
Practice Free MuleSoft Platform Architect I Exam Online Questions
A company is using an on-prem cluster in the data center as a runtime plane and MuleSoft-hosted control plane.
How can the company monitor the detailed performance metrics on the Mule applications deployed to the cluster from the control plane?
- A . The settings of the Monitoring section in the control plane must be updated to enable detailed logging on the metrics to be captured
- B . Monitoring Agent must be installed on each node in the cluster
- C . Due to the potential performance impact on the runtime nodes, the Monitoring agent should be installed on a separate server
- D . There is no action needed as the on-prem runtime automatically sends the performance data to the control plane
B
Explanation:
Monitoring On-Premise Mule Applications:
For Mule applications deployed on an on-premises cluster, monitoring detailed performance metrics requires communication with the MuleSoft-hosted control plane. The control plane, when used with on-premises runtimes, relies on Anypoint Monitoring and requires a Monitoring Agent to gather and send detailed performance metrics.
Setting Up Monitoring:
To enable detailed metrics, the Monitoring Agent must be installed on each node in the cluster where Mule applications are deployed. This agent collects data on memory usage, CPU load, response times, and other metrics, and sends it to the control plane for aggregation and visualization.
Evaluating the Options:
Option A: Updating settings in the control plane alone does not enable detailed monitoring; the agent must be installed on each node to capture detailed metrics.
Option B (Correct Answer): Installing the Monitoring Agent on each node ensures that each runtime node in the cluster can send its metrics to the control plane, enabling detailed monitoring.
Option C: Installing the agent on a separate server would not be effective, as each node in the cluster needs to independently report its metrics to ensure full visibility.
Option D: The on-prem runtime does not automatically send detailed metrics to the control plane
without the Monitoring Agent installed.
Conclusion:
Option B is the correct answer, as installing the Monitoring Agent on each node is essential for detailed performance monitoring of on-prem applications in a cluster.
Refer to MuleSoft’s documentation on configuring Anypoint Monitoring for on-premises deployments and using the Monitoring Agent.
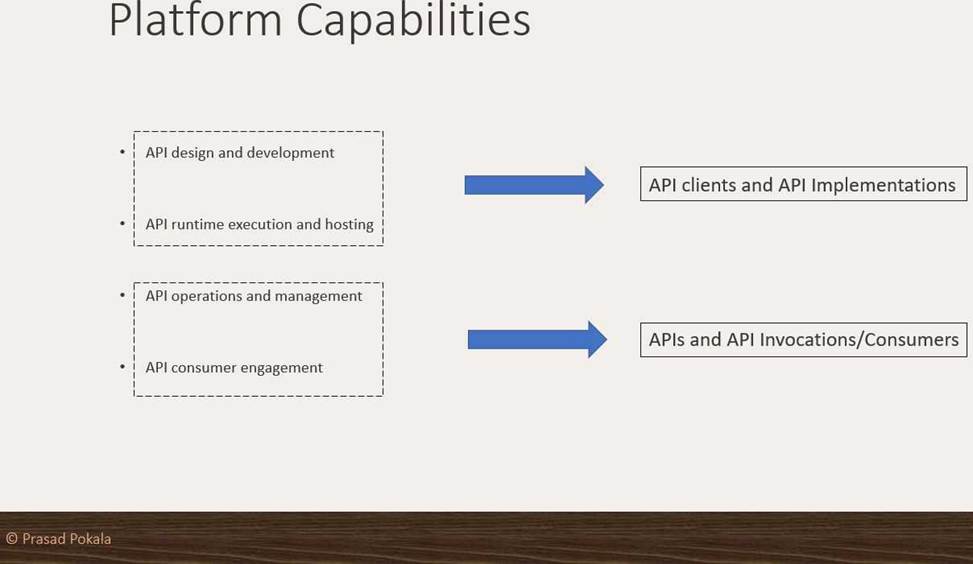
What are 4 important Platform Capabilities offered by Anypoint Platform?
- A . API Versioning, API Runtime Execution and Hosting, API Invocation, API Consumer Engagement
- B . API Design and Development, API Runtime Execution and Hosting, API Versioning, API Deprecation
- C . API Design and Development, API Runtime Execution and Hosting, API Operations and Management, API Consumer Engagement
- D . API Design and Development, API Deprecation, API Versioning, API Consumer Engagement
C
Explanation:
Correct Answer API Design and Development, API Runtime Execution and Hosting, API Operations and Management, API Consumer Engagement
>> API Design and Development – Anypoint Studio, Anypoint Design Center, Anypoint Connectors
>> API Runtime Execution and Hosting – Mule Runtimes, CloudHub, Runtime Services
>> API Operations and Management – Anypoint API Manager, Anypoint Exchange
>> API Consumer Management – API Contracts, Public Portals, Anypoint Exchange, API Notebooks
An organization wants to make sure only known partners can invoke the organization’s APIs. To achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API Manager so that only registered partner applications can invoke the organization’s APIs.
In what type of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID Enforcement policy, rather than embedding the policy directly in the application’s JVM?
- A . A Mule 3 application using APIkit
- B . A Mule 3 or Mule 4 application modified with custom Java code
- C . A Mule 4 application with an API specification
- D . A Non-Mule application
D
Explanation:
Correct Answer A Non-Mule application
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
An organization wants to make sure only known partners can invoke the organization’s APIs. To achieve this security goal, the organization wants to enforce a Client ID Enforcement policy in API Manager so that only registered partner applications can invoke the organization’s APIs.
In what type of API implementation does MuleSoft recommend adding an API proxy to enforce the Client ID Enforcement policy, rather than embedding the policy directly in the application’s JVM?
- A . A Mule 3 application using APIkit
- B . A Mule 3 or Mule 4 application modified with custom Java code
- C . A Mule 4 application with an API specification
- D . A Non-Mule application
D
Explanation:
Correct Answer A Non-Mule application
>> All type of Mule applications (Mule 3/ Mule 4/ with APIkit/ with Custom Java Code etc) running on Mule Runtimes support the Embedded Policy Enforcement on them.
>> The only option that cannot have or does not support embedded policy enforcement and must have API Proxy is for Non-Mule Applications.
So, Non-Mule application is the right answer.
An API implementation is being designed that must invoke an Order API, which is known to repeatedly experience downtime.
For this reason, a fallback API is to be called when the Order API is unavailable.
What approach to designing the invocation of the fallback API provides the best resilience?
- A . Search Anypoint Exchange for a suitable existing fallback API, and then implement invocations to this fallback API in addition to the Order API
- B . Create a separate entry for the Order API in API Manager, and then invoke this API as a fallback API if the primary Order API is unavailable
- C . Redirect client requests through an HTTP 307 Temporary Redirect status code to the fallback API whenever the Order API is unavailable
- D . Set an option in the HTTP Requester component that invokes the Order API to instead invoke a fallback API whenever an HTTP 4xx or 5xx response status code is returned from the Order API
A
Explanation:
Correct Answer Search Anypoint exchange for a suitable existing fallback API, and then implement invocations to this fallback API in addition to the order API
>> It is not ideal and good approach, until unless there is a pre-approved agreement with the API
clients that they will receive a HTTP 3xx temporary redirect status code and they have to implement fallback logic their side to call another API.
>> Creating separate entry of same Order API in API manager would just create an another instance of it on top of same API implementation. So, it does NO GOOD by using clone od same API as a fallback API. Fallback API should be ideally a different API implementation that is not same as primary one.
>> There is NO option currently provided by Anypoint HTTP Connector that allows us to invoke a fallback API when we receive certain HTTP status codes in response.
The only statement TRUE in the given options is to Search Anypoint exchange for a suitable existing fallback API, and then implement invocations to this fallback API in addition to the order API.
A Mule application exposes an HTTPS endpoint and is deployed to the CloudHub Shared Worker Cloud. All traffic to that Mule application must stay inside the AWS VPC.
To what TCP port do API invocations to that Mule application need to be sent?
- A . 443
- B . 8081
- C . 8091
- D . 8082
D
Explanation:
Correct Answer 8082
>> 8091 and 8092 ports are to be used when keeping your HTTP and HTTPS app private to the LOCAL VPC respectively.
>> Above TWO ports are not for Shared AWS VPC/ Shared Worker Cloud.
>> 8081 is to be used when exposing your HTTP endpoint app to the internet through Shared LB
>> 8082 is to be used when exposing your HTTPS endpoint app to the internet through Shared LB
So, API invocations should be sent to port 8082 when calling this HTTPS based app.
Reference:
https://docs.mulesoft.com/runtime-manager/cloudhub-networking-guide
https://help.mulesoft.com/s/article/Configure-Cloudhub-Application-to-Send-a-HTTPS-Request-Directly-to-Another-Cloudhub-Application
https://help.mulesoft.com/s/question/0D52T00004mXXULSA4/multiple-http-listerners-on-cloudhub-one-with-port-9090
An organization wants to create a Center for Enablement (C4E). The IT director schedules a series of meetings with IT senior managers.
What should be on the agenda of the first meeting?
- A . Define C4E objectives, mission statement, guiding principles, a
- B . Explore API monetization options based on identified use cases through MuleSoft
- C . A walk through of common-services best practices for logging, auditing, exception handling, caching, security via policy, and rate limiting/throttling via policy
- D . Specify operating model for the MuleSoft Integrations division
A
Explanation:
In the initial meeting for establishing a Center for Enablement (C4E), it’s essential to lay the foundational vision, objectives, and guiding principles for the team. Here’s why this is crucial: Clear Vision and Mission:
Defining the mission statement and objectives at the start ensures alignment within the organization and clarifies the C4E’s role in supporting API-led development and integration practices. Guiding Principles:
Establishing guiding principles will help the C4E maintain consistent practices and strategies across projects. This serves as a framework for decisions and fosters shared understanding among IT leaders and stakeholders.
of Correct Answer (A):
By prioritizing the C4E’s objectives and mission, the organization builds a solid foundation, paving the way for subsequent meetings focused on technical standards, processes, and operating models. of Incorrect Options:
Option B (API monetization) and Option C (common services best practices) are specific topics better
suited for later discussions.
Option D (specifying the operating model) is an important step but typically follows the establishment of the C4E’s objectives and vision. Reference
For more on C4E objectives and foundational setup, refer to MuleSoft’s documentation on establishing a C4E and the roles and mission statements recommended for such initiatives.
Make consumption of assets at the rate of production
Explanation:
Correct Answer
Make consumption of assets at the rate of production
Explanation:
Correct Answer
A retail company with thousands of stores has an API to receive data about purchases and insert it into a single database. Each individual store sends a batch of purchase data to the API about every 30 minutes. The API implementation uses a database bulk insert command to submit all the purchase data to a database using a custom JDBC driver provided by a data analytics solution provider. The API implementation is deployed to a single CloudHub worker. The JDBC driver processes the data into a set of several temporary disk files on the CloudHub worker, and then the data is sent to an analytics engine using a proprietary protocol. This process usually takes less than a few minutes. Sometimes a request fails. In this case, the logs show a message from the JDBC driver indicating an out-of-file-space message. When the request is resubmitted, it is successful.
What is the best way to try to resolve this throughput issue?
- A . se a CloudHub autoscaling policy to add CloudHub workers
- B . Use a CloudHub autoscaling policy to increase the size of the CloudHub worker
- C . Increase the size of the CloudHub worker(s)
- D . Increase the number of CloudHub workers
D
Explanation:
Correct Answer Increase the size of the CloudHub worker(s)
The key details that we can take out from the given scenario are:
>> API implementation uses a database bulk insert command to submit all the purchase data to a database
>> JDBC driver processes the data into a set of several temporary disk files on the CloudHub worker
>> Sometimes a request fails and the logs show a message indicating an out-of-file-space message Based on above details:
>> Both auto-scaling options does NOT help because we cannot set auto-scaling rules based on error messages. Auto-scaling rules are kicked-off based on CPU/Memory usages and not due to some given error or disk space issues.
>> Increasing the number of CloudHub workers also does NOT help here because the reason for the failure is not due to performance aspects w.r.t CPU or Memory. It is due to disk-space.
>> Moreover, the API is doing bulk insert to submit the received batch data.
Which means, all data is handled by ONE worker only at a time. So, the disk space issue should be tackled on "per worker" basis. Having multiple workers does not help as the batch may still fail on any worker when disk is out of space on that particular worker.
Therefore, the right way to deal this issue and resolve this is to increase the vCore size of the worker so that a new worker with more disk space will be provisioned.