoming PDFs in an internal stage name.
After deploying their pipeline, they observe intermittent failures and varying error messages in the output, specifically:

Which two of the following actions are most likely required to resolve these processing errors?
- A . Ensure the internal stage is configured with ‘ENCRYPTION = (TYPE = ‘SNOWFLAKE_SSE’)’.
- B . Split any PDF documents exceeding 125 pages into smaller, compliant files, or reject them if splitting is not feasible.
- C . Increase the ‘max_tokens’ parameter within the ‘ !PREDICT function options to accommodate longer document processing.
- D . Change the virtual warehouse size from an X-Small to a Large to improve Document AI processing speed.
- E . Grant the ‘SNOWFLAKE.CORTEX_USER database role to the role executing the ‘!PREDICT function.
A,B
Explanation:
The first error message, ‘cannot identify image file’, is a known error that occurs when an internal stage used for Document AI is not configured with ‘SNOWFLAKE_SSE encryption. Therefore, option A is a direct solution. The second error message, ‘Document has too many pages. Actual: 130. Maximum: 125.’, indicates that some documents exceed Document AI’s page limit of 125 pages per document.
Option B directly addresses this limitation.
Option C is incorrect because ‘max_tokens’ is relevant for LLM output length, not document input page/size limits.
Option D is incorrect because scaling up the warehouse for Document AI does not increase query processing speed and is not recommended for cost efficiency; X-Small, Small, or Medium warehouses are typically sufficient for Document AI.
Option E is incorrect because is the required database role for Document AI, not ‘SNOWFLAKE.CORTEX_USER’.
A data engineering team is setting up an automated pipeline to extract information from new invoices using Document AI. They’ve created a database and schema Cinvoice_db.invoice_schema’) and a Document AI model build They then created an internal stage for documents. When they attempt to run the method on documents uploaded to ‘invoice_stage’, they consistently receive the following error:
![]()
Given this error message, which ‘corrective SQL command’ addresses the most likely misconfiguration of the ‘invoice_stage’ to allow Document AI processing?
A)
![]()
B)
![]()
C)
![]()
D)
![]()
E)
![]()
- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
C
Explanation:

A data science team is implementing a large-scale Retrieval Augmented Generation (RAG) application on Snowflake, using ‘SNOWFLAKE.CORTEX.EMBED TEXT 1024’ to process millions of customer support tickets for semantic search. The goal is to achieve high retrieval quality and manage costs effectively.
Which of the following are recommended practices and accurate cost/performance considerations when leveraging ‘EMBED TEXT 1024’ in this scenario? (Select all that apply)
- A . To minimize compute costs, the team should use a Snowpark-optimized warehouse for operations, as it is specifically designed for ML workloads.
- B . For ‘EMBED_TEXT 1024’, billing is based on both input and output tokens, encouraging brevity in generated embeddings to control costs.
- C . Even with models like ‘snowflake-arctic-embed-l-v2.0-8k’ which have a large context window (8192 tokens), splitting customer support tickets into chunks of no more than 512 tokens is recommended for optimal RAG retrieval quality.
- D . The function should be called using ‘TRY_COMPLETE instead of directly to handle potential errors gracefully and avoid incurring costs for failed operations.
- E . Models for such as ‘snowflake-arctic-embed-l-v2.0’ and ‘multilingual-e5-large’, are billed at 0.05 Credits per one million input tokens processed.
C,E
Explanation:
Option C is correct. For best search results with Cortex Search and RAG, Snowflake recommends splitting the text into chunks of no more than 512 tokens. This practice typically results in higher retrieval and downstream LLM response quality, even for models with larger context windows like ‘snowflake-arctic-embed-l-v2.0-8k’ (8192 tokens).
Option E is correct. For functions, only ‘input tokens’ are counted towards the billable total. The ‘snowflake-arctic-embed-l-v2.0′ and ‘multilingual-e5-large’ models for are indeed billed at 0.05 Credits per one million tokens.
Option A is incorrect because Snowflake recommends executing queries that call Cortex AISQL functions, including ‘EMBED_TEXT 1024’, with a smaller warehouse (no larger than MEDIUM), as larger warehouses do not increase performance for these functions. Snowpark-optimized warehouses are generally for ML training workloads with large memory requirements.
Option B is incorrect because for ‘ functions, ‘only input tokens’ are counted towards the billable total, not output tokens.
Option D is incorrect. ‘TRY COMPLETE is a helper function designed for the ‘COMPLETE function to return NULL on error instead of raising one, thus avoiding cost for failed ‘COMPLETE’ operations. There is no equivalent function mentioned in the sources, and ‘EMBED TEXT 1024s is distinct from ‘COMPLETE’.
A Streamlit application developer wants to use AI_COMPLETE (the latest version of COMPLETE (SNOWFLAKE.CORTEX)) to process customer feedback. The goal is to extract structured information, such as the customer’s sentiment, product mentioned, and any specific issues, into a predictable JSON format for immediate database ingestion.
Which configuration of the AI_COMPLETE function call is essential for achieving this structured output requirement?

- A . Option A
- B . Option B
- C . Option C
- D . Option D
- E . Option E
C
Explanation:
‘AI_COMPLETE Structured OutputS (and its predecessor ‘COMPLETE Structured OutputS) specifically allows supplying a JSON schema as the ‘response_format’ argument to ensure completion responses follow a predefined structure. This significantly reduces the need for post-processing in AI data pipelines and enables seamless integration with systems requiring deterministic responses. The JSON schema object defines the structure, data types, and constraints, including required fields. For complex tasks, prompting the model to respond in JSON can improve accuracy, but the ‘response_format’ argument is the direct mechanism for enforcing the schema. Setting ‘temperature to 0 provides more consistent results for structured output tasks.
Option A is a form of prompt engineering, which can help but does not guarantee strict adherence as ‘response_format does.
Option B controls randomness and length, not output structure.
Option D, while ‘AI_EXTRACT (or EXTRACT ANSWER) can extract information, using it multiple times and then manually combining results is less efficient and less robust than a single ‘AI_COMPLETE call with a structured output schema for multiple related fields.
Option E’s ‘guardrails’ are for filtering unsafe or harmful content, not for enforcing output format.